Kernel Paradigm
triton 的 kernel 有两种写法:
- 传统 kernel
- Persistent Kernel
传统 Kernel
grid = (num_tiles,)
每个 block 处理一个 tile → 结束
每个 SM 从 grid 里领一个 work item,做完就退出, CTA 调度由硬件自动完成
Persistent Kernel
@triton.jit
def kernel(..., n_tiles: tl.constexpr, ...):
pid = tl.program_id(0)
n_progs = tl.num_programs(0) # grid(0) 启动的 program 数
tile = pid
while tile < n_tiles:
# 处理 tile 对应的那一块工作
# ...
tile += n_progs # 跳到下一个属于自己的 tile
每个 CTA 长期驻留在 SM 上,自己软件调度 work
persistent kernel 常见动机:
任务总 tile 数不够多(比如小 batch、小矩阵、很多小 GEMM / MoE / grouped GEMM):普通写法 programs 数 < SM,GPU 吃不满;persistent 让每个 SM 都有活干,并通过循环把剩余工作吃完。
减少 launch / 调度开销: 不是启动成千上万个短命 programs,而是少量长命 programs,尤其在大量小任务时可能更划算。
更好的 locality / cache 复用(有时): 同一批常驻 programs 反复处理相邻/相关的 tile,有机会提高 L2/共享数据的命中(取决于你的访问模式)。
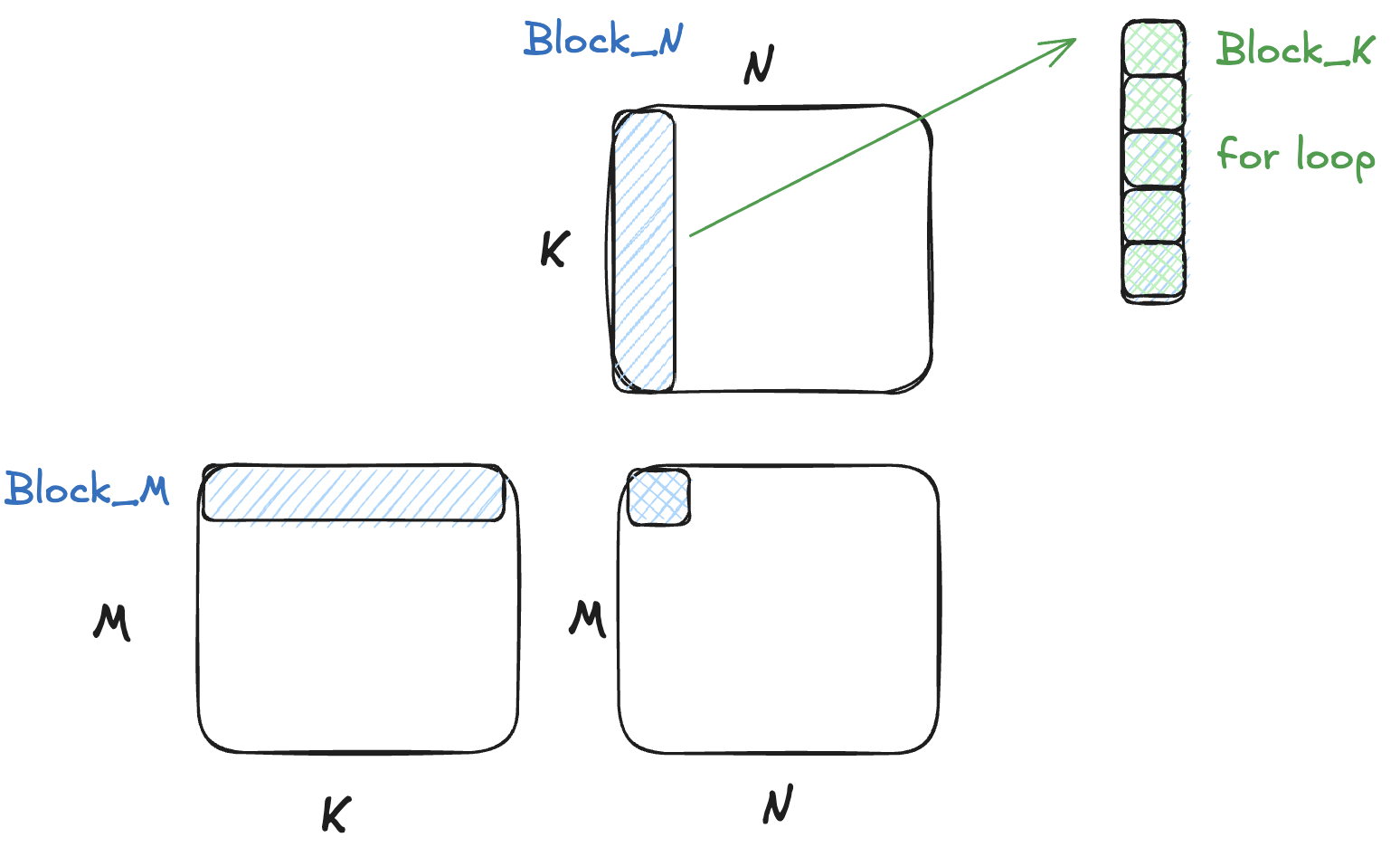
GEMM
对矩阵来说,就是将其外围维度使用 PID 并行划分,最后一个维度采用 for loop 的方式分布处理
- 前者是为了最大化并行度
- 后者是为了控制加载到单个 SM 中的数据
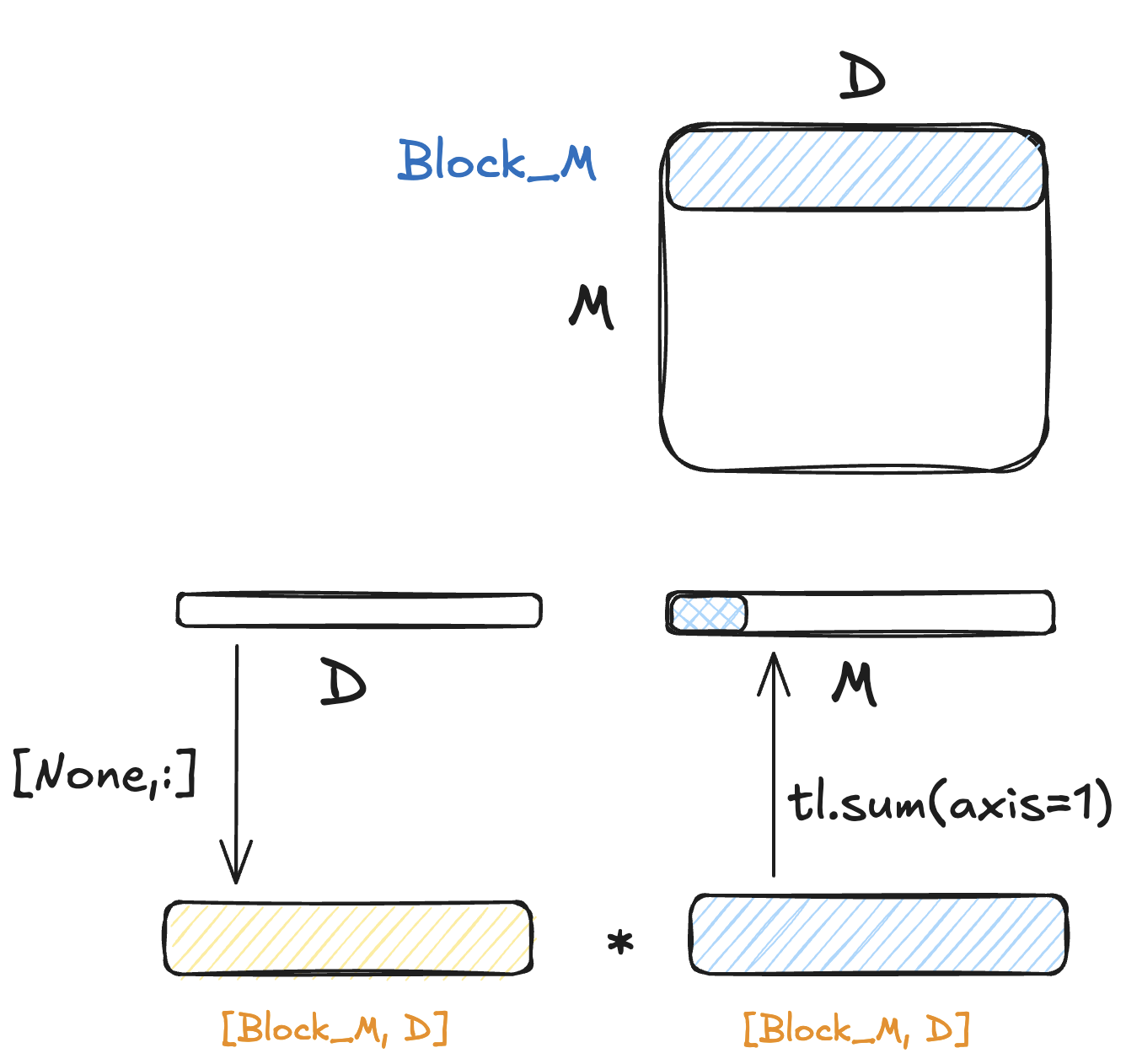
GVMM
仍然是对矩阵外围维度通过 PID 进行划分
计算时不通过矩阵方法:
- 先把向量延展到相同形状
- 进行 element-wise product
- 再通过 tl.sum 进行缩减