Replication Versus Partitioning
There are two common ways data is distributed across multiple nodes:
- Replication
- Keeping a copy of the same data on several different nodes, potentially in different locations. Replication provides redundancy and can also help improve performance.
- Partitioning
- Splitting a big database into smaller subsets called partitions so that different partitions can be assigned to different nodes (also known as sharding).
These are separate mechanisms, but they often go hand in hand:

Here are several reasons why you might want to replicate data:
- To reduce latency.
- To increase availability.
- To increase read throughput.
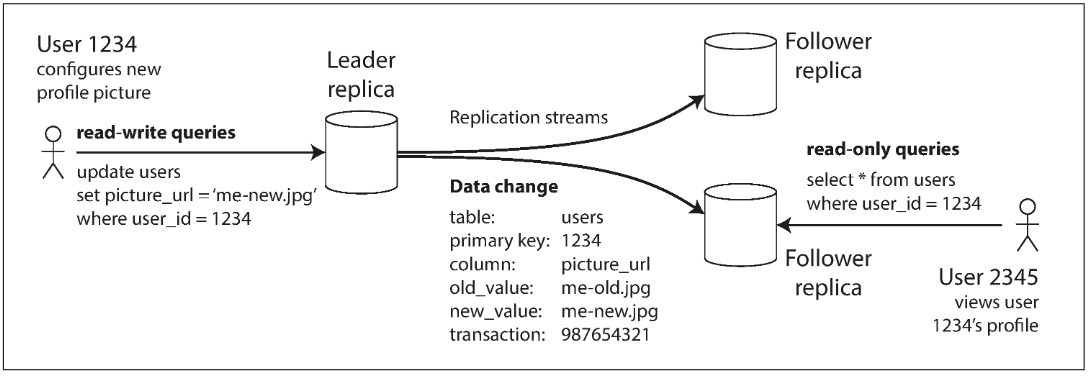
Leaders and Followers
The most common solution for this is called leader-based replication.
Synchronous Versus Asynchronous Replication
An important detail of a replicated system is whether the replication happens synchronously or asynchronously.

- The replication to follower 1 is synchronous
- The replication to follower 2 is asynchronous
By the way,这图更像是在表达 write needs to be agreed on a majority of nodes.
The advantage of synchronous replication is that the follower is guaranteed to have an up-to-date copy of the data that is consistent with the leader.
The disadvantage is that if the synchronous follower doesn’t respond (because it has crashed, or there is a network fault, or for any other reason), the write cannot be processed.
For this reason, it is impractical for all followers to be synchronous. In practice, if you enable synchronous replication on a database, it usually means that one of the followers is synchronous, and the others are asynchronous.
This configuration is sometimes also called semi-synchronous
Completely asynchronous will weaken durability. Weakening durability may sound like a bad trade-off, but asynchronous replication is nevertheless widely used, especially if there are many followers or if they are geographically distributed.
Implementation of Replication Logs
Statement-based replication
In the simplest case, the leader logs every write request (statement) that it executes and sends that statement log to its followers. For a relational database, this means that every INSERT, UPDATE, or DELETE statement is forwarded to followers.
One problem with this approach is that any statement that calls a nondeterministic function, such as NOW() to get the current date and time or RAND() to get a random number, is likely to generate a different value on each replica. (Recall how to solve this problem in vm-ft)
Write-ahead log (WAL) shipping
We can use the exact same log to build a replica on another node which storage engine uses: besides writing the log to disk, the leader also sends it across the network to its followers.
The main disadvantage is that the log describes the data on a very low level: a WAL contains details of which bytes were changed in which disk blocks. This makes replication closely coupled to the storage engine.
If the replication protocol allows the follower to use a newer software version than the leader, you can perform a zero-downtime upgrade of the database software by first upgrading the followers and then performing a failover to make one of the upgraded nodes the new leader.
Logical (row-based) log replication
An alternative is to use different log formats for replication and for the storage engine, which allows the replication log to be decoupled from the storage engine internals.
This kind of replication log is called a logical log, to distinguish it from the storage engine’s (physical) data representation.
