A transaction is a way for an application to group several reads and writes together into a logical unit.
Transactions are not a law of nature; they were created with a purpose, namely to simplify the programming model for applications accessing a database.
相当于数据库提供了一层重要的抽象,在编写应用程序时不用再去考虑那些能被事务处理的错误与问题了。
The Meaning of ACID
The safety guarantees provided by transactions are often described by the well known acronym ACID, which stands for Atomicity, Consistency, Isolation, and Durability.
However, in practice, one database’s implementation of ACID does not equal another’s implementation. The high-level idea is sound, but the devil is in the details. ACID has unfortunately become mostly a marketing term.
Systems that do not meet the ACID criteria are sometimes called BASE, which stands for Basically Available, Soft state, and Eventual consistency. This is even more vague than the definition of ACID. It seems that the only sensible definition of BASE is “not ACID”; i.e., it can mean almost anything you want.)
Atomicity
“All or nothing”
If the writes are grouped together into an atomic transaction, and the transaction cannot be completed (committed) due to a fault, then the transaction is aborted and the database must discard or undo any writes it has made so far in that transaction.
Atomicity simplifies this problem: if a transaction was aborted, the application can be sure that it didn’t change anything, so it can safely be retried.
The ability to abort a transaction on error and have all writes from that transaction discarded is the defining feature of ACID atomicity.
Consistency
“It looks correct to me”
The word consistency is terribly overloaded:
- Discussed replica consistency and the issue of eventual consistency that arises in asynchronously replicated systems.
- Consistent hashing is an approach to partitioning that some systems use for rebalancing.
- In the CAP theorem, the word consistency is used to mean linearizability.
- In the context of ACID, consistency refers to an application-specific notion of the database being in a “good state.”
The idea of ACID consistency is that you have certain statements about your data (invariants) that must always be true.
For example, in an accounting system, credits and debits across all accounts must always be balanced.
This idea of consistency depends on the application’s notion of invariants, and it’s the application’s responsibility to define its transactions correctly so that they preserve consistency.
Atomicity, isolation, and durability are properties of the database, whereas consistency (in the ACID sense) is a property of the application.
The application may rely on the database’s atomicity and isolation properties in order to achieve consistency, but it’s not up to the database alone. Thus, the letter C doesn’t really belong in ACID.
Isolation
“As if alone”
Isolation in the sense of ACID means that concurrently executing transactions are isolated from each other: they cannot step on each other’s toes. The classic database textbooks formalize isolation as serializability, which means that each transaction can pretend that it is the only transaction running on the entire database.
The database ensures that when the transactions have committed, the result is the same as if they had run serially (one after another), even though in reality they may have run concurrently.
Durability
“Survive failures”
Durability is the promise that once a transaction has committed successfully, any data it has written will not be forgotten, even if there is a hardware fault or the database crashes.
Single-Object and Multi-Object Operations
In ACID, atomicity and isolation describe what the database should do if a client makes several writes within the same transaction:
- Atomicity
- If an error occurs halfway through a sequence of writes, the transaction should be aborted, and the writes made up to that point should be discarded.
- In other words, the database saves you from having to worry about partial failure, by giving an all-or-nothing guarantee.
- Isolation
- Concurrently running transactions shouldn’t interfere with each other.
Such multi-object transactions are often needed if several pieces of data need to be kept in sync.
Single-object writes
“Transactions should be introduced when write large objects into database.”
Atomicity and isolation also apply when a single object is being changed. For example, imagine you are writing a 20 KB JSON document to a database.
Atomicity can be implemented using a log for crash recovery, and isolation can be implemented using a lock on each object (allowing only one thread to access an object at any one time).
The need for multi-object transactions
However, in many other cases writes to several different objects need to be coordinated:
- In a relational data model, a row in one table often has a foreign key reference to a row in another table. Multi-object transactions allow you to ensure that these references remain valid.
- When denormalized information needs to be updated, you need to update several documents in one go. Transactions are very useful in this situation to prevent denormalized data from going out of sync.
- In databases with secondary indexes (almost everything except pure key-value stores), the indexes also need to be updated every time you change a value.
Handling errors and aborts
“Retrying is not perfect.”
Retrying an aborted transaction is a simple and effective error handling mechanism, it isn’t perfect:
- If the transaction actually succeeded, but the network failed while the server tried to acknowledge the successful commit to the client (so the client thinks it failed), then retrying the transaction causes it to be performed twice — unless you have an additional application-level deduplication mechanism in place.
- If the error is due to overload, retrying the transaction will make the problem worse, not better.
- If the transaction also has side effects outside of the database, those side effects may happen even if the transaction is aborted.
- If the client process fails while retrying, any data it was trying to write to the database is lost.
