这一章主要讲的是数据库更底层的一些东西。
In order to tune a storage engine to perform well on your kind of workload, you need to have a rough idea of what the storage engine is doing under the hood.
Data Structures That Power Your Database
Index
Any kind of index usually slows down writes, because the index also needs to be updated every time data is written.
This is an important trade-off in storage systems: well-chosen indexes speed up read queries, but every index slows down writes.
所以在默认情况下,数据库不会对所有 key 都建立索引,一般都由应用的开发者来确定。
Hash Index
以最简单的方式实现一个 key-value store, 每次 Put 就是在数据文件后面追加,每次 Get 就依次遍历数据文件寻找对应数据。
遍历寻找数据太慢了,所以我们可以为这个简单的数据库增加索引,即在内存中维护一个 Hashmap,key 为键值对的键,value 为该键值对在数据文件中的字节偏移值。
Whenever you append a new key-value pair to the file, you also update the hash map to reflect the offset of the data you just wrote (this works both for inserting new keys and for updating existing keys).
在这种情况下,无论新增还是修改,都是在文件末尾追加。
A storage engine like Bitcask is well suited to situations where the value for each key is updated frequently.
文件太大后自然需要压缩:
Compaction means throwing away duplicate keys in the log, and keeping only the most recent update for each key.

我们自然地可以将整个数据文件分为一个个大小固定的文件,当一个文件写满之后,就去写下一个文件,如果文件数量过多,就可以另起一个线程去压缩合并。由于只是在生成新文件,所以压缩合并的同时也可以依旧进行查询,压缩完成后,再用新文件去替换旧文件。
在实现这个简单的 key-value store 时有几点需要注意:
- Crash recovery
- If the database is restarted, the in-memory hash maps are lost. Bitcask speeds up recovery by storing a snapshot of each segment’s hash map on disk, which can be loaded into memory more quickly.
- Partially written records
- The database may crash at any time, including halfway through appending a record to the log. Bitcask files include checksums, allowing such corrupted parts of the log to be detected and ignored.
- Concurrency control
- As writes are appended to the log in a strictly sequential order, a common implementation choice is to have only one writer thread.
Append-only 模式也有自己的优点:
- Appending and segment merging are sequential write operations, which are generally much faster than random writes, especially on magnetic spinning-disk hard drives.
- Concurrency and crash recovery are much simpler if segment files are appendonly or immutable.
- Merging old segments avoids the problem of data files getting fragmented over time.
缺点也有:
- The hash table must fit in memory.
- Range queries are not efficient.
- 只能遍历整个 Hashmap
SSTables and LSM-Trees
我们对上文提到的数据文件做一点小小的改进:要求所有的键值对都以键来排序,这种格式就是 Sorted String Table (SSTable).
SSTable’s advantages over log segments with hash index:
- Merging segments is simple and efficient, even if the files are bigger than the available memory.
- 合并两个有序的列表只需要 $O(n)$ 的时间复杂度
- 并且可以在外部使用归并排序
- In order to find a particular key in the file, you no longer need to keep an index of all the keys in memory. This is called a sparse-index, which will significantly reduce the table size.