A logical log for a relational database is usually a sequence of records describing writes to database tables at the granularity of a row.
Problems with Replication Lag
Leader-based replication requires all writes to go through a single node, but readonly queries can go to any replica. For workloads that consist of mostly reads and only a small percentage of writes (a common pattern on the web), there is an attractive option.
In this read-scaling architecture, you can increase the capacity for serving read-only requests simply by adding more followers.
这种方法只适用于异步复制,但异步复制就会带来数据不一致的问题:用户可能会从副本中读到过时的数据,但是这种不一致只是暂时的(比如可能由网络延迟带来),所有追随者的数据最终会与领导者的数据一致,这种一致性就被称作最终一致性。
You may get different results, because not all writes have been reflected in the follower. This inconsistency is just a temporary state—if you stop writing to the database and wait a while, the followers will eventually catch up and become consistent with the leader. For that reason, this effect is known as eventual consistency.
一致性和性能不能兼得,比如强一致性就要求读写操作都必须经过领导者,我们可以退一步,使用最终一致性,这样就能将读操作分摊到各个副本上。 很多案例都不需要强一致性的,比如各种信息的评论和点赞,慢一点没啥太大影响。
Reading Your Own Writes
Many applications let the user submit some data and then view what they have submitted. With asynchronous replication, there is a problem:

In this situation, we need read-after-write consistency, also known as read-your-writes consistency. This is a guarantee that if the user reloads the page, they will always see any updates they submitted themselves. (It makes no promises about other users)
How to deal
How can we implement read-after-write consistency in a system with leader-based replication?
- When reading something that the user may have modified, read it from the leader; otherwise, read it from a follower.
- Track the time of the last update and, for one minute after the last update, make all reads from the leader.
- The client can remember the timestamp of its most recent write—then the system can ensure that the replica serving any reads for that user reflects updates at least until that timestamp.
- If a replica is not sufficiently up to date:
- The read can be handled by another replica.
- The query can wait until the replica has caught up.
- The timestamp could be a logical timestamp (something like the log sequence number)
- If a replica is not sufficiently up to date:
How about the same user is accessing your service form multiple device?
In this case you may want to provide cross-device read-after-write consistency.
Like collaborate editor? OneNote…
Monotonic Reads
Second example of an anomaly that can occur when reading from asynchronous followers is that it’s possible for a user to see things moving backward in time.
情况如下:对于相同的两次查询,可能会被重定向到两个不同的副本当中,因为使用的是异步复制,所以有可能第一个被访问的副本数据比较新,而第二个副本的数据比较旧,从用户的角度,就会出现第二次查询反而数据变少的情况。

Monotonic reads is a guarantee that this kind of anomaly does not happen. It’s a lesser guarantee than strong consistency, but a stronger guarantee than eventual consistency.
When you read data, you may see an old value, monotonic reads only means that if one user makes several reads in sequence, they will not see time go backward,that is they will not read older data after having previously read newer data.
How to deal
One way of achieving monotonic reads is to make sure that each user always makes their reads from the same replica (different users can read from different replicas).
Summary
- Read-after-write consistency
- Users should always see data that they submitted themselves.
- Monotonic reads
- After users have seen the data at one point in time, they shouldn’t later see the data from some earlier point in time.
- Consistent prefix reads
- Users should see the data in a state that makes causal sense: for example, seeing a question and its reply in the correct order.
Consistent Prefix Reads
Third example of replication lag anomalies concerns violation of causality.
即在逻辑上具有先后顺序的数据在到达时不再具有此关系,或者说,乱序了。

Preventing this kind of anomaly requires another type of guarantee: consistent prefix reads. This guarantee says that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order.
This is a particular problem in partitioned (sharded) databases.
How to deal
One solution is to make sure that any writes that are causally related to each other are written to the same partition.
There are also algorithms that we will discuss in next chapter.
Solutions for Replication Lag
It would be better if application developers didn’t have to worry about subtle replication issues and could just trust their databases to “do the right thing.” This is why transactions exist: they are a way for a database to provide stronger guarantees so that the application can be simpler.