Weak Isolation Levels
“Stronger isolation, worse performance.”
If two transactions don’t touch the same data, they can safely be run in parallel, because neither depends on the other.
Databases have long tried to hide concurrency issues from application developers by providing transaction isolation. In theory, isolation should make your life easier by letting you pretend that no concurrency is happening.
Serializable isolation means that the database guarantees that transactions have the same effect as if they ran serially (i.e., one at a time, without any concurrency). However, serializable isolation has a performance cost, and many databases don’t want to pay that price.
It’s therefore common for systems to use weaker levels of isolation, which protect against some concurrency issues, but not all.
Read Committed
“No dirty reads and no dirty writes.”
The most basic level of transaction isolation is read committed. It makes two guarantees:
- When reading from the database, you will only see data that has been committed (no dirty reads).
- When writing to the database, you will only overwrite data that has been committed (no dirty writes).
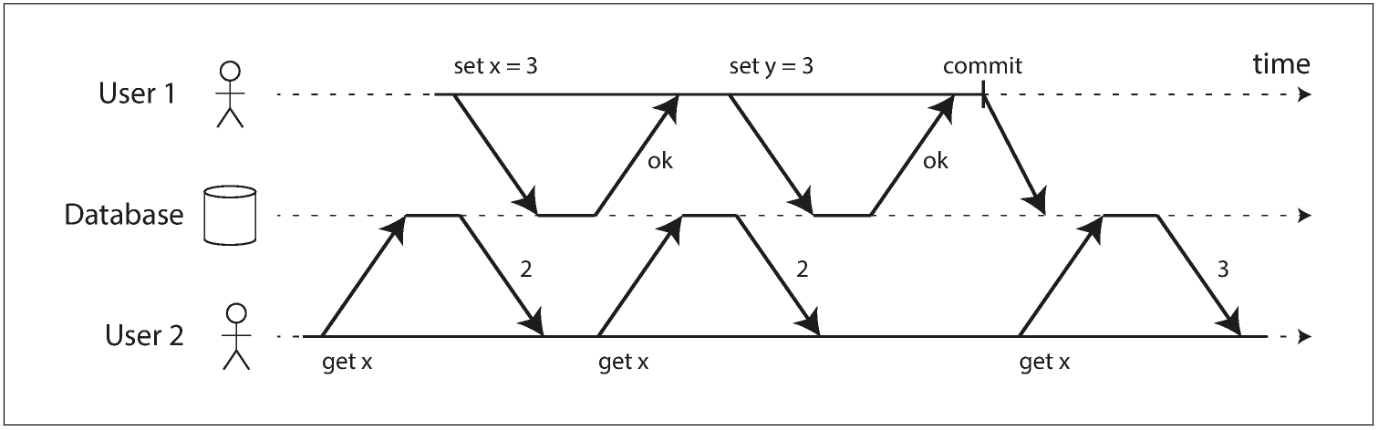
No dirty reads
“Any writes by a transaction only become visible to others when that transaction commits”
Imagine a transaction has written some data to the database, but the transaction has not yet committed or aborted. Can another transaction see that uncommitted data? If yes, that is called a dirty read.
No dirty writes
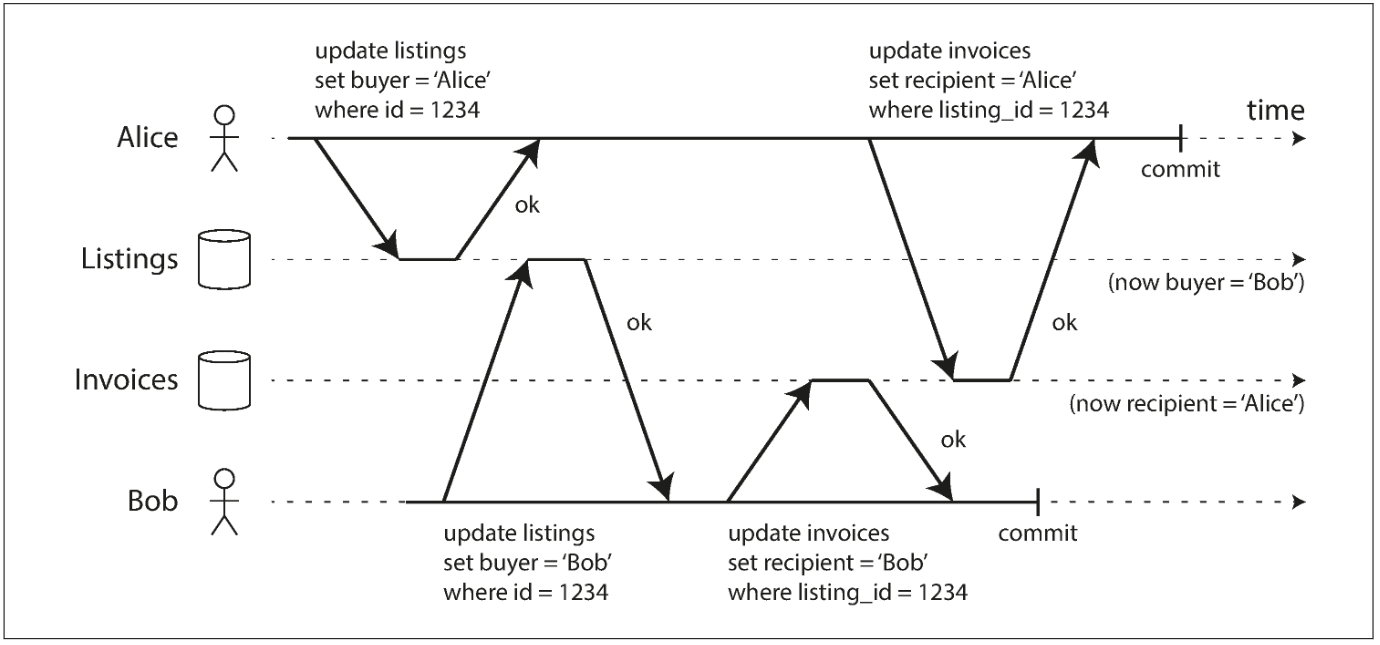
