The main reason for wanting to partition data is scalability.
Normally, partitions are defined in such a way that each piece of data (each record, row, or document) belongs to exactly one partition.
Partitioning and Replication
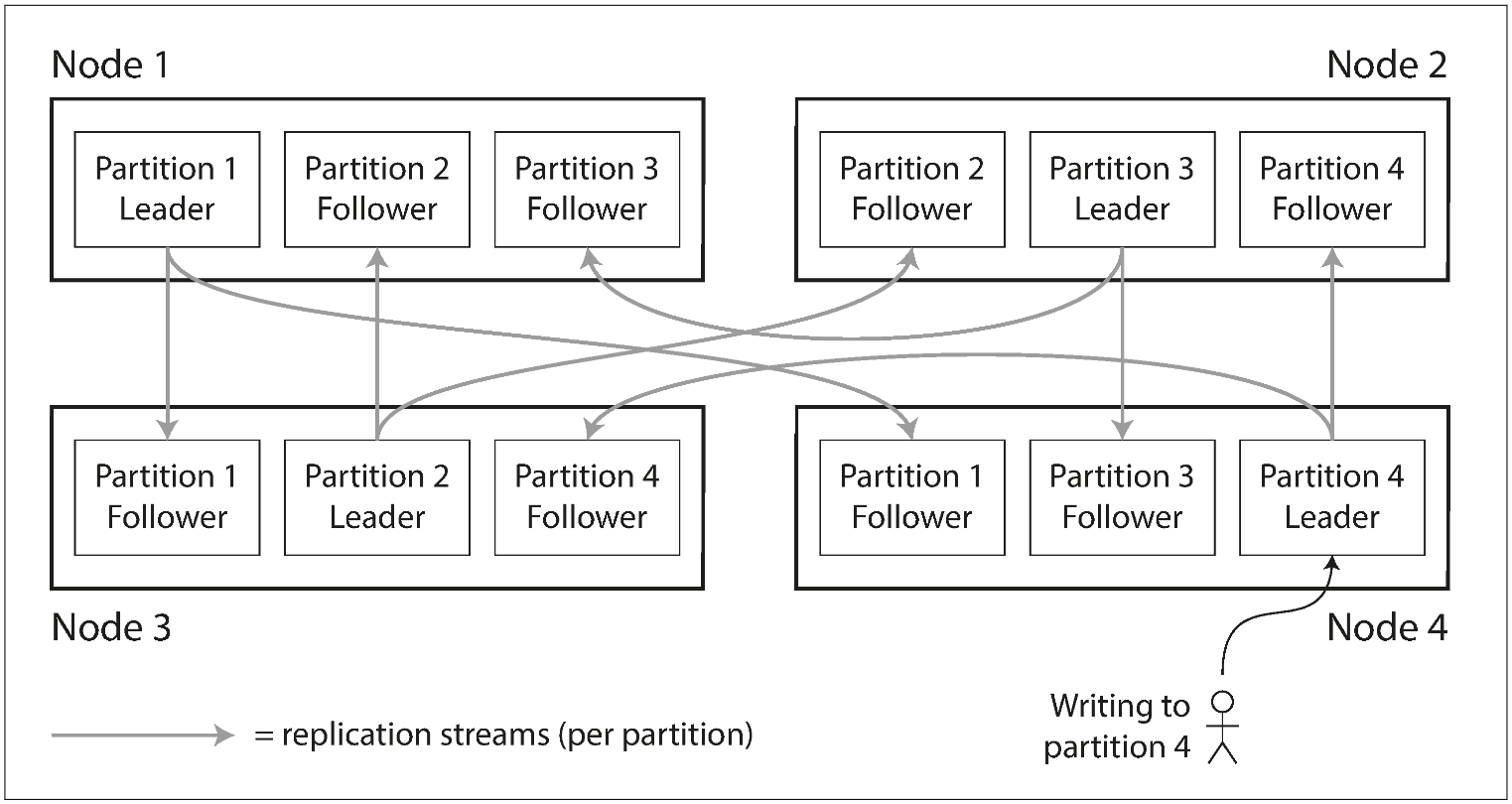
Partitioning is usually combined with replication so that copies of each partition are stored on multiple nodes. This means that, even though each record belongs to exactly one partition, it may still be stored on several different nodes for fault tolerance.
