向量内积
物理意义
内积本质上是一个向量在另一个向量方向上的投影长度,与基准向量长度的乘积。
- 如果提取特征或求取分量,令 $\mathbf{u}$ 为单位向量($\|\mathbf{u}\| = 1$),则 $\mathbf{v} \cdot \mathbf{u}$ 直接输出 $\mathbf{v}$ 在 $\mathbf{u}$ 方向上的标量投影。
- 工程应用: 在信号处理(如傅里叶变换)中,信号与正交基函数的内积,就是在提取该信号在特定频率上的能量分量。在经典力学中,功的计算 $W = \mathbf{F} \cdot \mathbf{d}$ 就是提取力在位移方向上的有效分量并相乘。
由于内积公式中包含 $\cos(\theta)$,它是衡量高维空间中两个向量方向“一致性”或“对齐程度”的线性算子。
- 当 $\mathbf{a} \cdot \mathbf{b} > 0$ 时,夹角为锐角,两者存在正相关性。
- 当 $\mathbf{a} \cdot \mathbf{b} = 0$ 时,$\cos(\theta) = 0$,两向量正交(垂直)。在工程上,这意味着两个系统、信号或特征完全独立,互不干涉(即协方差为零)。
- 当 $\mathbf{a} \cdot \mathbf{b} < 0$ 时,夹角为钝角,存在负相关性。
- 工程应用: 在机器学习和数据挖掘中,将向量归一化后求内积,即为余弦相似度(Cosine Similarity),常用于衡量文本词向量的语义相似性或推荐系统中用户偏好的匹配度。
向量内积天然满足交换律,即 $\mathbf{a} \cdot \mathbf{b} = \mathbf{b} \cdot \mathbf{a}$,即 $\mathbf{a}$ 投影在 $\mathbf{b}$ 上和 $\mathbf{b}$ 投影在 $\mathbf{a}$ 上的数值是相等的
向量外积
假设有两个列向量 $u \in \mathbb{R}^m$ 和 $v \in \mathbb{R}^n$,它们的外积定义为 $A = u v^T \in \mathbb{R}^{m \times n}$
它的数学与物理意义主要体现在以下两个方面:
秩为1的矩阵(Rank-1 Matrix):矩阵的基本构建块
外积 $u v^T$ 生成的矩阵,其秩(Rank)永远为 1。这意味着矩阵中的每一列都是 $u$ 的线性变换(按 $v$ 的元素缩放),每一行都是 $v^T$ 的线性变换。
在矩阵分解理论(如奇异值分解 SVD)中,任何一个复杂的 $m \times n$ 矩阵都可以被拆解为多个相互正交的秩1矩阵之和(即多个外积之和)。因此,外积是构建任何复杂线性变换矩阵的原子操作。
联想记忆与投影算子(Associative Memory & Projection Operator)
从算子(Operator)视角看,外积构成了一个有向的映射规则。假设我们用矩阵 $A = u v^T$ 去乘一个新向量 $x$:
$$ Ax = (u v^T) x = u (v^T x) $$这里发生了一个非常清晰的工程操作:
- $v^T x$ 是一个标量(内积),计算的是输入 $x$ 与 $v$ 相似度(或在 $v$ 方向上的投影)。
- 然后将这个标量结果作为权重,去缩放向量 $u$。
- 工程结论: 外积 $u v^T$ 本质上编码了一条规则——“当输入中包含 $v$ 的成分时,输出相应的 $u$ 的成分”。这在神经网络中被称为**联想记忆(Associative Memory)**的数学基础。
为什么线性注意力中的 k 和 v 要使用外积
线性注意力(Linear Attention)通过去掉 Softmax(或用核函数特征映射 $\phi(\cdot)$ 替代),利用矩阵乘法的结合律将公式改写为:
$$ \text{Output} = Q (K^T V) $$在这个公式中,$K^T V$ 的本质就是一系列键值向量的外积之和。假设序列中有 $N$ 个 token,第 $i$ 个 token 的键和值分别是列向量 $k_i \in \mathbb{R}^d$ 和 $v_i \in \mathbb{R}^{d_v}$,那么:
$$ S = K^T V = \sum_{i=1}^{N} k_i v_i^T $$累加操作本身保证了全局上下文的感知(没有遗漏),但受限于特征维度 $d$ 的硬性天花板,它牺牲了局部信息的绝对精确解析度(发生了有损压缩)
在这里,$k_i$ 和 $v_i$ 使用外积的根本原因如下:
状态压缩(State Compression)
每一个 $k_i v_i^T$ 都是一个 $d \times d_v$ 的秩1矩阵。它将第 $i$ 个 token 的 $k$(条件/触发器)和 $v$(内容/载荷)绑定在一起,形成了一个局部的映射规则。通过对整个序列的 $N$ 个外积求和($\sum k_i v_i^T$),系统将长度为 $N$ 的序列信息,物理压缩成了一个固定尺寸的 $d \times d_v$ 的状态矩阵 $S$。此时,显存占用从与序列长度相关的 $O(N^2)$ 下降为固定的 $O(d^2)$。
延迟查询的解析(Resolving the Deferred Query)
在这个压缩后的系统状态 $S$ 准备好之后,当一个新的查询特征向量 $q^T$ 试图获取信息时,由于矩阵乘法的线性性质:
$$ q^T S = q^T \left( \sum_{i=1}^{N} k_i v_i^T \right) = \sum_{i=1}^{N} (q^T k_i) v_i^T $$
此时,数学逻辑完美闭环:查询向量 $q$ 首先与状态矩阵中隐含的每一个 $k_i$ 进行内积($q^T k_i$),得到标量相似度,然后再用这个相似度去线性组合对应的 $v_i$。
一个简单具体的例子
为了清晰、直观地展示这个过程,我们设定一个序列长度 $N = 3$ 的极简环境。假设特征维度 $d = 2$,值维度 $d_v = 2$。我们设定以下具体的列向量(你可以把它们想象成神经网络中经过线性层输出的具体的特征数值):
查询向量(Query):
$$ q = \begin{bmatrix} 1 \\ 2 \end{bmatrix} \implies q^T = [1, 2] $$键向量(Keys)与值向量(Values):
- 第 1 个 token:$k_1 = \begin{bmatrix} 1 \\ 0 \end{bmatrix}$,$v_1 = \begin{bmatrix} 1 \\ 1 \end{bmatrix} \implies v_1^T = [1, 1]$
- 第 2 个 token:$k_2 = \begin{bmatrix} 0 \\ 1 \end{bmatrix}$,$v_2 = \begin{bmatrix} 2 \\ 0 \end{bmatrix} \implies v_2^T = [2, 0]$
- 第 3 个 token:$k_3 = \begin{bmatrix} 1 \\ 1 \end{bmatrix}$,$v_3 = \begin{bmatrix} 0 \\ 2 \end{bmatrix} \implies v_3^T = [0, 2]$
下面我们分别用**“先构建状态矩阵 $S$”(等式左边)和“先计算注意力权重”**(等式右边)两种路径来推演,验证它们为何结果完全一致。
路径一:等式左边 $q^T S$(工程上的“线性注意力”正向传播)
这一步的核心是:先不考虑查询 $q$,直接把序列中所有的 $k$ 和 $v$ 压缩成一个系统状态矩阵 $S$。
第一步:计算每个 token 的外积($k_i v_i^T$)。
这是一个列向量乘以行向量,结果是一个 $2 \times 2$ 的矩阵:
$$ k_1 v_1^T = \begin{bmatrix} 1 \\ 0 \end{bmatrix} [1, 1] = \begin{bmatrix} 1 & 1 \\ 0 & 0 \end{bmatrix} $$$$ k_2 v_2^T = \begin{bmatrix} 0 \\ 1 \end{bmatrix} [2, 0] = \begin{bmatrix} 0 & 0 \\ 2 & 0 \end{bmatrix} $$$$ k_3 v_3^T = \begin{bmatrix} 1 \\ 1 \end{bmatrix} [0, 2] = \begin{bmatrix} 0 & 2 \\ 0 & 2 \end{bmatrix} $$第二步:求和得到状态矩阵 $S$。
将这三个 $2 \times 2$ 矩阵直接相加,实现了信息的物理叠加压缩:
$$ S = \sum_{i=1}^{3} k_i v_i^T = \begin{bmatrix} 1 & 1 \ 0 & 0 \end{bmatrix}
- \begin{bmatrix} 0 & 0 \ 2 & 0 \end{bmatrix}
- \begin{bmatrix} 0 & 2 \ 0 & 2 \end{bmatrix} = \begin{bmatrix} 1 & 3 \ 2 & 2 \end{bmatrix} $$
此时,3 个 token 的全部信息已经被压缩到了这个固定的 $2 \times 2$ 矩阵中。
第三步:用 $q^T$ 查询矩阵 $S$。
将行向量 $q^T$ 乘以矩阵 $S$:
$$ q^T S = [1, 2] \begin{bmatrix} 1 & 3 \\ 2 & 2 \end{bmatrix} = [1\times1 + 2\times2, \quad 1\times3 + 2\times2] = \mathbf{[5, 7]} $$路径二:等式右边 $\sum (q^T k_i) v_i^T$(数学上的“标准注意力”逻辑解析)
这一步的核心是:不构建中间矩阵 $S$,而是让查询 $q$ 逐一去和每一个 $k_i$ 计算相似度,再用相似度去加权对应的 $v_i$。
第一步:计算 $q^T$ 与各个 $k_i$ 的内积(相似度标量)。
这是一个行向量乘以列向量,结果是一个标量:
$$ q^T k_1 = [1, 2] \begin{bmatrix} 1 \\ 0 \end{bmatrix} = 1\times1 + 2\times0 = 1 $$$$ q^T k_2 = [1, 2] \begin{bmatrix} 0 \\ 1 \end{bmatrix} = 1\times0 + 2\times1 = 2 $$$$ q^T k_3 = [1, 2] \begin{bmatrix} 1 \\ 1 \end{bmatrix} = 1\times1 + 2\times1 = 3 $$第二步:用标量加权对应的 $v_i^T$。
将上一步得到的相似度(标量)直接乘以对应的行向量 $v_i^T$:
- 权值 $1 \times v_1^T = 1 \times [1, 1] = [1, 1]$
- 权值 $2 \times v_2^T = 2 \times [2, 0] = [4, 0]$
- 权值 $3 \times v_3^T = 3 \times [0, 2] = [0, 6]$
第三步:求和得到最终结果。
将这三个加权后的行向量相加:
$$ \sum_{i=1}^{3} (q^T k_i) v_i^T = [1, 1] + [4, 0] + [0, 6] = \mathbf{[5, 7]} $$在这个例子里,由于 $N(3) > d(2)$,虽然最终结果算出来了,但在路径一的 $S$ 矩阵中,你其实已经无法单纯通过逆运算把原始的 $v_2 = [2, 0]$ 干净地剥离出来了,它们已经在矩阵加法中发生了物理混合。
向量右乘矩阵
$$M\mathbf{v}$$- Shape
- 矩阵: (m, n)
- 向量: (n, 1)
- 结果: (m, 1)
- 代数意义: 矩阵列向量的线性组合