Transactions running at the read committed isolation level must prevent dirty writes, usually by delaying the second write until the first write’s transaction has committed or aborted.
With dirty writes, conflicting writes from different transactions can be mixed up.
Implementing read committed
Most commonly, databases prevent dirty writes by using row-level locks: when a transaction wants to modify a particular object (row or document), it must first acquire a lock on that object. It must then hold that lock until the transaction is committed or aborted.
How about dirty reads?
One option would be to use the same lock, but it is not practicing, since one long-running write transaction can force many read-only transactions to wait until the long-running transaction has completed.
Another approach is better: For every object that is written, the database remembers both the old committed value and the new value set by the transaction that currently holds the write lock. While the transaction is ongoing, any other transactions that read the object are simply given the old value. Only when the new value is committed do transactions switch over to reading the new value.
Snapshot Isolation and Repeatable Read
However, there are still plenty of ways in which you can have concurrency bugs when using this isolation level:
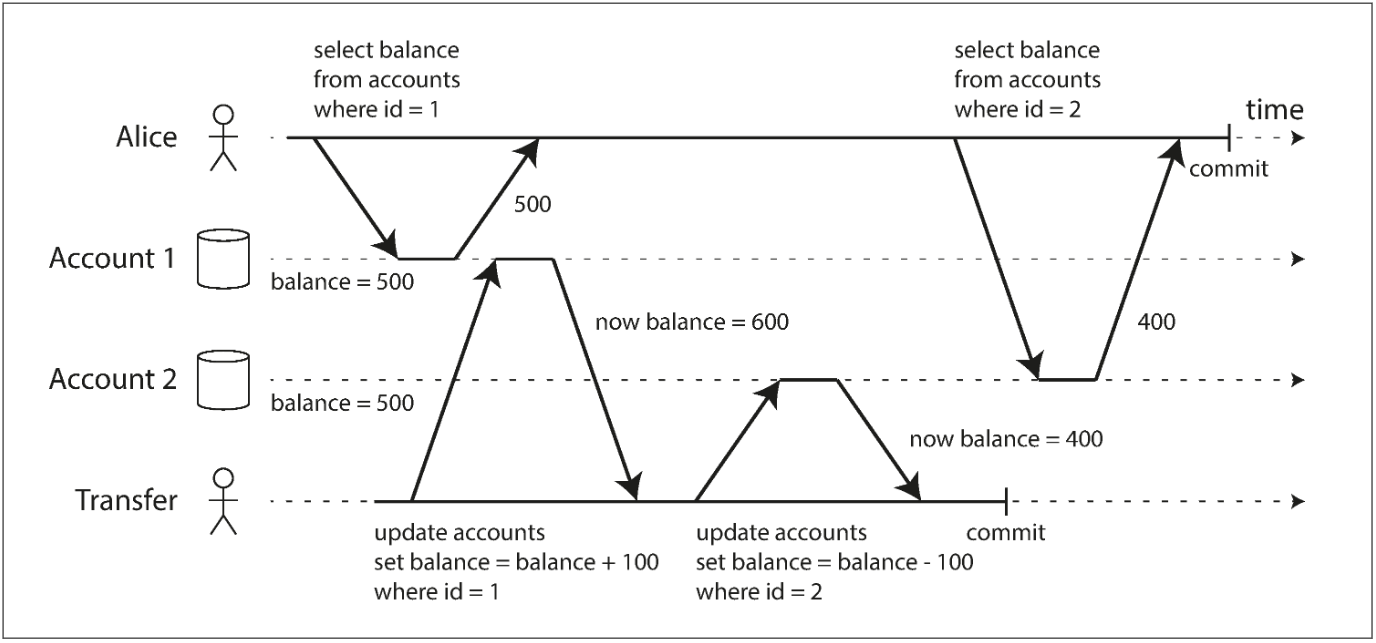
This anomaly is called a nonrepeatable read or read skew: if Alice were to read the balance of account 1 again at the end of the transaction, she would see a different value ($600) than she saw in her previous query.
