FAQ
Is chain replication used in practice over other things like Raft or Paxos?
Systems often use both.
A common way of building distributed systems is to use a configuration server (called the master in the paper) for maintaining configuration info (e.g., who is primary) and a replication system for replicating data.
Paxos/Raft are commonly-used to build the configuration server while the replication system often uses primary-backup or chain replication.
The reason to use Raft/Paxos for configuration server is it must handle split-brain syndrome.
The reason to use primary/backup for data replication is that it is simpler than Raft/Paxos and Raft, for example, is not good at for replicating large amounts of data. The replication system can rely on the configuration server to avoid split-brain syndrome.
What are the tradeoffs of Chain Replication vs Raft or Paxos?
Both CR and Raft/Paxos are replicated state machines. They can be used to replicate any service that can fit into a state machine mold (basically, processes a stream of requests one at a time).
CR is likely to be faster than Raft because the CR head does less work than the Raft leader: the CR head sends writes to just one replica, while the Raft leader must send all operations to all followers. CR has a performance advantage for reads as well, since it serves them from the tail (not the head), while the Raft leader must serve all client requests.
However, Raft/Paxos and CR differ significantly in their failure properties:
- Fault Tolerant
- If there are N replicas, a CR system can recover if even a single replica survives.
- Raft and Paxos require a majority of the N replicas to be available in order to operate.
- Handle Faults
- A CR chain has to pause updates if there’s even a single failure, and must wait for the configuration server to notice and reconfigure the chain.
- Raft/Paxos, in contrast, can continue operating without interruption as long as a majority is available.
This scheme would be bad if we care about latency right?
Yes and No.
- Yes, the latency of update operations is proportional to the length of the chain.
- No, the latency of read operation is low: only the tail is involved.
Analyze
Key Features
- The approach is intended for supporting large-scale storage services that exhibit high throughput and availability without sacrificing strong consistency guarantees.
- Chain replication supports high throughput for query and update requests, high availability of data objects, and strong consistency guarantees.
Basic Structures
System View
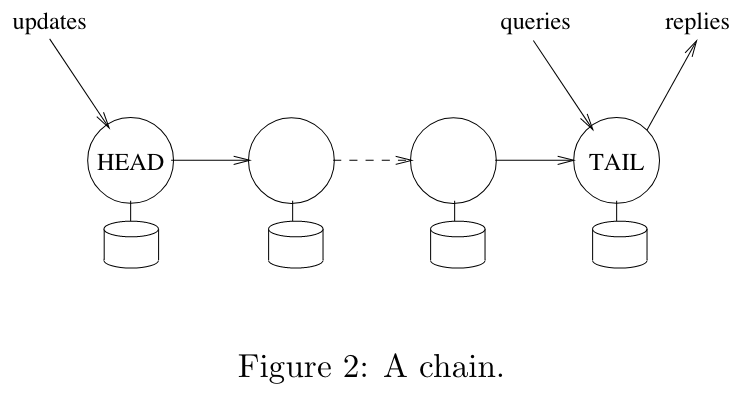
可以说这篇论文中最重要的一张图就是这个了,这张图至少说明了三个特性:
- 所有的 query 都只经过 tail。
- 所有的 reply 都由 tail 产生。
- 所有的 update 请求都需要从 head 开始处理,经过一条链最终到达 tail。
这个结构也说明了为什么链式复制拥有这高性能这一特性:
- 相比于平常的 Primary/Backup 的复制机制,链式复制将 master 的负载分担到了 head 和 tail 两台服务器的身上,所以能更快。
Protocol View
链式复制需要建立在 Fail-stop 的基础上:
- Each server halts in response to a failure rather than making erroneous state transitions. (很明显的 CP 系统)
- A server’s halted state can be detected by the environment.
简单的运行逻辑已经在 System View 中说明了,有一点需要提出来说的是,这个系统是如何保证强一致性的呢?
Strong consistency thus follows because query requests and update requests are all processed serially at a single server (the tail).
Fault Tolerance
作者假设了一个永不失败的 master,拥有以下职责:
- Detects failures of servers.
