FAQ
What is a single-row transaction?
在 Bigtable 变更(例如读取、写入和删除请求)中,行级更改始终属于原子操作。这包括对单行中的多个列进行的变更,前提是它们包含在同一变更操作中。Bigtable 不支持以原子方式更新多个行的事务。
但是,Bigtable 支持某些需要在其他数据库中执行事务的写入操作。实际上,Bigtable 使用单行事务来完成这些操作。这些操作包括读取和写入操作,且所有读取和写入均以原子方式执行,但仍然只是在行级的原子操作:
- 读取-修改-写入 (Read-modify-write) 操作(包括增量和附加)。在读取-修改-写入 (read-modify-write) 操作中,Cloud Bigtable 会读取现有值,对现有值进行增量或附加操作,并将更新后的值写入表中。
- 检查并更改 (Check-and-mutate) 操作(也称为条件更改或条件写入)。在检查并更改 (check-and-mutate) 操作中,Bigtable 会对行进行检查以了解其是否符合指定条件。如果符合条件,Bigtable 则会将新值写入该行中。
What is SSTable format?
SSTable (Sorted Strings Table) is a file format used in Apache Cassandra, a popular NoSQL database. An SSTable is a data structure that provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte streams. It contains a series of key-value pairs sorted by keys, which enables efficient lookup and range queries. It’s used to store and retrieve data in a highly optimized manner. The SSTable also supports internal indexing, which makes accessing a particular data point faster.
Analyze
Key Features
- A distributed storage system for managing structured data
- Scalability
- High performance
- High availability
Basic Structures
Data View
- A Bigtable cluster stores a number of tables.
- Each table consists of a set of tablets.
- Each tablet contains all data associated with a row range.
- Each row range is called a tablet, which is the unit of distribution and load balancing.
- The Google SSTable file format is used internally to store Bigtable data.
- Each SSTable contains a sequence of blocks (typically each block is 64 KB in size, but this is configurable). A block index (stored at the end of the SSTable) is used to locate blocks.
System View
- Bigtable uses the distributed Google File System (GFS) to store log and data files.
- Bigtable relies on a highly-available and persistent distributed lock service called Chubby.
- to ensure that there is at most one active master at any time
- to store the bootstrap location of Bigtable data
- to discover tablet servers and finalize tablet server deaths
- to store Bigtable schema information (the column family information for each table)
- to store access control lists
Three components:
- A library that is linked into every client.
- One master server.
- Many tablet servers.
The master is responsible for assigning tablets to tablet servers, detecting the addition and expiration of tablet servers, balancing tablet-server load, and garbage collection of files in GFS.
Each tablet server manages a set of tablets (typically we have somewhere between ten to a thousand tablets per tablet server).
Basic Operations
Locate a Tablet
有点像多级页表的结构:Chubby 中存储了 Root tablet 的位置信息,Root tablet 中存储了其他 METADATA tablet 的位置信息,METADATA tablet 中存储了所有其他 User Table 的信息。
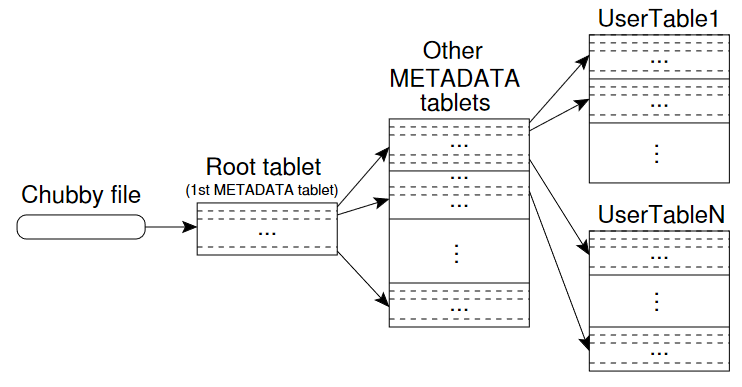
用户端会缓存 tablet 的位置信息,如果一开始没有,就会沿着上图的这个结构层次去寻找。
Tablet Assignment
Bigtable uses Chubby to keep track of tablet servers. When a tablet server starts, it creates, and acquires an exclusive lock on, a uniquely-named file in a specific Chubby directory. The master monitors this directory (the servers directory) to discover tablet servers.
When a master is started:
- The master grabs a unique master lock in Chubby.
- The master scans the servers directory in Chubby to find the live servers.
- The master communicates with every live tablet server to discover what tablets are already assigned to each server.
- The master scans the METADATA table to learn the set of tablets.
- Whenever this scan encounters a tablet that is not already assigned, the master adds the tablet to the set of unassigned tablets, which makes the tablet eligible for tablet assignment.
Read Request

Steps:
- Check for well-formedness and proper authorization.
- Seek in memtable
- If not found, seek in SSTable Files from new to old. First use bloom filter to decide whether the data resides in the file, if true, look into the sparse index to find an approriate block, then perform a disk read.
Write Request
Steps:
- Check for well-formedness and proper authorization.
- A valid mutation is written to the commit log.
- After the write has been committed, its contents are inserted into the memtable.
Compactions
Three kinds of compactions are mentioned:
- minor compaction
- When the memtable size reaches a threshold, the memtable is frozen, a new memtable is created, and the frozen memtable is converted to an SSTable and written to GFS.
- merging compaction
- A merging compaction reads the contents of a few SSTables and the memtable, and writes out a new SSTable.
- major compaction
- A merging compaction that rewrites all SSTables into exactly one SSTable.
Performance
Locality groups
Clients can group multiple column families together into a locality group. A separate SSTable is generated for each locality group in each tablet.
For example:
Page metadata in Webtable can be in one locality group, and the contents of the page can be in a different group: an application that wants to read the metadata does not need to read through all of the page contents.
Caching for read performance
Two levels of caching:
- The Scan Cache
- caches the key-value pairs returned by the SSTable interface to the tablet server code.
- useful for applications that tend to read the same data repeatedly.
- The Block Cache
- caches SSTables blocks that were read from GFS.
- useful for applications that tend to read data that is close to the data they recently read.
Commit-log implementation
原本是每个 tablet 都有自己的提交日志,这样对底层的 GFS 不友好,相当于每时每刻都在做大量不同文件的顺序写操作(某种程序上就相当于是随机写了),破坏了 SSTable 顺序写的特性,会造成严重的性能开销。
所以作者决定每一台 tablet server 只有一个提交日志,即所有的 tablets 共享该日志。有一个问题是当服务器失效后,假设有其他 100 台服务器要重新分配之前的 tablets,那么这个日志就会被读取 100 次。解决方法就是按照 〈table, row name, log sequence number〉 先排个序,这样每个服务器就只会读相应的一部分。
所以在 minor compaction 时,当 memtable 写入到磁盘时 commit log 并不会被清空,而是更新 redo point,即重新记录该 tablet 的 memtable 对应的日志开始的地方。重建 memtable 时就从 redo point 那里开始重新应用对应的更改。