- 当我们计算 $M\mathbf{v}$ 时,实际上是以向量 $\mathbf{v}$ 的各个元素作为权重,对矩阵 $M$ 的各个列向量进行线性加权求和
采用“行列”的方式进行计算,$M$ 的每一列 $M_i$ 在不同的计算轮次中都是与 $v_i$ 进行计算。
- $a_{11}, a_{21}$ 总是和 $v_1$ 相乘
矩阵乘法: B 切分列向量
$$C = AB$$矩阵 $B$ 由 $n$ 个 $k \times 1$ 的列向量 $\mathbf{b}_1, \mathbf{b}_2, \dots, \mathbf{b}_n$ 组成,即:
$$ B = \begin{bmatrix} \mathbf{b}_1 & \mathbf{b}_2 & \dots & \mathbf{b}_n \end{bmatrix} $$当矩阵 $A$ 乘以矩阵 $B$ 时,实际上是矩阵 $A$ 分别去右乘矩阵 $B$ 的每一个列向量。结果矩阵 $C$ 的各个列,正是这些独立乘法的结果:
$$ C = AB = A \begin{bmatrix} \mathbf{b}_1 & \mathbf{b}_2 & \dots & \mathbf{b}_n \end{bmatrix} = \begin{bmatrix} A\mathbf{b}_1 & A\mathbf{b}_2 & \dots & A\mathbf{b}_n \end{bmatrix} $$结果矩阵 $C$ 的第 $j$ 列(即 $A\mathbf{b}_j$),是矩阵 $A$ 的所有列向量的线性组合。
- 矩阵乘列向量得到列向量,计算方式为对矩阵的列做加权求和
- 把 B 矩阵看作列向量集合,B 的第 j 列就是对 A 的列做加权求和,结果存入 C 的第 j 列
矩阵右乘对角方阵
$$C = AD = A \begin{bmatrix} \lambda_1 & 0 & \cdots & 0 \\ 0 & \lambda_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \lambda_n \end{bmatrix}$$效果: 对 A 的列进行缩放
简单推导:
- 向量右乘矩阵 -> 对矩阵的列进行线性组合 -> 向量的各个元素代表对矩阵各个列的加权
- $D$ 每一列中只有一个数值不为 0 -> 只对某一特定的列进行加权
向量左乘矩阵
$$\mathbf{u}^T M$$- Shape
- 向量: (1, m)
- 矩阵: (m, n)
- 结果: (1, n)
- 代数意义: 矩阵行向量的线性组合
- 当我们计算 $\mathbf{u}^T M$ 时,是以行向量 $\mathbf{u}^T$ 的各个元素作为权重,对矩阵 $M$ 的各个行向量进行线性加权求和。
采用“行列”的方式进行计算,$M$ 的每一行 $M_i$ 在不同的计算轮次中都是与 $u_i$ 进行计算。
- $a_{11}, a_{12}, a_{13}$ 总是和 $u_1$ 相乘
矩阵乘法: A 切分为行向量
矩阵 $A$ 由 $m$ 个 $1 \times k$ 的行向量 $\mathbf{a}_1^T, \mathbf{a}_2^T, \dots, \mathbf{a}_m^T$ 组成,即:
$$ A = \begin{bmatrix} \mathbf{a}_1^T \\ \mathbf{a}_2^T \\ \vdots \\ \mathbf{a}_m^T \end{bmatrix} $$当矩阵 $A$ 乘以矩阵 $B$ 时,实际上是矩阵 $A$ 的每一个行向量分别去左乘矩阵 $B$。结果矩阵 $C$ 的各个行,正是这些独立乘法的结果:
$$ C = AB = \begin{bmatrix} \mathbf{a}_1^T \\ \mathbf{a}_2^T \\ \vdots \\ \mathbf{a}_m^T \end{bmatrix} B = \begin{bmatrix} \mathbf{a}_1^T B \\ \mathbf{a}_2^T B \\ \vdots \\ \mathbf{a}_m^T B \end{bmatrix} $$结果矩阵 $C$ 的第 $i$ 行(即 $\mathbf{a}_i^T B$),是矩阵 $B$ 的所有行向量的线性组合