- 由于记录的键是有序的,我们可以每隔一定间隔记录一个,寻找某个记录时,根据它的键去遍历一个小区间就行
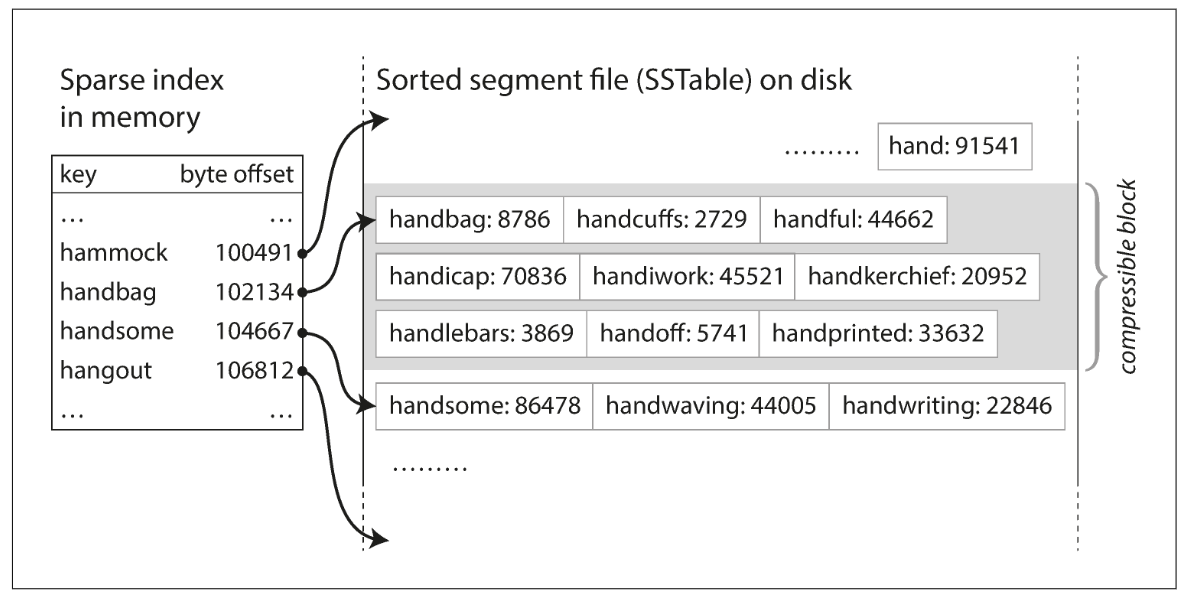
- Since read requests need to scan over several key-value pairs in the requested range anyway, it is possible to group those records into a block and compress it before writing it to disk.
数据文件中的记录是有序的,在写入数据时,我们肯定不能每次直接往文件中写入,而是应该先在内存中处理,到达一定大小后再写入到文件中。
We can now make our storage engine work as follows:
- When a write comes in, add it to an in-memory balanced tree data structure (for example, a red-black tree). This in-memory tree is sometimes called a memtable.
- When the memtable gets bigger than some threshold—typically a few megabytes — write it out to disk as an SSTable file. This can be done efficiently because the tree already maintains the key-value pairs sorted by key. The new SSTable file becomes the most recent segment of the database. While the SSTable is being written out to disk, writes can continue to a new memtable instance.
- In order to serve a read request, first try to find the key in the memtable, then in the most recent on-disk segment, then in the next-older segment, etc.
- From time to time, run a merging and compaction process in the background to combine segment files and to discard overwritten or deleted values.
注意,这样只能保证单个文件内的记录是有序的,而不能在多个文件之间来保证有序性。
当数据库崩溃时,memtable 中的记录也会消失,所以我们可以在磁盘上维护一个 WAL日志,用来记录这个 memtable 的写入情况。
这种算法即是 LSM-Tree 的原型。
The LSM-tree algorithm can be slow when looking up keys that do not exist in the database. In order to optimize this kind of access, storage engines often use additional Bloom filters.
There are also different strategies to determine the order and timing of how SSTables are compacted and merged. The most common options are size-tiered and leveled compaction.
Because the disk writes are sequential the LSM-tree can support remarkably high write throughput.
Summary

Some conventions:
- On-disk
SSTableindexes are always loaded into memory - All writes go directly to the
MemTableindex - Reads check the MemTable first and then the SSTable indexes
- Periodically, the MemTable is flushed to disk as an SSTable
- Periodically, on-disk SSTables are “collapsed together”
对于一个写操作:
- 先向 WAL 日志中写入,再向 memtable 中写入数据。
- 当 memtable 的大小达到一个阈值时,就把整个 memtable 写入到磁盘并清空日志,重新初始化一个 memtable 用于处理后续的写操作。
对于一个读操作:
- 先在 memtable 中查找
- 如果未找到,就按照从新到旧的顺序在 SSTable 文件中查找
- 每个 SSTable 在内存中都有对应的索引,通过索引去找对应的一个小范围,然后遍历磁盘中文件的对应范围,确定数据是否存在
- 如果不存在,就去查找下一个比较旧的 SSTable
分析之后可以发现,由于 key 可能不存在,就会查找多个 SSTable,造成大量极慢的读磁盘的操作。针对每一个 SSTable,除了在内存中维护它的 sparse index, 我们还可以在内存中维护一个 bloom filter, 用于快速确定该 SSTable 中是否包含此数据。
引入此优化后,理想情况下一个读操作只需要一次磁盘读写即可完成。
B-Trees
The most widely used indexing structure is quite different: the B-tree.