A node may store more than one partition. If a leader–follower replication model is used, the combination of partitioning and replication can look like below. Each partition’s leader is assigned to one node, and its followers are assigned to other nodes. Each node may be the leader for some partitions and a follower for other partitions.
Partitioning of Key-Value Data
The goal with partitioning is to spread the data and the query load evenly across nodes.
If the partitioning is unfair, so that some partitions have more data or queries than others, we call it skewed. A partition with disproportionately high load is called a hot spot.
Partitioning by Key Range

However, the downside of key range partitioning is that certain access patterns can lead to hot spots.
Partitioning by Hash of Key
“More balanced but lose the ability to range queries.”
Because of this risk of skew and hot spots, many distributed datastores use a hash function to determine the partition for a given key.
Once you have a suitable hash function for keys, you can assign each partition a range of hashes (rather than a range of keys), and every key whose hash falls within a partition’s range will be stored in that partition.

This technique is good at distributing keys fairly among the partitions. The partition boundaries can be evenly spaced, or they can be chosen pseudorandomly (in which case the technique is sometimes known as consistent hashing).
By using the hash of the key for partitioning we lose a nice property of key-range partitioning: the ability to do efficient range queries (any range query has to be sent to all partitions).
A table in Cassandra can be declared with a compound primary key consisting of several columns. Only the first part of that key is hashed to determine the partition, but the other columns are used as a concatenated index for sorting the data in Cassandra’s SSTables.
Skewed Workloads and Relieving Hot Spots
However, hashing a key can’t avoid them entirely: in the extreme case where all reads and writes are for the same key, you still end up with all requests being routed to the same partition.
比如微博大 V 发新动态,很多人去评论之类的。
Today, most data systems are not able to automatically compensate for such a highly skewed workload, so it’s the responsibility of the application to reduce the skew.
For example, if one key is known to be very hot, a simple technique is to add a random number to the beginning or end of the key.
Partitioning and Secondary Indexes
The situation becomes more complicated if secondary indexes are involved.
A secondary index usually doesn’t identify a record uniquely but rather is a way of searching for occurrences of a particular value: find all actions by user 123, find all articles containing the word hogwash, find all cars whose color is red, and so on.
Secondary indexes are the bread and butter of relational databases, and they are common in document databases too.
Partitioning Secondary Indexes by Document

