FAQ
What is polyglot persistence principle?
Polyglot Persistence is a term coined by Martin Fowler and Pramod Sadalage to describe the concept of using different data storage technologies to handle varying data storage needs within a given application. The principle behind polyglot persistence is that no single database can serve all needs of a modern application. Different kinds of data are best dealt with different types of databases. For example, you might use a relational database such as MySQL for transaction data, a NoSQL document store like MongoDB for semi-structured data, and a graph database like Neo4j for relationships between entities. Instead of trying to make one data storage technology work for all types of data, you use the type of database that is best suited for each particular need. This approach can result in a system that’s more scalable, performant, and easier to work with. Polyglot Persistence represents a shift away from the traditional, one-size-fits-all database strategy, allowing for a more flexible and optimized approach to data management.
What is the difference between table and schema in database systems?
In a database system, both “tables” and “schemas” are essential components, but they serve different purposes.
- A “table” is where data is stored. It consists of rows (records) and columns (fields). Each table in a database holds data about a specific topic or subject, such as customers, products, or employees. For example, an “Employees” table might include columns for Employee ID, Name, Position, and Salary.
- A “schema”, on the other hand, is a higher-level organizational construct that groups related tables and other database objects together within a database. It is essentially a namespace: it allows the same table name to be used in different schemas within the same database without conflict. It also serves as a security boundary, where permissions can be given to manipulate the data within the schema.
In other words, a schema is like a container of tables in a database. A database can have multiple schemas, and each schema can have multiple tables. For instance, in a university database, you might have a “Students” schema with tables like Personal_Information, Courses_Enrolled, etc., and a “Faculty” schema with tables like Personal_Information, Courses_Taught, etc.
What is The Back-end for Front-end Pattern (BFF)?
The Back-end for Front-end (BFF) Pattern is a design pattern introduced by Phil Calçado, and it’s often used in microservices architectures. The idea behind this pattern is to create a separate back-end service specifically designed to be the front-end’s own “best friend”. In other words, rather than having the front-end of your application interact directly with multiple microservices, you create a single back-end service that’s designed specifically to provide the data in the format that the front-end needs. This back-end service interacts with the microservices to gather this data, and then returns it to the front-end. This pattern is particularly useful when you have different types of front-ends (like mobile, web, desktop) that need the data in different formats. Instead of trying to make your microservices cater to all these different needs, you have separate BFFs for each type of front-end, simplifying your microservices and reducing the dependencies between front-ends and back-ends. BFF provides several benefits such as improving performance by minimizing data processing on the client side, reducing complexity for client developers as they deal with a single API tailored to their needs, and allowing for better scaling since each BFF can evolve based on specific client requirements.
Summary
这是一篇关于微服务系统下数据管理的综述。
STATE OF THE PRACTICE
这一节首先讲了从数据管理的角度来说,为什么大家会采用微服务架构。

- Functional partitioning
- To support scalability (i.e., spreading functional groups across databases) and high data availability (i.e., achieving functional isolation of errors), functional decomposition of the application is a major driver for adopting microservices.
- Decentralized data management
- The ability of microservice architectures to provide independently-evolving schemas in different services, in contrast with the unified schema of monolithic architectures, is another major driver.
- Event-driven microservices
- Event-driven systems constitute an emerging trend in the design of data-driven software applications.
There are three mainstream approaches for using database systems in microservice architectures:
- Private tables per microservice, sharing a database server and schema.
- Schema per microservice, sharing a common database server.
- Database server per microservice.
绝大多数从业者喜欢第三种方式,这能带来以下优势:
- Achieving loosely-coupled microservices.
- Independent data layer scalability.
- Fault-isolation.
Practitioners, literature, and open-source repository analysis indicate that container-based deployment is the de-facto practice. Each microservice and respective database are bundled in separate containers, thus guaranteeing that each can be scaled independently and faults are limited to the container boundary.
在谈到哪些数据库系统被使用时,有半数的从业者谈到至少是一个关系型数据库和 MongoDB。同时,下列技术栈也十分流行:
- A relational DBMS (e.g., PostgreSQL, MySQL, or SQL Server)
- Redis
- MongoDB
- ElasticSearch
DATA MANAGEMENT LOGIC IN PRACTICE
在对开源项目和其他相关研究进行分析后,工作发现 “there is no evidence of the use of stored procedures or the configuration of databases in serializable isolation.”
对于各个微服务之间的协调,大体上有以下的几种方式:
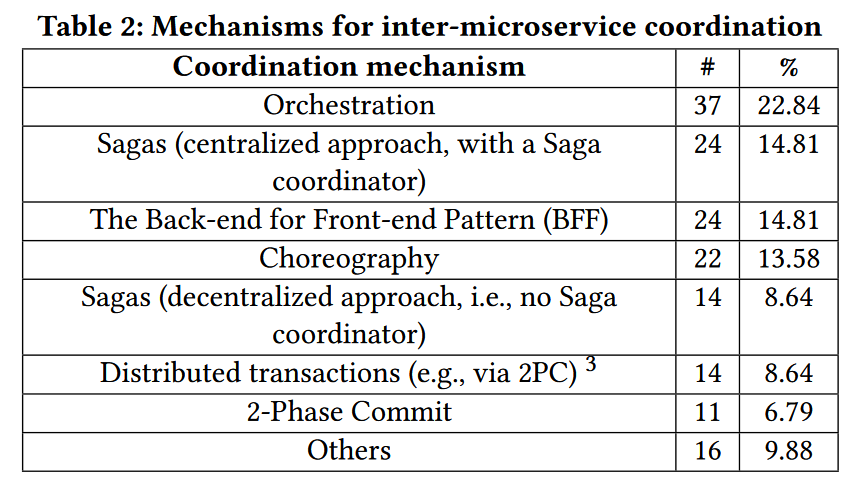
Distributed commit protocols do not enjoy popularity in microservices. The lack of effective and intuitive application abstractions may play a role in refraining practitioners from adopting such protocols.
工作也对那些需要跨多个微服务之间的查询的处理办法做了总结:
- Queries aggregating data belonging to different microservices
- In this mechanism, a consumer service contacts, often through HTTP requests, a set of microservices through their APIs. After receiving all responses, the consumer service then aggregates the data in-memory (also performing joins, if necessary) and serves the client.
- Replication
- The use of ad-hoc mechanisms for data replication across microservices for online querying purposes.
- Replication across microservices
- This practice is characterized by a microservice generating events related to its own updated data items and communicating these changes asynchronously, often through persistent messaging supported by a message broker.
- Replication to a database
- Daemon workers, one for each microservice and its respective generated events, or a central service, are responsible for subscribing to data item updates and replicating these to a special-purpose database used for querying.
- Batch workers (usually special-purpose microservices) to extract data from microservices periodically (with a pull-oriented strategy) and replicate those in a neutral data repository for fast querying.
- The use of data stream processing systems
- Replication across microservices
- The use of ad-hoc mechanisms for data replication across microservices for online querying purposes.
- Views
- When microservices share the same database, practitioners may rely on views across multiple schemas to serve crossmicroservice queries.
The results highlight that the decentralized data management principle does not refrain microservices from performing queries over distributed states. As a result, practitioners often rely on ad-hoc mechanisms for data processing at the application level.