By contrast, B-trees break the database down into fixed-size blocks or pages, traditionally 4 KB in size (sometimes bigger), and read or write one page at a time.
In order to make the database resilient to crashes, it is common for B-tree implementations to include an additional data structure on disk: a write-ahead log (WAL, also known as a redo log). This is an append-only file to which every B-tree modification must be written before it can be applied to the pages of the tree itself. When the database comes back up after a crash, this log is used to restore the B-tree back to a consistent state.
Comparing B-Trees and LSM-Trees
As a rule of thumb, LSM-trees are typically faster for writes, whereas B-trees are thought to be faster for reads. Reads are typically slower on LSM-trees because they have to check several different data structures and SSTables at different stages of compaction.
Advantages of LSM-trees
A B-tree index must write every piece of data at least twice: once to the write-ahead log, and once to the tree page itself (and perhaps again as pages are split).
Log-structured indexes also rewrite data multiple times due to repeated compaction and merging of SSTables. This effect — one write to the database resulting in multiple writes to the disk over the course of the database’s lifetime — is known as write amplification. It is of particular concern on SSDs, which can only overwrite blocks a limited number of times before wearing out.
Moreover, LSM-trees are typically able to sustain higher write throughput than B-trees, partly because they sometimes have lower write amplification, and partly because they sequentially write compact SSTable files rather than having to overwrite several pages in the tree.
Since LSM-trees are not page-oriented and periodically rewrite SSTables to remove fragmentation, they have lower storage overheads, especially when using leveled compaction
Downsides of LSM-trees
A downside of log-structured storage is that the compaction process can sometimes interfere with the performance of ongoing reads and writes.
The impact on throughput and average response time is usually small, but at higher percentiles the response time of queries to log-structured storage engines can sometimes be quite high, and B-trees can be more predictable.
If write throughput is high and compaction is not configured carefully, it can happen that compaction cannot keep up with the rate of incoming writes. In this case, the number of unmerged segments on disk keeps growing until you run out of disk space, and reads also slow down because they need to check more segment files.
Keeping everything in memory
Counterintuitively, the performance advantage of in-memory databases is not due to the fact that they don’t need to read from disk. Even a disk-based storage engine may never need to read from disk if you have enough memory, because the operating system caches recently used disk blocks in memory anyway. Rather, they can be faster because they can avoid the overheads of encoding in-memory data structures in a form that can be written to disk.
Besides performance, another interesting area for in-memory databases is providing data models that are difficult to implement with disk-based indexes. For example, Redis offers a database-like interface to various data structures such as priority queues and sets. Because it keeps all data in memory, its implementation is comparatively simple.
Transaction Processing or Analytics?
这一节也很有意思,数据库大体上可以分为两种用途:transaction processing and data analytics.
Transaction processing just means allowing clients to make low-latency reads and writesas opposed to batch processing jobs, which only run periodically (for example, once per day).
An application typically looks up a small number of records by some key, using an index. Records are inserted or updated based on the user’s input. Because these applications are interactive, the access pattern became known as online transaction processing (OLTP).
However, databases also started being increasingly used for data analytics, which has very different access patterns. Usually an analytic query needs to scan over a huge number of records, only reading a few columns per record, and calculates aggregate statistics (such as count, sum, or average) rather than returning the raw data to the user.
In order to differentiate this pattern of using databases from transaction processing, it has been called online analytic processing (OLAP).
两者还是有很大不同的:

Data Warehousing
专门针对数据分析的数据库被叫做数据仓库。
A data warehouse, by contrast, is a separate database that analysts can query to their hearts’ content, without affecting OLTP operations. The data warehouse contains a read-only copy of the data in all the various OLTP systems in the company.

Many data warehouses are used in a fairly formulaic style, known as a star schema (also known as dimensional modeling).