In this indexing approach, each partition is completely separate: each partition maintains its own secondary indexes, covering only the documents in that partition. For that reason, a document-partitioned index is also known as a local index.
This approach to querying a partitioned database is sometimes known as scatter/gather, and it can make read queries on secondary indexes quite expensive.
总结一下,这种方式写入快,因为只涉及到一个分区的索引更新;读的速度慢,对于一个特定索引,需要查询所有分区才行。
Partitioning Secondary Indexes by Term
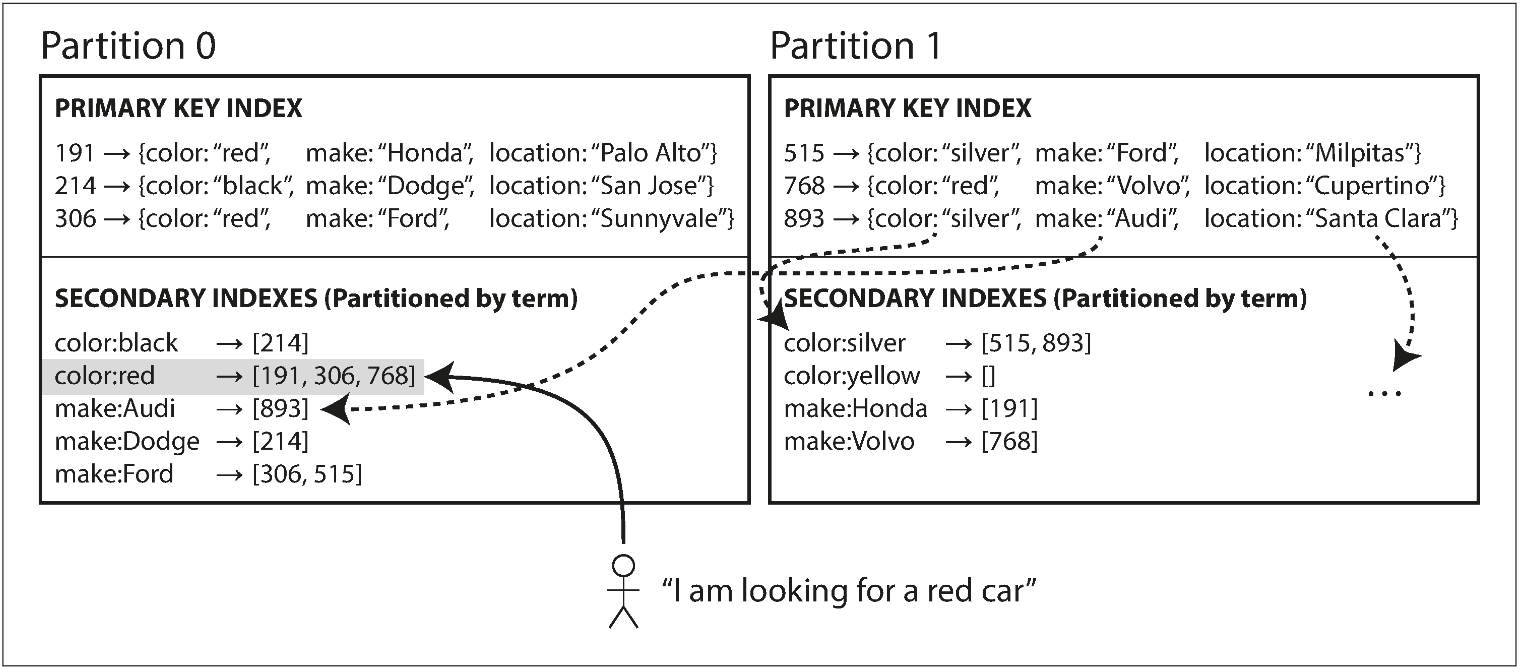
A global index must also be partitioned, but it can be partitioned differently from the primary key index. We call this kind of index term-partitioned, because the term we’re looking for determines the partition of the index.
The advantage of a global (term-partitioned) index over a document-partitioned index is that it can make reads more efficient: rather than doing scatter/gather over all partitions, a client only needs to make a request to the partition containing the term that it wants. The downside of a global index is that writes are slower and more complicated.
总结一下,这种方式写入慢,因为要涉及到多个分区中索引的更改;读的速度很快,只需要读包含那个索引的分区即可。
Rebalancing Partitions
The process of moving load from one node in the cluster to another is called rebalancing.
Rebalancing is usually expected to meet some minimum requirements:
- After rebalancing, the load (data storage, read and write requests) should be shared fairly between the nodes in the cluster.
- While rebalancing is happening, the database should continue accepting reads and writes.
- No more data than necessary should be moved between nodes, to make rebalancing fast and to minimize the network and disk I/O load.
Strategies for Rebalancing
最愚蠢的分区方式是 hash mod N,一旦 N 发生改变,数据会大量迁移,此时可以考虑使用一致性哈希。
Fixed number of partitions
Fortunately, there is a fairly simple solution: create many more partitions than there are nodes, and assign several partitions to each node.
Now, if a node is added to the cluster, the new node can steal a few partitions from every existing node until partitions are fairly distributed once again.

This approach to rebalancing is used in Riak, Elasticsearch, Couchbase, and Voldemort.
In this configuration, the number of partitions is usually fixed when the database is first set up and not changed afterward.
Dynamic partitioning
For databases that use key range partitioning, a fixed number of partitions with fixed boundaries would be very inconvenient: if you got the boundaries wrong, you could end up with all of the data in one partition and all of the other partitions empty.
For that reason, key range–partitioned databases such as HBase and RethinkDB create partitions dynamically.
An advantage of dynamic partitioning is that the number of partitions adapts to the total data volume.
Operations: Automatic or Manual Rebalancing
Fully automated rebalancing can be convenient, because there is less operational work to do for normal maintenance. However, it can be unpredictable. If it is not done carefully, this process can overload the network or the nodes and harm the performance of other requests while the rebalancing is in progress.