Multi-Leader Replication
A natural extension of the leader-based replication model is to allow more than one node to accept writes.
允许在多个 Leader 里同时进行写操作,很自然地想到这种模式下要面对的一个重要问题就是如何解决并发时的写冲突。
Use Cases for Multi-Leader Replication
Multi-datacenter operation
In a multi-leader configuration, you can have a leader in each datacenter. Within each datacenter, regular leader-follower replication is used; between datacenters, each datacenter’s leader replicates its changes to the leaders in other datacenters.
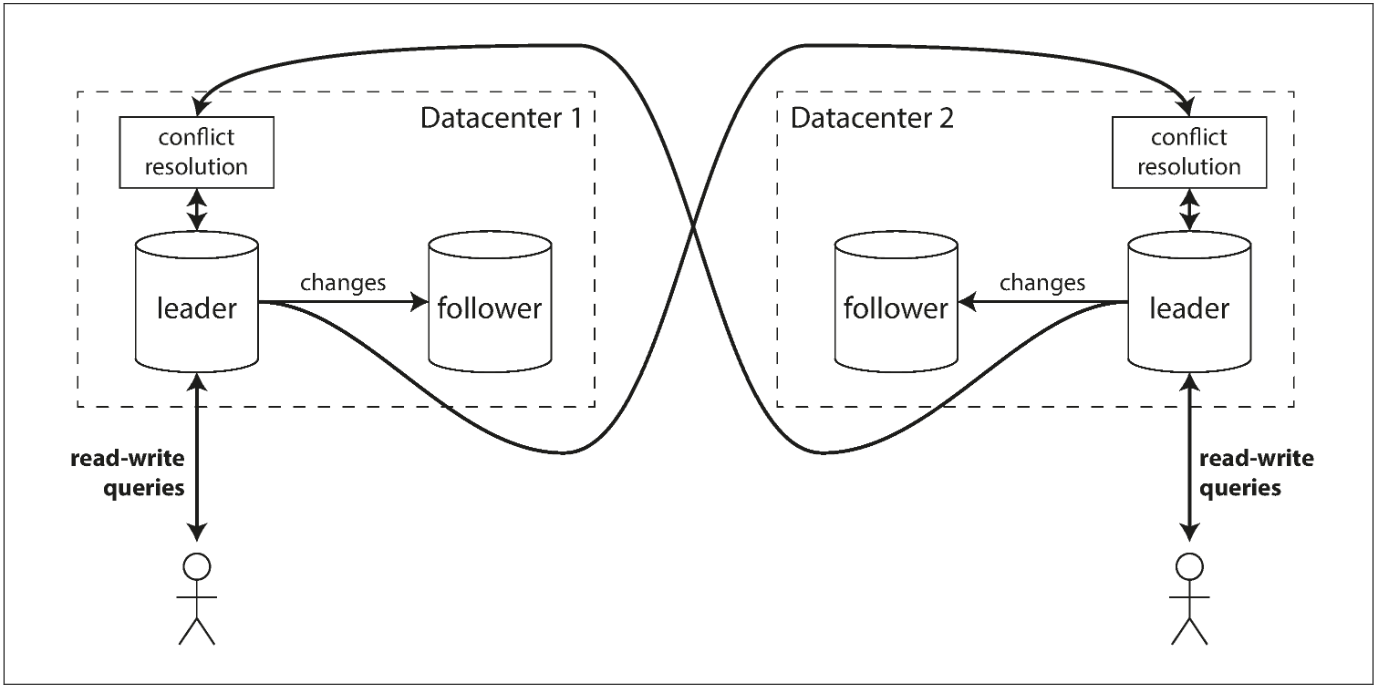
Let’s compare how the single-leader and multi-leader configurations fare in a multi-datacenter deployment:
- Performance
- The inter-datacenter network delay is hidden from users, which means the perceived performance may be better.
- Tolerance of datacenter outages
- In a multi-leader configuration, each datacenter can continue operating independently of the others
- Tolerance of network problems
- A multi-leader configuration with asynchronous replication can usually tolerate network problems better: a temporary network interruption does not prevent writes being processed.