Read skew is considered acceptable under read committed isolation: the account balances that Alice saw were indeed committed at the time when she read them.
In Alice’s case, this is not a lasting problem, because she will most likely see consistent account balances if she reloads the online banking website a few seconds later.
Snapshot isolation is the most common solution to this problem. The idea is that each transaction reads from a consistent snapshot of the database—that is, the transaction sees all the data that was committed in the database at the start of the transaction.
Implementing snapshot isolation
From a performance point of view, a key principle of snapshot isolation is readers never block writers, and writers never block readers.
To implement snapshot isolation, databases use a generalization of the mechanism. The database must potentially keep several different committed versions of an object, because various in-progress transactions may need to see the state of the database at different points in time. Because it maintains several versions of an object side by side, this technique is known as multiversion concurrency control (MVCC).
If a database only needed to provide read committed isolation, but not snapshot isolation, it would be sufficient to keep two versions of an object: the committed version and the overwritten-but-not-yet-committed version. However, storage engines that support snapshot isolation typically use MVCC for their read committed isolation level as well. A typical approach is that read committed uses a separate snapshot for each query, while snapshot isolation uses the same snapshot for an entire transaction.

With append-only B-trees, every write transaction (or batch of transactions) creates a new B-tree root, and a particular root is a consistent snapshot of the database at the point in time when it was created.
Preventing Lost Updates
There are several other interesting kinds of conflicts that can occur between concurrently writing transactions. The best known of these is the lost update problem, illustrated below:

The lost update problem can occur if an application reads some value from the database, modifies it, and writes back the modified value (a read-modify-write cycle).
This pattern occurs in various different scenarios:
- Incrementing a counter or updating an account balance。
- Making a local change to a complex value, e.g., adding an element to a list within a JSON document (requires parsing the document, making the change, and writing back the modified document)
- Two users editing a wiki page at the same time, where each user saves their changes by sending the entire page contents to the server, overwriting whatever is currently in the database.
Because this is such a common problem, a variety of solutions have been developed.
Atomic write operations
Many databases provide atomic update operations, which remove the need to implement read-modify-write cycles in application code. They are usually the best solution if your code can be expressed in terms of those operations.
UPDATE counters SET value = value + 1 WHERE key = 'foo';
Automatically detecting lost updates
An alternative is to allow them to execute in parallel and, if the transaction manager detects a lost update, abort the transaction and force it to retry its read-modify-write cycle.
Compare-and-set
The purpose of this operation is to avoid lost updates by allowing an update to happen only if the value has not changed since you last read it.
-- This may or may not be safe, depending on the database implementation
UPDATE wiki_pages SET content = 'new content' WHERE id = 1234 AND content = 'old content';
Conflict resolution and replication
Locks and compare-and-set operations assume that there is a single up-to-date copy of the data. However, databases with multi-leader or leaderless replication usually allow several writes to happen concurrently and replicate them asynchronously, so they cannot guarantee that there is a single up-to-date copy of the data.
A common approach in such replicated databases is to allow concurrent writes to create several conflicting versions of a value (also known as siblings), and to use application code or special data structures to resolve and merge these versions after the fact.