For that reason, it can be a good thing to have a human in the loop for rebalancing. It’s slower than a fully automatic process, but it can help prevent operational surprises.
Request Routing
A question remains: When a client wants to make a request, how does it know which node to connect to?
This is an instance of a more general problem called service discovery, which isn’t limited to just databases.
On a high level, there are a few different approaches to this problem:
- Allow clients to contact any node. If that node coincidentally owns the partition to which the request applies, it can handle the request directly; otherwise, it forwards the request to the appropriate node, receives the reply, and passes the reply along to the client.
- Send all requests from clients to a routing tier first, which determines the node that should handle each request and forwards it accordingly.
- Require that clients be aware of the partitioning and the assignment of partitions to nodes.
感觉有个中间层是最好的,比如 gataway 就能顺便把这个事做了

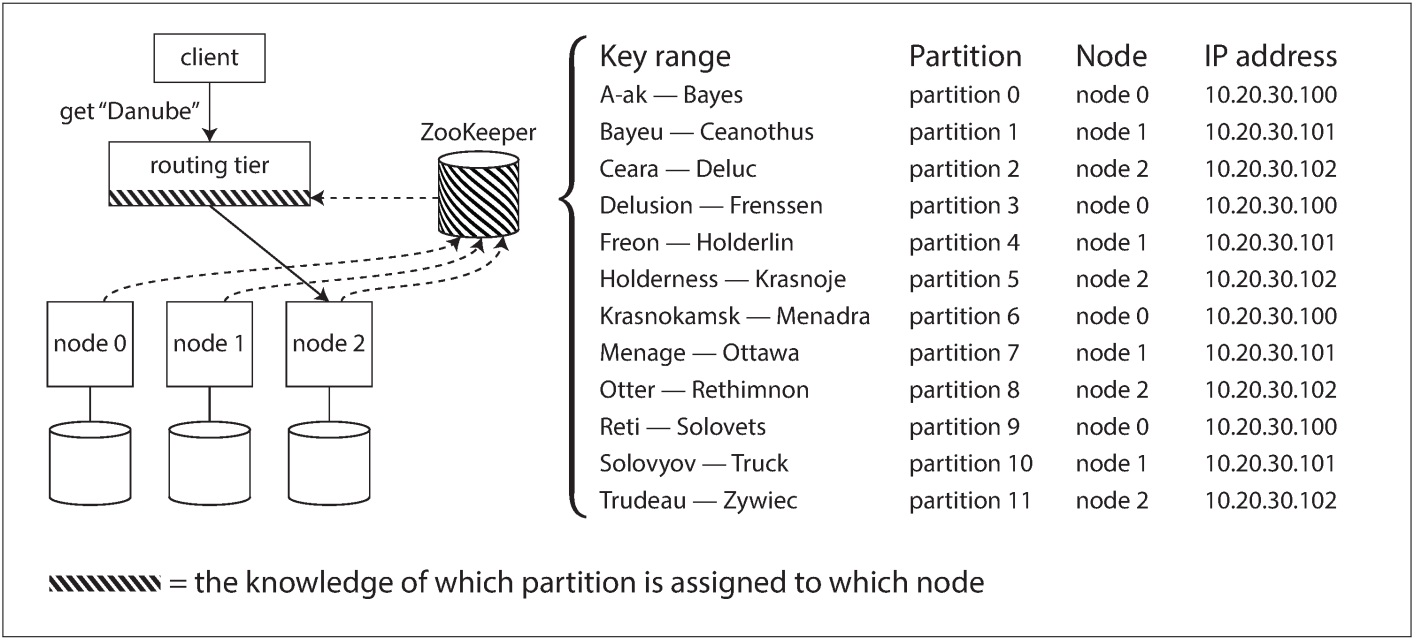
Many distributed data systems rely on a separate coordination service such as Zoo‐ Keeper to keep track of this cluster metadata, as illustrated in below:
Each node registers itself in ZooKeeper, and ZooKeeper maintains the authoritative mapping of partitions to nodes. Other actors, such as the routing tier or the partitioning-aware client, can subscribe to this information in ZooKeeper. Whenever a partition changes ownership, or a node is added or removed, ZooKeeper notifies the routing tier so that it can keep its routing information up to date.