- 行向量乘矩阵得到行向量,计算方式为对矩阵的行做加权求和
- 把 A 矩阵看作行向量集合,A 的第 i 行就是对 B 的行做加权求和,结果存入 C 的第 i 行
矩阵左乘对角方阵
$$C = DA = \begin{bmatrix} \lambda_1 & 0 & \cdots & 0 \\ 0 & \lambda_2 & \cdots & 0 \\ \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & \cdots & \lambda_n \end{bmatrix} A$$效果: 对 A 的行进行缩放
简单推导:
- 向量左乘矩阵 -> 对矩阵的行进行线性组合 -> 向量的各个元素代表对矩阵各个行的加权
- $D$ 每一行中只有一个数值不为 0 -> 只对某一特定的行进行加权
矩阵乘法
TODO
L_2 误差
$L_2$ 误差($L_2$ Error,或基于 $L_2$ 范数的误差)是一种用于衡量两个向量、矩阵或张量之间差异的标准指标。在几何意义上,它等价于多维空间中的欧几里得距离
给定一个真实值张量 $Y$ 和一个预测值(或近似值)张量 $\hat{Y}$,假设它们被展平为包含 $n$ 个元素的向量。$L_2$ 误差的计算方式是将它们对应位置元素的差值进行平方,然后求和,最后对总和开平方根。其标准的数学公式表示为:
$$ E = \|Y - \hat{Y}\|_2 = \sqrt{\sum_{i=1}^{n} (Y_i - \hat{Y}_i)^2} $$平方的特性:使得正负误差不会相互抵消,且由于平方项的存在,它会对较大的个别偏差施加极其严厉的惩罚(例如,差值为 2 的惩罚是 4,而差值为 10 的惩罚高达 100)。
ML
Linear
nn.Linear(in_features=m, out_features=n)
如果输入向量 $x$ 的形状是 $(1, m)$,你想得到一个形状为 $(1, n)$ 的输出 $y$,逻辑上最自然的权重矩阵 $W_{\text{logical}}$ 形状就应该是 $(m, n)$。此时公式就是完美的 $y = xW_{\text{logical}}$
在 PyTorch 中,当我们实例化一个标准的线性层 nn.Linear(in_features=m, out_features=n) 时,它在底层初始化的权重矩阵 $W_{physical}$(即 layer.weight)的形状并不是 $(m, n)$,而是 $(n, m)$。
所以为了方便理解,公式可以写为
$$y = x W_{physical}^\top$$因为 PyTorch 底层按照 row-major 的顺序在连续的内存空间中存储多维数组
- 如果按逻辑形态存为 $(m, n)$,计算第 $i$ 个神经元时就需要跨步(Stride)去读取矩阵的第 $i$ 列,这会导致非连续的访存跳跃,严重拖慢计算速度
- 如果物理权重存储为 $(n, m)$,那么这矩阵的第 $i$ 行刚好包含了这 $m$ 个所需的权重,且它们在物理内存中是完全连续的
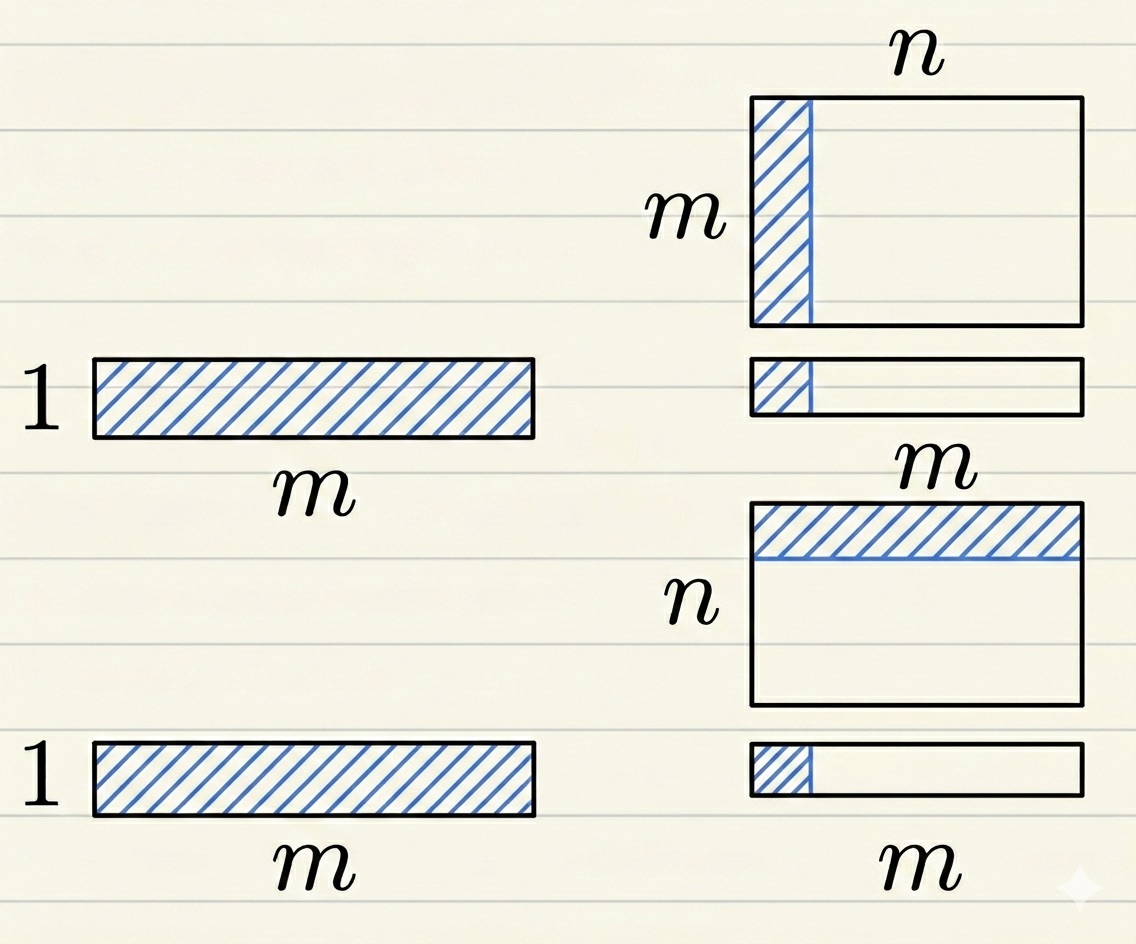
- 在传统的线性代数中,数据点默认被定义为列向量 (m, 1),为了让结果为 (n, 1), W 的 shape 就应该为 (n, m)
- $y = Wx$
- 在深度学习时代,多条数据被习惯性地按照行堆叠存放,每个数据变为了行向量: (1, m)
- 将 $y = Wx$ 的两边同时转置,就得到了 $y^\top = x^\top W^\top$。这也是 $y = xW^\top$
- x: (1, m)
- $W^\top$: (m, n)