Write Skew and Phantoms
This is an example of write skew:
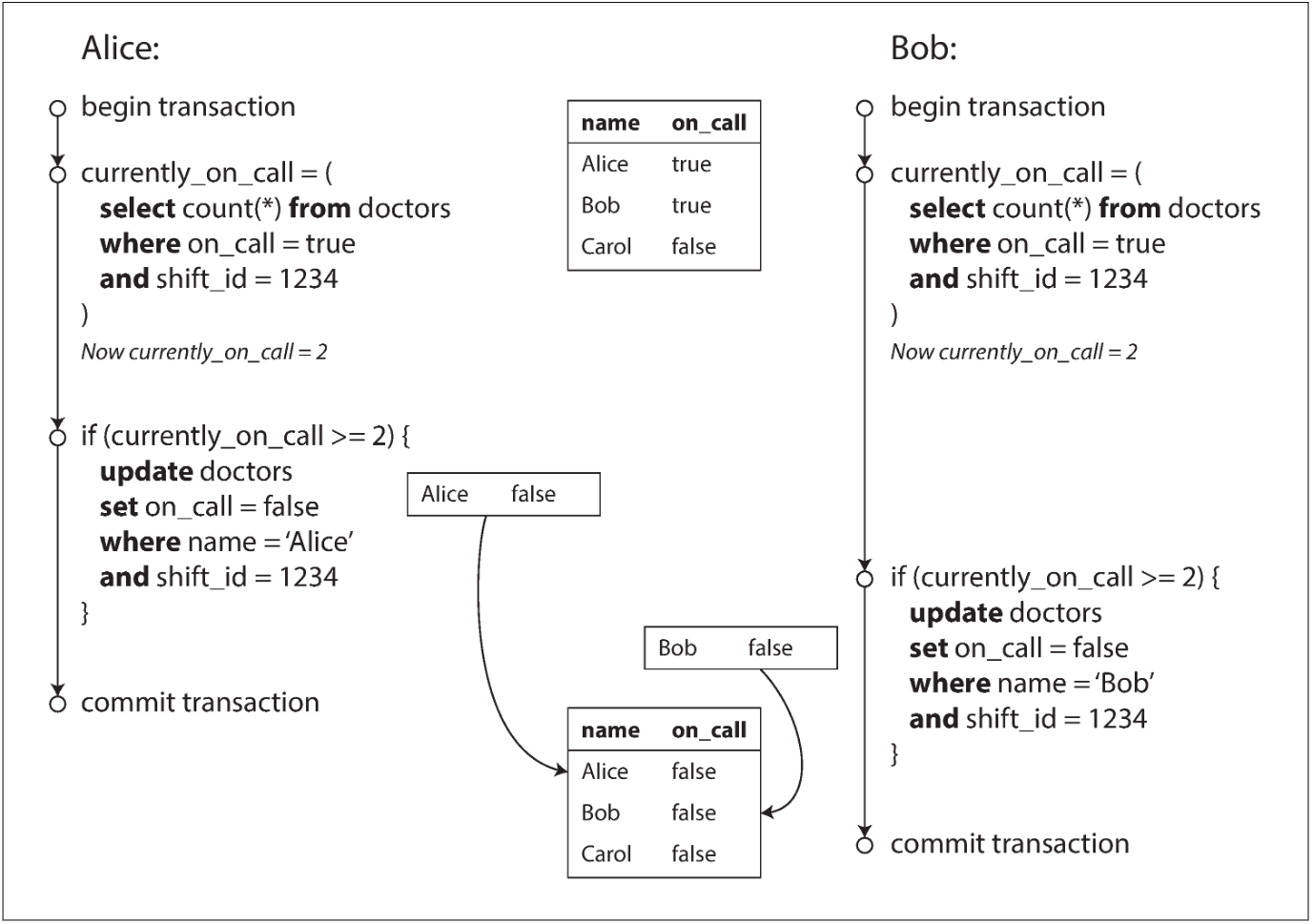
Characterizing write skew
The anomalous behavior was only possible because the transactions ran concurrently.
You can think of write skew as a generalization of the lost update problem. Write skew can occur if two transactions read the same objects, and then update some of those objects (different transactions may update different objects).
All of these examples follow a similar pattern:
- A
SELECTquery checks whether some requirement is satisfied by searching for rows that match some search condition. - Depending on the result of the first query, the application code decides how to continue.
- If the application decides to go ahead, it makes a write (
INSERT,UPDATE, orDELETE) to the database and commits the transaction.
The effect of this write changes the precondition of the decision of step 2. In other words, if you were to repeat the SELECT query from step 1 after commiting the write, you would get a different result, because the write changed the set of rows matching the search condition.
This effect, where a write in one transaction changes the result of a search query in another transaction, is called a phantom. Snapshot isolation avoids phantoms in read-only queries, but in read-write transactions like the examples we discussed, phantoms can lead to particularly tricky cases of write skew.
Serializability
Serializable isolation is usually regarded as the strongest isolation level. It guarantees that even though transactions may execute in parallel, the end result is the same as if they had executed one at a time, serially, without any concurrency. In other words, the database prevents all possible race conditions.
Actual Serial Execution
The simplest way of avoiding concurrency problems is to remove the concurrency entirely: to execute only one transaction at a time, in serial order, on a single thread.
This approach looks silly, but it is definitely valuable:
- RAM became cheap enough that for many use cases is now feasible to keep the entire active dataset in memory. (transactions can execute much faster)
- Database designers realized that OLTP transactions are usually short and only make a small number of reads and writes.