Example:
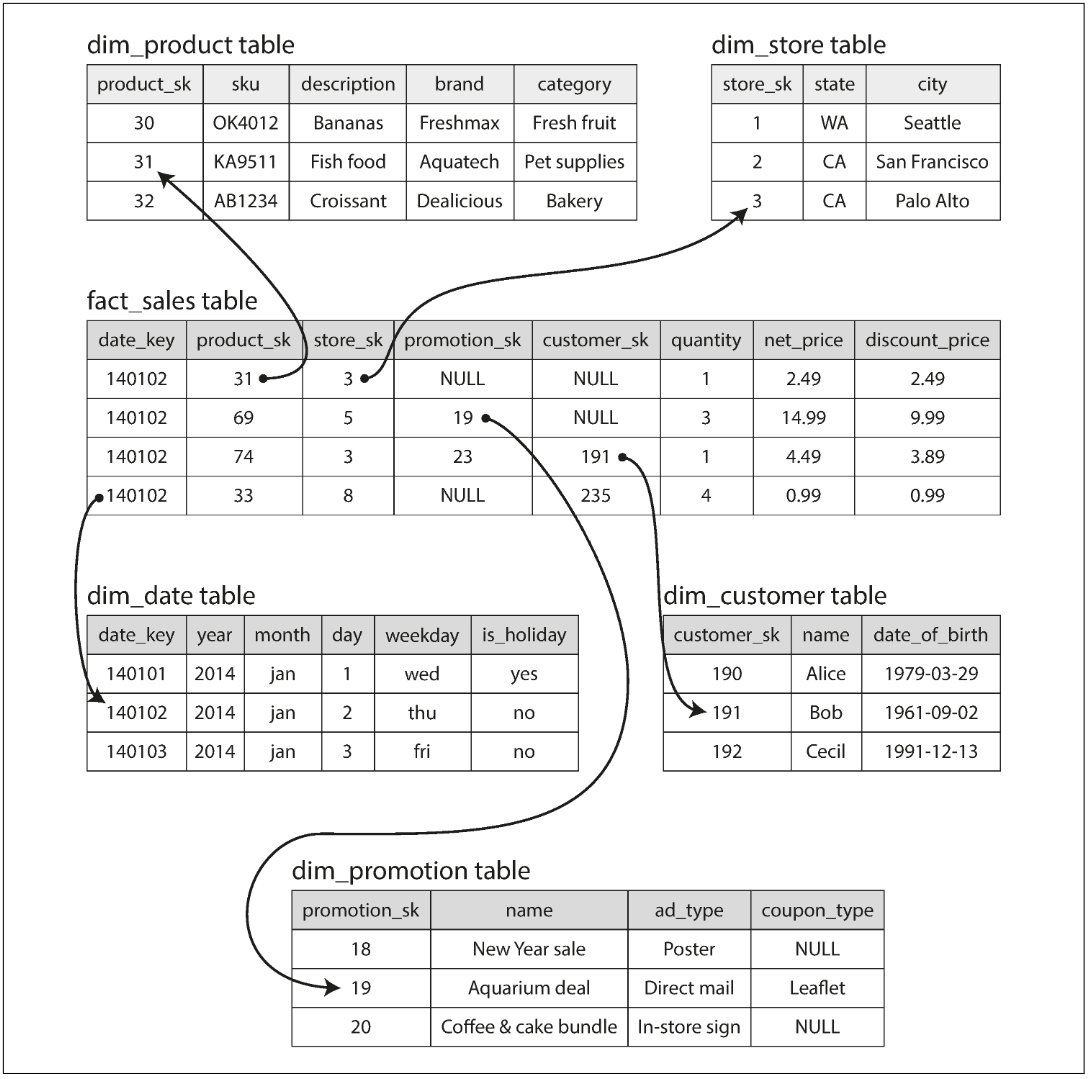
As each row in the fact table represents an event, the dimensions represent the who, what, where, when, how, and why of the event.
The name “star schema” comes from the fact that when the table relationships are visualized, the fact table is in the middle, surrounded by its dimension tables; the connections to these tables are like the rays of a star.
