Formats for Encoding Data
这里提到了两种兼容性,后面分析数据编码格式时都会用到:
In order for the system to continue running smoothly, we need to maintain compatibility in both directions:
- Backward compatibility
- Newer code can read data that was written by older code.
- Forward compatibility
- Older code can read data that was written by newer code.
直译有一个问题, 英语的"前后"在时间和空间上统一, 而汉语却是相反. 比如 forward 在空间上指前进, 在时间上指未来. 但是汉语中的"前"在空间上指前进, 在时间上却指过去.
向后兼容很好理解:指新的版本的软/硬件可以使用老版本的软/硬件产生的数据。
Forward compatibility 译为向前兼容极容易混乱,这里可以想成向未来兼容:指老的版本的软/硬件可以使用新版本的软/硬件产生的数据。
以下是几个例子:
Intel 的 x86指令集 CPU 是向后兼容的,因为新款 CPU 依然可以运行老版本的软件。Intel 保证老版本 CPU 有的指令集新版本一定还保留着,这种只增加不删除的策略,保证了我们换 CPU 时,不需要更换很多软件。
Windows 操作系统是向后兼容的,大部分针对 Windows 7开发的软件依然可以很好的运行在 Windows 10下。Windows 通过保证系统 API 的稳定不变,只增加不删除的策略,保证了老系统上开发的软件可以很容易的在新系统上运行。
用于设计网页的 HTML 语言是向前兼容的,当旧的浏览器遇到新版本的 HTML 语言时,可以简单的忽略不支持的标签,仍然可以正常显示。
本章主要讲了以下几种数据编码格式:
- JSON
- XML
- Protocol Buffers
- Thrift
- Avro
In particular, we will look at how they handle schema changes and how they support systems where old and new data and code need to coexist.
We need some kind of translation between the two representations. The translation from the in-memory representation to a byte sequence is called encoding (also known as serialization or marshalling), and the reverse is called decoding (parsing, deserialization, unmarshalling).
Language-Specific Formats
Many programming languages come with built-in support for encoding in-memory objects into byte sequences. For example, Java has java.Io.Serializable, Ruby has Marshal, Python has pickle, and so on.
Language-specific formats have a number of deeper problems:
- The encoding is often tied to a particular programming language, and reading the data in another language is very difficult. (有“语言隔离”现象)
- In order to restore data in the same object types, the decoding process needs to be able to instantiate arbitrary classes. (有安全性问题)
- Versioning data is often an afterthought in these libraries. (不具有兼容性, 既不支持向后兼容也不支持向未来兼容)
- Efficiency (CPU time taken to encode or decode, and the size of the encoded structure) is also often an afterthought. (效率不高)
JSON, XML, and Binary Variants
They also have some subtle problems:
- There is a lot of ambiguity around the encoding of numbers.
- JSON and XML have good support for Unicode character strings (i.e., humanreadable text), but they don’t support binary strings (sequences of bytes without a character encoding).
- There is optional schema support for both XML and JSON. Use of XML schemas is fairly widespread, but many JSON-based tools don’t bother using schemas.
An Example of JSON Schema:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/product.schema.json",
"title": "Product",
"description": "A product from Acme's catalog",
"type": "object",
"properties": {
"productId": {
"description": "The unique identifier for a product",
"type": "integer"
},
"productName": {
"description": "Name of the product",
"type": "string"
}
}
}
Binary encoding
For data that is used only internally within your organization, there is less pressure to use a lowest-common-denominator encoding format. For example, you could choose a format that is more compact or faster to parse.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": [
"daydreaming",
"hacking"
]
}
Let’s look at an example of MessagePack, a binary encoding for JSON.

All the binary encodings of JSON are similar in this regard. It’s not clear whether such a small space reduction (and perhaps a speedup in parsing) is worth the loss of human-readability.
Thrift and Protocol Buffers
Thrift 和 Protocol Buffers 都是二进制编码库,它们都需要数据模式 (data schema)来编码数据。
Thrift 的数据模式样例如下:
struct Person {
1: required string userName,
2: optional i64 favoriteNumber,
3: optional list<string> interests
}
Protocol Buffers 的也非常类似:
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
Thrift and Protocol Buffers each come with a code generation tool that takes a schema definition like the ones shown here, and produces classes that implement the schema in various programming languages.