A system designed for single-threaded execution can sometimes perform better than a system that supports concurrency, because it can avoid the coordination overhead of locking.
Summary:
- Every transaction must be small and fast, because it takes only one slow transaction to stall all transaction processing.
- It is limited to use cases where the active dataset can fit in memory.
- Write throughput must be low enough to be handled on a single CPU core.
Two-Phase Locking (2PL)
In 2PL, writers don’t just block other writers; they also block readers and vice versa. Snapshot isolation has the mantra readers never block writers, and writers never block readers, which captures this key difference between snapshot isolation and two-phase locking.
2PL provides serializability, it protects against all the race conditions discussed earlier, including lost updates and write skew.
Implementation of two-phase locking
The lock can either be in shared mode or in exclusive mode. The lock is used as follows:
- If a transaction wants to read an object, it must first acquire the lock in shared mode.
- If a transaction wants to write to an object, it must first acquire the lock in exclusive mode.
- If a transaction first reads and then writes an object, it may upgrade its shared lock to an exclusive lock.
- After a transaction has acquired the lock, it must continue to hold the lock until the end of the transaction (commit or abort).
This is where the name “two phase” comes from: the first phase (while the transaction is executing) is when the locks are acquired, and the second phase (at the end of the transaction) is when all the locks are released.
Performance of two-phase locking
Transaction throughput and response times of queries are significantly worse under two-phase locking than under weak isolation. This is partly due to the overhead of acquiring and releasing all those locks, but more importantly due to reduced concurrency.
Although deadlocks can happen with the lock-based read committed isolation level, they occur much more frequently under 2PL serializable isolation。
Predicate locks
How to prevent phantoms with serializable isolation?
In the meeting room booking example this means that if one transaction has searched for existing bookings for a room within a certain time window, another transaction is not allowed to concurrently insert or update another booking for the same room and time range.
Conceptually, we need a predicate lock. It works similarly to the shared/exclusive lock described earlier, but rather than belonging to a particular object (e.g., one row in a table), it belongs to all objects that match some search condition, such as:
SELECT * FROM bookings
WHERE room_id = 123 AND
end_time > '2018-01-01 12:00' AND
start_time < '2018-01-01 13:00';
A predicate lock restricts access as follows:
- If transaction A wants to read objects matching some condition, like in that SELECT query, it must acquire a shared-mode predicate lock on the conditions of the query. If another transaction B currently has an exclusive lock on any object matching those conditions, A must wait until B releases its lock before it is allowed to make its query.
- If transaction A wants to insert, update, or delete any object, it must first check whether either the old or the new value matches any existing predicate lock.
The key idea here is that a predicate lock applies even to objects that do not yet exist in the database, but which might be added in the future (phantoms).
Serializable Snapshot Isolation (SSI)
An algorithm called serializable snapshot isolation (SSI) is very promising. It provides full serializability, but has only a small performance penalty compared to snapshot isolation.
Pessimistic versus optimistic concurrency control
Two-phase locking is a so-called pessimistic concurrency control mechanism: it is based on the principle that if anything might possibly go wrong (as indicated by a lock held by another transaction), it’s better to wait until the situation is safe again before doing anything.
Serial execution is, in a sense, pessimistic to the extreme: it is essentially equivalent to each transaction having an exclusive lock on the entire database (or one partition of the database) for the duration of the transaction.
By contrast, serializable snapshot isolation is an optimistic concurrency control technique. Optimistic in this context means that instead of blocking if something potentially dangerous happens, transactions continue anyway, in the hope that everything will turn out all right.
If there is enough spare capacity, and if contention between transactions is not too high, optimistic concurrency control techniques tend to perform better than pessimistic ones.
On top of snapshot isolation, SSI adds an algorithm for detecting serialization conflicts among writes and determining which transactions to abort.
Decisions based on an outdated premise
“read first then write, indicates the decision of writing may depend on the result of reading.”
We observed a recurring pattern when discussing write skew: a transaction reads some data from the database, examines the result of the query, and decides to take some action (write to the database) based on the result that it saw.
The transaction is taking an action based on a premise (a fact that was true at the beginning of the transaction.)
To be safe, the database needs to assume that any change in the query result (the premise) means that writes in that transaction may be invalid.
In other words, there may be a causal dependency between the queries and the writes in the transaction.
In order to provide serializable isolation, the database must detect situations in which a transaction may have acted on an outdated premise and abort the transaction in that case.