Column-Oriented Storage
数据仓库存储的数据有以下特点:
- 数量多
- Fact table 的列非常多
查询的特点是:
- 查询所有数据
- 只访问其中的几列
In most OLTP databases, storage is laid out in a row-oriented fashion: all the values from one row of a table are stored next to each other. Document databases are similar: an entire document is typically stored as one contiguous sequence of bytes.
The idea behind column-oriented storage is simple: don’t store all the values from one row together, but store all the values from each column together instead. If each column is stored in a separate file, a query only needs to read and parse those columns that are used in that query, which can save a lot of work.
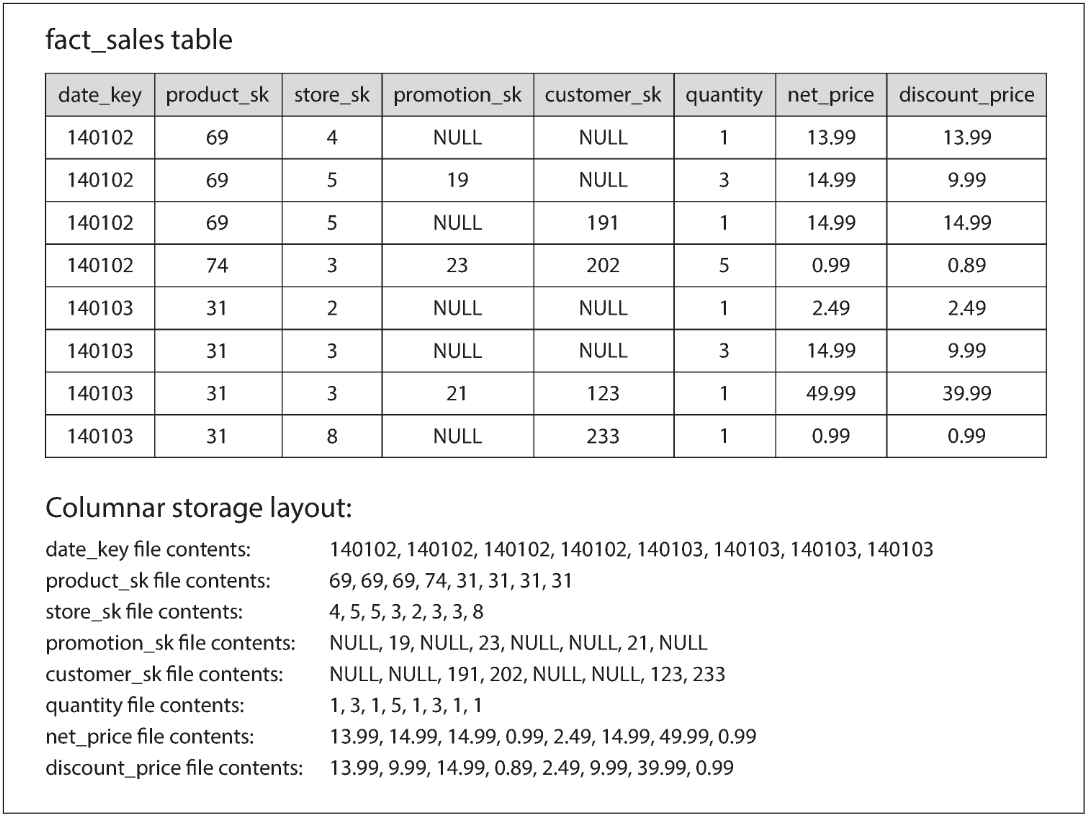
Summary
There are big differences between the access patterns in those use cases:
- OLTP systems are typically user-facing, which means that they may see a huge volume of requests. In order to handle the load, applications usually only touch a small number of records in each query. The application requests records using some kind of key, and the storage engine uses an index to find the data for the requested key. Disk seek time is often the bottleneck here.
- Data warehouses and similar analytic systems are less well known, because they are primarily used by business analysts, not by end users. They handle a much lower volume of queries than OLTP systems, but each query is typically very demanding, requiring many millions of records to be scanned in a short time. Disk bandwidth (not seek time) is often the bottleneck here, and columnoriented storage is an increasingly popular solution for this kind of workload.