BinaryProtocol In Thrift
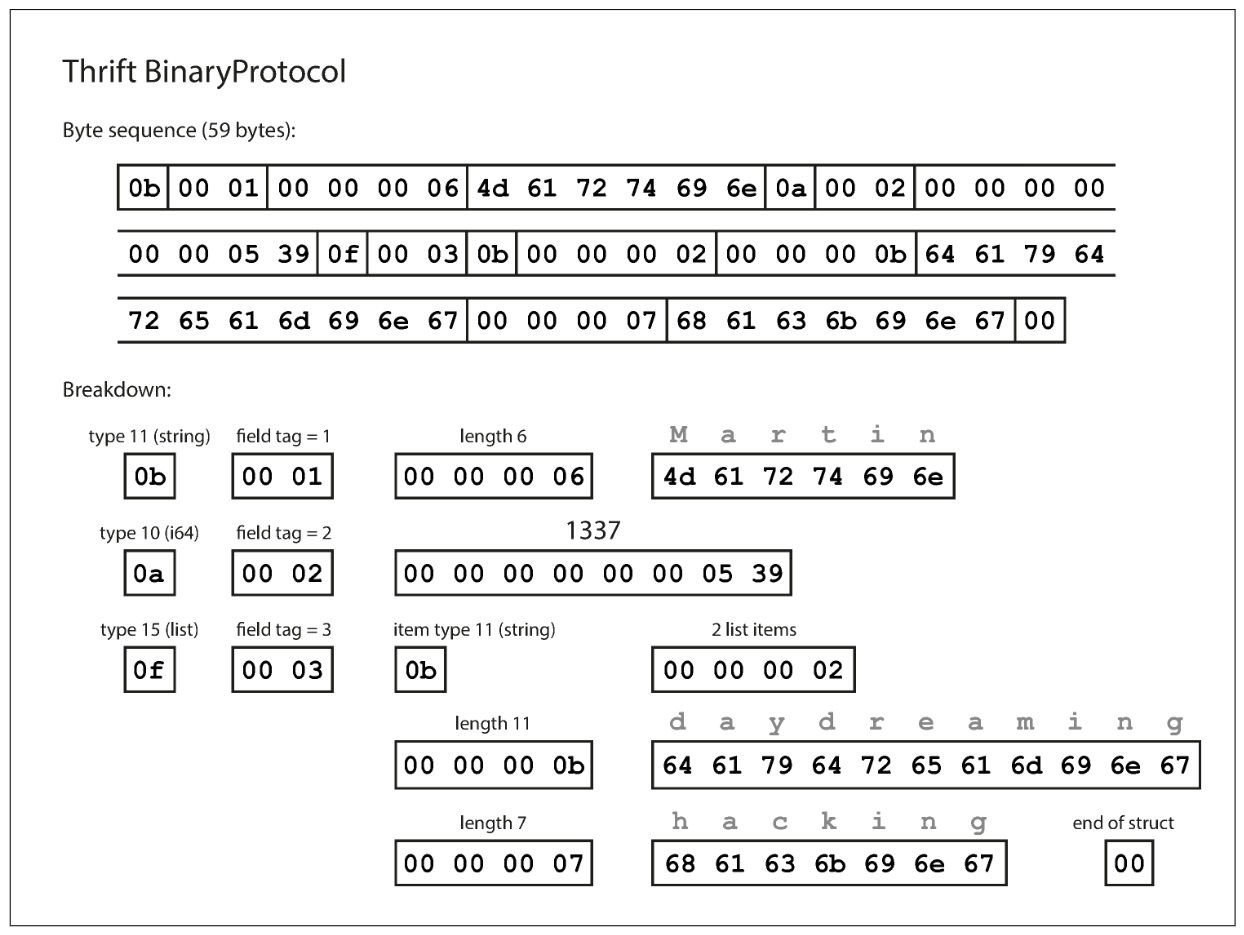
The differece compare to MessagePack is that there are no field names (userName, favoriteNumber, interests). Instead, the encoded data contains field tags, which are numbers (1, 2, and 3). Those are the numbers that appear in the schema definition. Field tags are like aliases for fields—they are a compact way of saying what field we’re talking about, without having to spell out the field name.