Handling Write Conflicts
The biggest problem with multi-leader replication is that write conflicts can occur, which means that conflict resolution is required.
For example, consider a wiki page that is simultaneously being edited by two users, as shown below:

Conflict avoidance
The simplest strategy for dealing with conflicts is to avoid them: if the application can ensure that all writes for a particular record go through the same leader, then conflicts cannot occur.
For example, in an application where a user can edit their own data, you can ensure that requests from a particular user are always routed to the same datacenter and use the leader in that datacenter for reading and writing. Different users may have different “home” datacenters.
Converging toward a consistent state
If each replica simply applied writes in the order that it saw the writes, the database would end up in an inconsistent state (this will be OK in a single-leader database).
Thus, the database must resolve the conflict in a convergent way, which means that all replicas must arrive at the same final value when all changes have been replicated.
There are various ways of achieving convergent conflict resolution:
- Give each write a unique ID, pick the write with the highest ID as the winner, and throw away the other writes. If a timestamp is used, this technique is known as last write wins (LWW).
- It is dangerously prone to data loss.
- Record the conflict in an explicit data structure that preserves all information, and write application code that resolves the conflict at some later time (perhaps by prompting the user).
Custom conflict resolution logic
As the most appropriate way of resolving a conflict may depend on the application, most multi-leader replication tools let you write conflict resolution logic using application code.
- On write
- As soon as the database system detects a conflict in the log of replicated changes, it calls the conflict handler.
- On read
- When a conflict is detected, all the conflicting writes are stored. The next time the data is read, these multiple versions of the data are returned to the application.
Multi-Leader Replication Topologies
A replication topology describes the communication paths along which writes are propagated from one node to another.
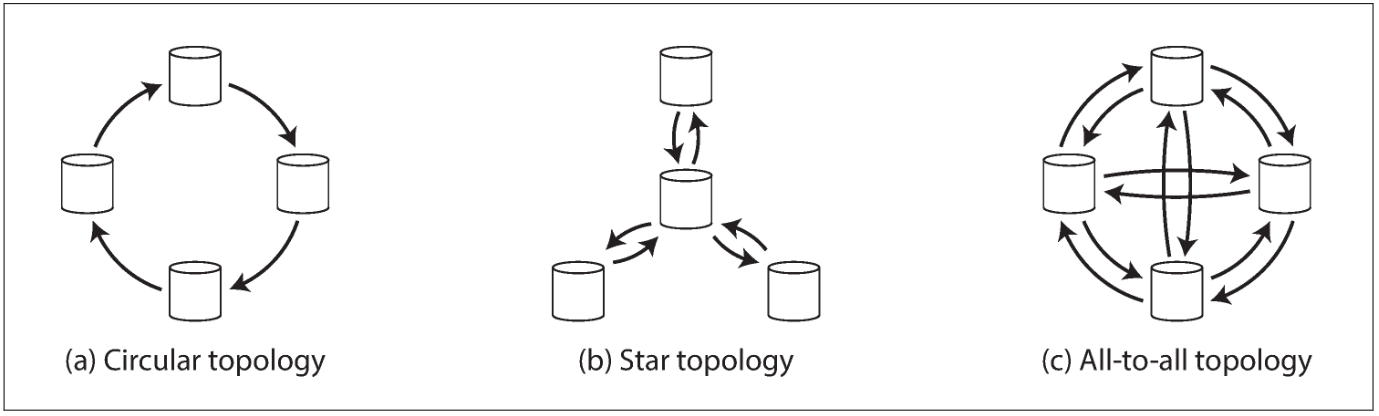
To prevent infinite replication loops, each node is given a unique identifier, and in the replication log, each write is tagged with the identifiers of all the nodes it has passed through.