How does the database know if a query result might have changed? There are two cases to consider:
- Detecting reads of a stale MVCC object version (uncommitted write occurred before the read)
- Detecting writes that affect prior reads (the write occurs after the read)
Detecting stale MVCC reads
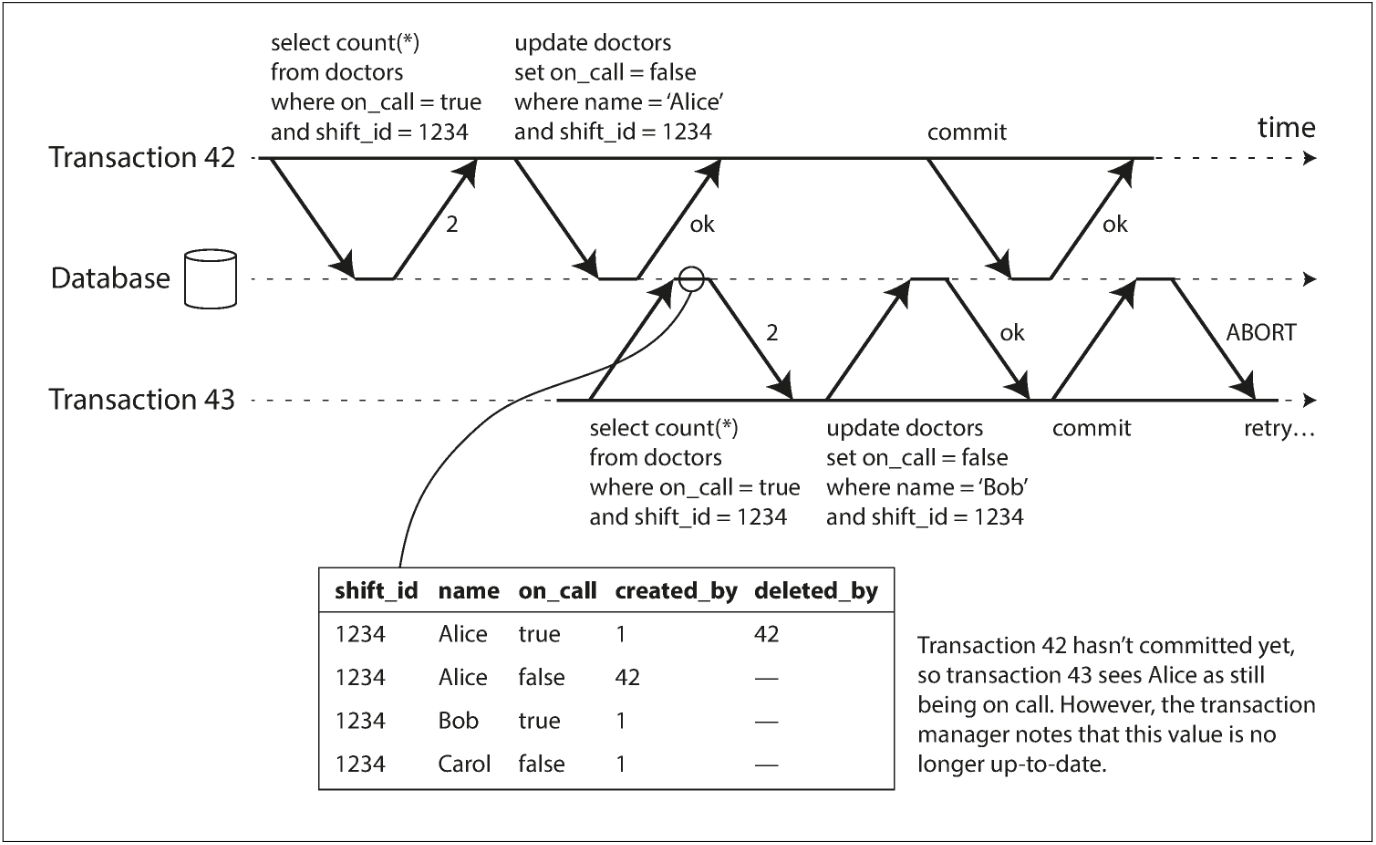
简单来说,在事务准备提交时,数据库会检查它读过的数据是否发生了改变(即那些数据是不是被其他事务提交过),如果是的话,就中断本次事务。
However, by the time transaction 43 wants to commit, transaction 42 has already committed. This means that the write that was ignored when reading from the consistent snapshot has now taken effect, and transaction 43’s premise is no longer true.
In order to prevent this anomaly, the database needs to track when a transaction ignores another transaction’s writes due to MVCC visibility rules. When the transaction wants to commit, the database checks whether any of the ignored writes have now been committed. If so, the transaction must be aborted.