CompactProtocol In Thrift
The Thrift CompactProtocol encoding reduces length by packing the field type and tag number into a single byte, and by using variable-length integers.
Rather than using a full eight bytes for the number 1337, it is encoded in two bytes, with the top bit of each byte used to indicate whether there are still more bytes to come.

Protocol Buffers

Summary
总结一下,由于 schema 在数据传输两边的程序中都有一份,所以我们可以将传输的数据中的 field name 换为 field tags,然后再加上可变长度的数字编码,就能最小化字节序列的长度。
现在可以来分析一下 Thrift 和 Protocol Buffers 是如何实现向后兼容以及向未来兼容的。
Background: Schemas inevitably need to change over time.
- Change the name of a field in the schema
- OK, since the encoded data never refers to field names, but field tags.
- Add new fields to the schema
- If old code (which doesn’t know about the new tag numbers you added) tries to read data written by new code, including a new field with a tag number it doesn’t recognize, it can simply ignore that field. (这就实现了向未来兼容,老的版本的软件可以使用新版本的软件产生的数据。)
- If you add a new field, you cannot make it required to maintain backward compatibility.
- Removing a field is just like adding a field, with backward and forward compatibility concerns reversed.
- Remove a field that is optional.
- Never use the same tag number again
Avro
Apache Avro is another binary encoding format. It was started in 2009 as a subproject of Hadoop, as a result of Thrift not being a good fit for Hadoop’s use cases

To parse the binary data, you go through the fields in the order that they appear in the schema and use the schema to tell you the datatype of each field.
This means that the binary data can only be decoded correctly if the code reading the data is using the exact same schema as the code that wrote the data.
How does Avro support schema evolution?
The writer’s schema and the reader’s schema
- When an application wants to encode some data, it uses the schema called the writer’s schema.
- When an application wants to decode some data, it uses the schema called the reader’s schema.
The key idea with Avro is that the writer’s schema and the reader’s schema don’t have to be the same—they only need to be compatible.
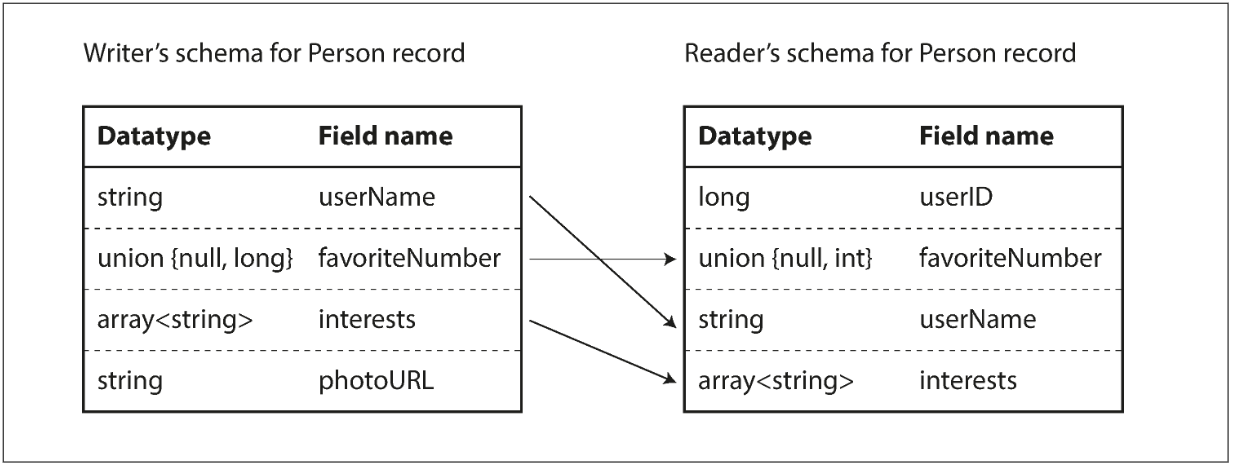
在 Avro 里,
- 向后兼容意味着 a new version of the schema as reader and an old version as writer.(新软件可以读旧数据)
- 向未来兼容意味着 a new version of the schema as writer and an old version as reader.(旧软件可以读新数据)
To maintain compatibility, you may only add or remove a field that has a default value.
如果增加一个没有默认值的属性,新的读者无法从旧数据里获得该值,破坏了向后兼容。如果删除一个没有默认值的属性,旧的读者无法从新数据里获得该值,破坏了向未来兼容。
这里也隐含了一个问题,写者的数据模式放在哪里?