- Informs each server in the chain of its new predecessor or new successor in the new chain obtained by deleting the failed server.
- Informs clients which server is the head and which is the tail of the chain.
可以把这个 master 想成一个 Paxos/Raft 构成的集群。
master 能够检测三种类型的异常:
- 头结点异常
- 尾节点异常
- 中间节点异常
作者提到了一个更新传播不等式(Update Propagation Invariant): 对于满足 $i \le j$ 的节点 $i$ 和 $j$ (即 $i$ 在链中是 $j$ 的前继节点),有
$$ Hist^j_{objID} \preceq Hist^i_{objID} $$
$Hist^i_{objID}$ 代表的是 $i$ 通过的 update 请求序列。 这个不等式在原文中给我看迷糊了,其实很简单,就是说 $j$ 的请求序列是 $i$ 的一个前缀。(即每个节点收到的更新序列是前一个节点收到的更新序列的前缀。)
如果该更新传播不等式在系统中成立,那么就能说明 head 处理的更新序列和 tail 处理的更新序列顺序上是一致的,也就能保证整个系统维持了线性一致性。
Failure of the Head
This case is handled by the master removing H from the chain and making the successor to H the new head of the chain.
删除 head 会导致 $Pending_{objID}$ 发生变化($Pending_{objID}$ 指的是被服务器接收但是还没有被 tail 处理的更新请求序列)。从 $pending_{objID}$ 中移除一个请求和 Figure 1 中的 T2 是一致的,所以删除 head 与 Figure 1 中的说明是一致的。
Failure of the Tail
This case is handled by removing tail T from the chain and making predecessor T− of T the new tail of the chain.
这种操作和 Figure 1 中的 T3 是一致的。
Failure of Other Servers
Failure of a server S internal to the chain is handled by deleting S from the chain. The master first informs S’s successor S+ of the new chain configuration and then informs S’s predecessor S−.
需要注意的是,这种情况有可能会违反之前提到的更新传播不等式,进而破坏系统的线性一致性。
这里就细说一下什么情况下会破坏该一致性:
假设有 H –> S1 –> S2 –> S3 –> T,最重要的是要理解:如果 S2 挂了,S1 是不知道 S2 和 S3 之间的发送情况的,假设 S1 给 S2 发了 5 条请求,而 S2 给 S3 发了 3 条请求,如果没有一个记录来维护发送情况,S1 就会直接给 S3 发送新的第 6 条请求,最终导致:
- S1 :[1,2,3,4,5,6]
- S2 :[1,2,3,6]
- S2 不再是 S1 的一个前缀。
为了解决这个问题,作者提出了在每个节点再维护一个序列 $Sent_i$,$Send_i$ 中存储的是那些 $i$ 向后继节点转发了但是还没有被 tail 处理的更新请求序列,这个序列的变化规则就很明显了:
- 每次 $i$ 向后继节点转发一个请求,就在 $Sent_i$ 中添加一个该请求。
- tail 每处理一个请求,就会往前继节点发送一个 $ack(r)$,前继节点收到 $ack(r)$ 后,就在 $Sent_i$ 中删除一个该请求。
举个对应前面例子:
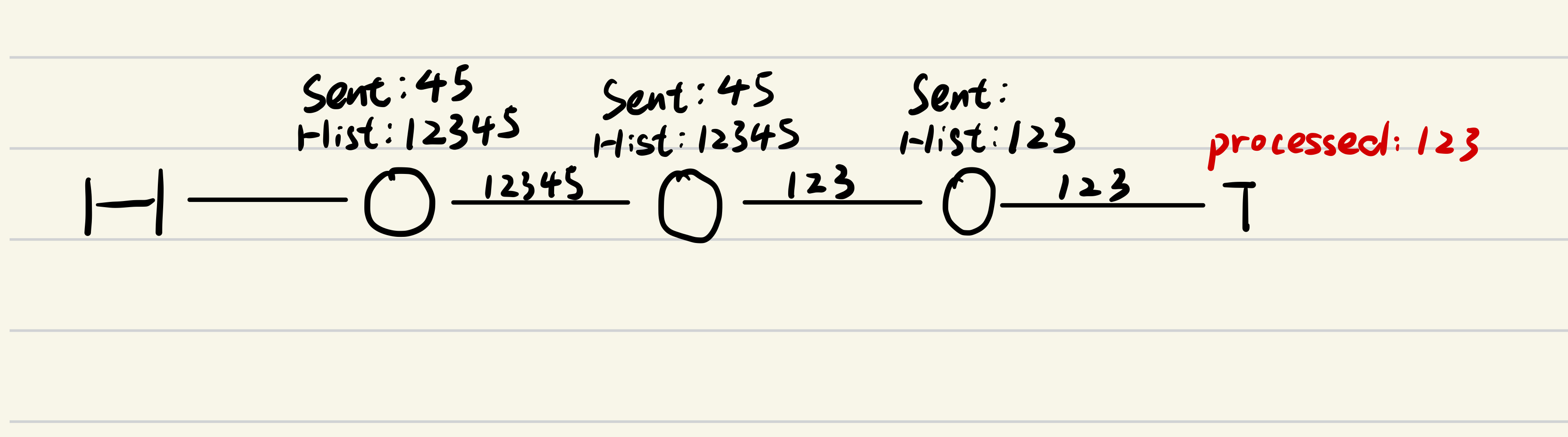
所以可以总结一个规律:对于满足 $i \le j$ 的节点 $i$ 和 $j$,有 $i$ 的更新序列等于 $j$ 的更新序列和 $Sent_i$ 的补集,在论文中体现为 Inprocess Request Invariant。
这个不等式就为如何维护更新传播不等式提供了指导性意见:
- S- 收到了 S+ 是它的新后继节点这一信息后,首先把 $Sent_{S^-}$ 中的请求序列转发给 S+。
所以整个更新流程可以如下图(具体的其他细节在这里就省略了):

- Message 1 informs S+ of its new role;
- Message 2 acknowledges and informs the master what is the sequence number $sn$ of the last update request S+ has received;
- Message 3 informs S− of its new role and of $sn$ so S− can compute the suffix of $Sent_{S^-}$ to send to S+;
- Message 4 carries that suffix.
Extend a Chain
新增的节点 $T^+$ 增加在链尾,在同步完成前先不提供查询服务,将 $Hist^T_{objID}$ 全量复制到 $Hist^{T^+}_{objID}$,由于复制的时间可能很长,原本的尾部 $T$ 因此还并发地承担之前的责任以确保可用性,但是将这段时间的更新同时增加到 $Sent_T$,直到全量复制完成。
之后,$T$ 将之后的查询请求丢弃或者转发给新的链尾 $T^+$ ,并把已有的 $Sent_T$ 的请求发送给 $T^+$。然后 master 通知 client 新的链尾,并让它直接访问 $T^+$。
Primary/Backup Protocols
In the primary/backup approach, one server, designated the primary
- imposes a sequencing on client requests (and thereby ensures strong consistency holds).
- distributes (in sequence) to other servers, known as backups, the client requests or resulting updates.
- awaits acknowledgements from all non-faulty backups.
- after receiving those acknowledgements then sends a reply to the client.
With chain replication, the primary’s role in sequencing requests is shared by two replicas.
- The head sequences update requests.
- The tail extends that sequence by interleaving query requests.
链式复制的一个缺点就是延时会更高,并且随着链长度的增加,延时也会成比例的线性增加。
Chain replication does this dissemination serially, resulting in higher latency than the primary/backup approach where requests were distributed to backups in parallel.
但是在错误处理上,链式复制所需要的时间会更短,论文中有详细的分析,这里就不多赘述了。
Summary
链式复制是一个相对比较简单的协议,支持高吞吐,高可用以及强一致性,是一个 CP 系统,而链式复制做出的取舍就是增加了时延。
CR 能够以很简单的设计实现多副本的线性一致性,不过其不能自己处理脑裂和分区的问题,因而还需要另一个高可用的配置服务器集群来协作提供高可用服务。