With multi-leader replication, writes may arrive in the wrong order at some replicas:
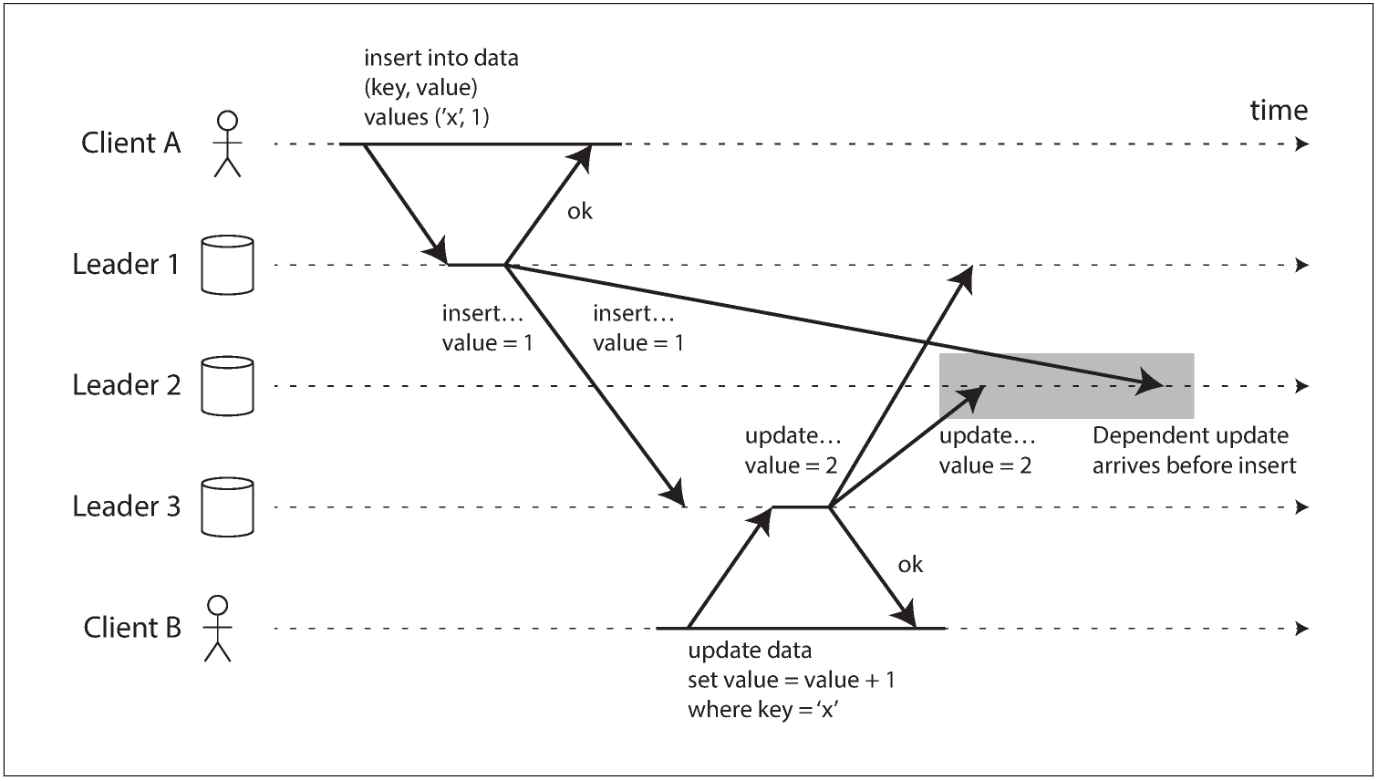
This is a problem of causality, simply attaching a timestamp to every write is not sufficient, because clocks cannot be trusted to be sufficiently in sync to correctly order these events at leader 2.
To order these events correctly, a technique called version vectors can be used.
Leaderless Replication
这种模式下,用户在执行写操作时需要把请求发到各个副本上。
Writing to the Database When a Node Is Down

To solve that problem, when a client reads from the database, it doesn’t just send its request to one replica: read requests are also sent to several nodes in parallel. The client may get different responses from different nodes; i.e., the up-to-date value from one node and a stale value from another. Version numbers are used to determine which value is newer.