The answer depends on the context in which Avro is being used:
- Large file with lots of records
- The writer of that file can just include the writer’s schema once at the beginning of the file.
- Database with individually written records
- To include a version number at the beginning of every encoded record, and to keep a list of schema versions in your database,
- Sending records over a network connection
- Negotiate the schema version on connection setup and then use that schema for the lifetime of the connection.
Dynamically generated schemas
The difference is that Avro is friendlier to dynamically generated schemas. By contrast, if you were using Thrift or Protocol Buffers for this purpose, the field tags would likely have to be assigned by hand.
Thrift and Protocol Buffers rely on code generation: after a schema has been defined, you can generate code that implements this schema in a programming language of your choice.
The Merits of Schemas
They have a number of nice properties:
- They can be much more compact than the various “binary JSON” variants, since they can omit field names from the encoded data.
- The schema is a valuable form of documentation, and because the schema is required for decoding, you can be sure that it is up to date (whereas manually maintained documentation may easily diverge from reality).
- Keeping a database of schemas allows you to check forward and backward compatibility of schema changes, before anything is deployed.
- For users of statically typed programming languages, the ability to generate code from the schema is useful, since it enables type checking at compile time.
Modes of Dataflow
We will explore some of the most common ways how data flows between processes:
- Via databases
- Via service calls
- Via asynchronous message passing
Dataflow Through Databases
如果与数据库交互时只有一个线程,通常情况下“旧版本”的线程写入数据,“新版本”的线程读入数据。很明显这种情况下,数据库需要维护向后兼容性。(storing something in the database as sending a message to your future self.)
如果有多个线程对数据库进行读写,就会存在旧读者读新数据的情况,所以向未来兼容也是必要的。
The encoding formats discussed previously support such preservation of unknown fields, but sometimes you need to take care at an application level. For example, if you decode a database value into model objects in the application, and later reencode those model objects, the unknown field might be lost in that translation process.
Dataflow Through Services: REST and RPC
REST 比较常见,没啥好说的,这里主要总结一下 RPC。
虽然说 RPC 提供了一层类似于调用本地函数的抽象,但是由于网络请求的独特性,两者还是有本质上的不同:
- 网络请求是不可预测的:请求或者响应可能会丢失,也有可能会变慢。
- 如果网络请求超时了,客户端不能确定到底是服务端崩溃了,还是网络变慢了。
- 如果网络请求超时了,很多情况下客户端都需要重新发送,所以服务端的接口可能要实现幂等性来解决多次发送的问题。
- 客户端和服务端可能不是同一种编程语言,所以 RPC 框架需要在两者之间转换数据结构。
Various RPC frameworks have been built on top of all the encodings mentioned in this chapter:
- Thrift and Avro come with RPC support included.
- gRPC is an RPC implementation using Protocol Buffers.
- Finagle uses Thrift.
- Rest.Li uses JSON over HTTP.
We can make a simplifying assumption in the case of dataflow through services: it is reasonable to assume that all the servers will be updated first, and all the clients second. Thus, you only need backward compatibility on requests, and forward compatibility on responses.
The backward and forward compatibility properties of an RPC scheme are inherited from whatever encoding it uses:
- Thrift, gRPC (Protocol Buffers), and Avro RPC can be evolved according to the compatibility rules of the respective encoding format.
- In SOAP, requests and responses are specified with XML schemas. These can be evolved, but there are some subtle pitfalls.
- RESTful APIs most commonly use JSON (without a formally specified schema) for responses, and JSON or URI-encoded/form-encoded request parameters for requests. Adding optional request parameters and adding new fields to response objects are usually considered changes that maintain compatibility.
Message-Passing Dataflow
Using a message broker has several advantages compared to direct RPC:
- It can act as a buffer if the recipient is unavailable or overloaded, and thus improve system reliability.
- It can automatically redeliver messages to a process that has crashed, and thus prevent messages from being lost.
- It logically decouples the sender from the recipient.
- …
Message brokers
In general, message brokers are used as follows: one process sends a message to a named queue or topic, and the broker ensures that the message is delivered to one or more consumers of or subscribers to that queue or topic. There can be many producers and many consumers on the same topic.