注意这种方法只适用于并发写发生在读之前,因为数据库需要跟踪的是那些因为可见性规则被忽略的写操作,如果并发写发生在读之后,是不会有“因为可见性规则被忽略的写操作”的。
Detecting writes that affect prior reads
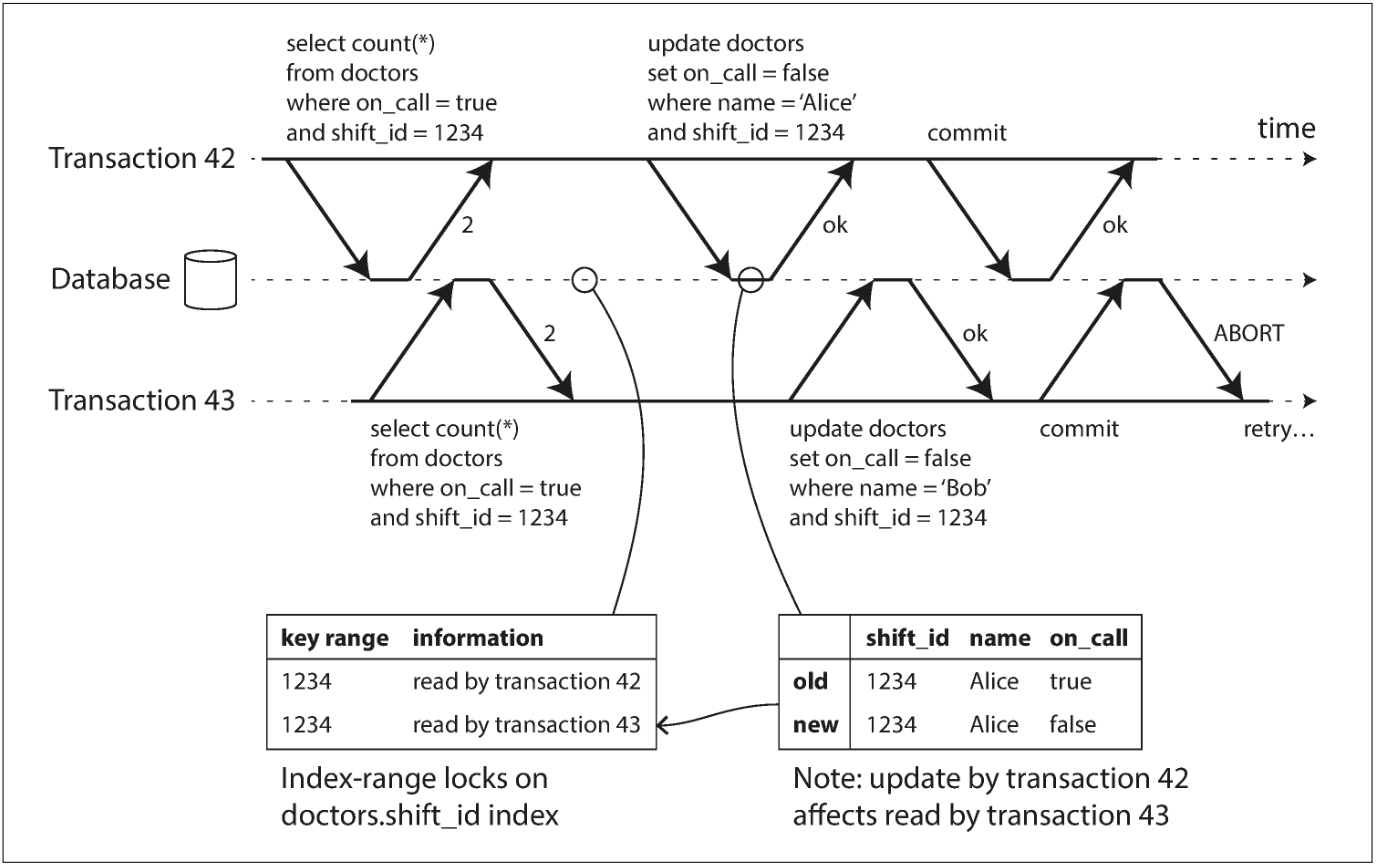
When a transaction writes to the database, it must look in the indexes for any other transactions that have recently read the affected data. This process is similar to acquiring a write lock on the affected key range, but rather than blocking until the readers have committed, the lock acts as a tripwire: it simply notifies the transactions that the data they read may no longer be up to date.
Transaction 43 notifies transaction 42 that its prior read is outdated, and vice versa. Transaction 42 is first to commit, and it is successful: although transaction 43’s write affected 42, 43 hasn’t yet committed, so the write has not yet taken effect. However, when transaction 43 wants to commit, the conflicting write from 42 has already been committed, so 43 must abort.
Performance of serializable snapshot isolation
Compared to two-phase locking, the big advantage of serializable snapshot isolation is that one transaction doesn’t need to block waiting for locks held by another transaction.