Read repair and anti-entropy
The replication scheme should ensure that eventually all the data is copied to every replica. Two mechanisms are often used in Dynamo-style datastores:
- Read repair
- When a client makes a read from several nodes in parallel, it can detect any stale responses. The client sees that replica 3 has a stale value and writes the newer value back to that replica. This approach works well for values that are frequently read.
- Anti-entropy process
- Some datastores have a background process that constantly looks for differences in the data between replicas and copies any missing data from one replica to another.
Note that without an anti-entropy process, values that are rarely read may be missing from some replicas and thus have reduced durability, because read repair is only performed when a value is read by the application.
Quorums for reading and writing
More generally, if there are $n$ replicas, every write must be confirmed by $w$ nodes to be considered successful, and we must query at least $r$ nodes for each read.
As long as $w + r > n$, we expect to get an up-to-date value when reading, because at least one of the $r$ nodes we’re reading from must be up to date. Reads and writes that obey these $r$ and $w$ values are called quorum reads and writes.
You can think of $r$ and $w$ as the minimum number of votes required for the read or write to be valid. Normally, reads and writes are always sent to all $n$ replicas in parallel. The parameters $w$ and $r$ determine how many nodes we wait for.
However, you can vary the numbers as you see fit. For example, a workload with few writes and many reads may benefit from setting $w = n$ and $r = 1$. This makes reads faster, but has the disadvantage that just one failed node causes all database writes to fail.
Limitations of Quorum Consistency
If you have $n$ replicas, and you choose $w$ and $r$ such that $w + r > n$, you can generally expect every read to return the most recent value written for a key. This is the case because the set of nodes to which you’ve written and the set of nodes from which you’ve read must overlap.
With a smaller $w$ and $r$ you are more likely to read stale values, because it’s more likely that your read didn’t include the node with the latest value. On the upside, this configuration allows lower latency and higher availability.
However, even with w + r > n, there are likely to be edge cases where stale values are returned:
- If a write happens concurrently with a read, the write may be reflected on only some of the replicas. In this case, it’s undetermined whether the read returns the old or the new value.
- If a node carrying a new value fails, and its data is restored from a replica carrying an old value, the number of replicas storing the new value may fall below w, breaking the quorum condition.
- Even if everything is working correctly, there are edge cases in which you can get unlucky with the timing.
The parameters $w$ and $r$ allow you to adjust the probability of stale values being read, but it’s wise to not take them as absolute guarantees.
Monitoring staleness
For leader-based replication, the database typically exposes metrics for the replication lag, which you can feed into a monitoring system. This is possible because writes are applied to the leader and to followers in the same order, and each node has a position in the replication log.
Eventual consistency is a deliberately vague guarantee, but for operability it’s important to be able to quantify “eventual.”
Sloppy Quorums and Hinted Handoff
Quorums reading and writing make databases with leaderless replication appealing for use cases that require high availability and low latency, and that can tolerate occasional stale reads.
Detecting Concurrent Writes
Last write wins (discarding concurrent writes)
One approach for achieving eventual convergence is to declare that each replica need only store the most “recent” value and allow “older” values to be overwritten and discarded.
For example, we can attach a timestamp to each write, pick the biggest timestamp as the most “recent,” and discard any writes with an earlier timestamp. This conflict resolution algorithm, called last write wins (LWW).
LWW achieves the goal of eventual convergence, but at the cost of durability: if there are several concurrent writes to the same key, even if they were all reported as successful to the client (because they were written to w replicas), only one of the writes will survive and the others will be silently discarded.
The “happens-before” relationship and concurrency
How do we decide whether two operations are concurrent or not?
An operation A happens before another operation B if B knows about A, or depends on A, or builds upon A in some way. Whether one operation happens before another operation is the key to defining what concurrency means. In fact, we can simply say that two operations are concurrent if neither happens before the other.
It may seem that two operations should be called concurrent if they occur “at the same time” — but in fact, it is not important whether they literally overlap in time because of problems with clocks in distributed systems.
We simply call two operations concurrent if they are both unaware of each other, regardless of the physical time at which they occurred.