FAQ
What is a deterministic database?
A deterministic database is a system where the outcomes of any database operations are guaranteed to be the same every time they are executed, provided that the operations are started from the same database state. This concept implies a level of reliability and predictability in the behavior of the database system.
Deterministic behavior is essential in many contexts, especially in distributed databases, where operations might need to be coordinated across multiple nodes, or in any system where replication, fault tolerance, and consistency are important. If a database operation is deterministic, it means the following:
- Consistency: The same operation will always result in the same state change and the same output when applied to the same initial state.
- Repeatability: If an operation is performed multiple times with the same input, it will produce the same result each time.
- Concurrency Control: Determinism can simplify concurrency control, as the outcome of transaction execution is predictable. This reduces the likelihood of conflicts between transactions and can help ensure serializability.
- Fault Tolerance: In systems that require fault tolerance, such as distributed databases, deterministic operations can make it easier to replicate data across multiple nodes. If a node fails, another node can recreate the exact sequence of operations to reach the current state, ensuring data integrity.
Determinism in database systems is usually achieved by using strictly defined schemas, stored procedures, constraints, triggers, and transaction isolation levels that enforce the ACID properties (Atomicity, Consistency, Isolation, Durability) of database transactions.
Can you give some examples of deterministic database systems?
Deterministic database systems are typically not advertised with “deterministic” as a defining feature, as most traditional relational database management systems (RDBMS) aim for consistency and determinism in their operation. A few databases (including NewSQL databases) and distributed systems, however, emphasize determinism as a core component of their design to ensure data consistency and fault tolerance, especially in a distributed environment.
Introduction
Background
- How to support consistent distributed transactions in scale-out databases is a well-known challenge, and is even more challenging in a microservice architecture.
- 2PC does not work well in large-scale high-throughput systems. The reason is that locks are held during the entire 2PC process that significantly increase the transaction conflicts and latency.
GRIT leverages some deterministic ideas, such as ordering transactions in Paxos-based logs before execution.
Structure
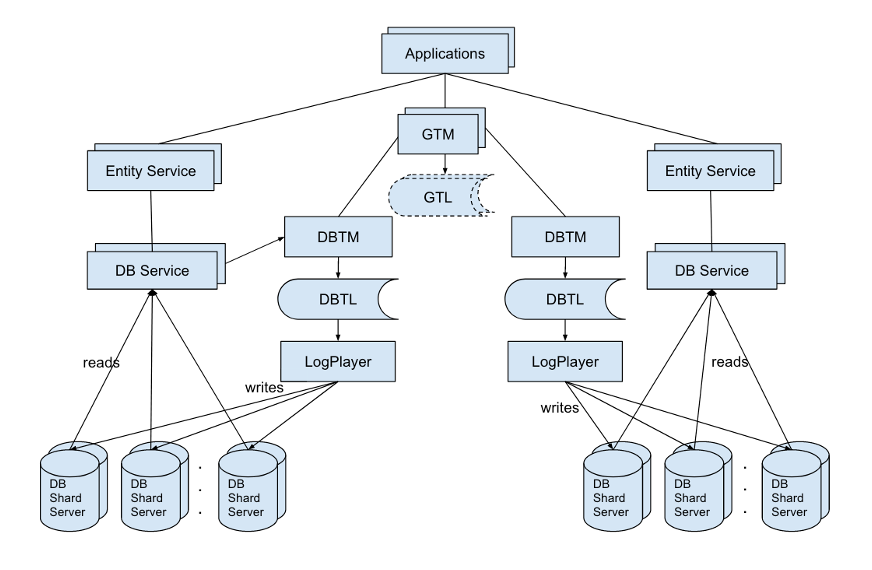
Components:
- GTM: Global Transaction Manager
- GTL: Global Transaction Log
- DBTM: Database Transaction Manager
- DBTL: Database Transaction Commit Log
- Log Player: Push commit log entries to database
- DB Shard Server
- DB Service: caches read/write set, send them to DBTM
Implementation
“We do not expand this flow here.”
The GRIT system is in production in eBay, so I guess some of the implementations might involve the company’s insterests, many detais are missing.
Transaction

Three Phases:
- Optimistic Execution Phase:
- Do business logic, while DB Service captures read/write sets (with version info)
- Logical Commit Phase:
- At a DB Level:
- Conflict Resolution
- If the transaction involves more than one database, commit decision should be made globally
- At Global Level: Make the global commit decision
- At a DB Level:
- Physical materialization Phase:
- Log player will steam log entries sequentially to target database, and transaction writes are deterministically executed following the transaction order in the DB level transactions logs (DBTLs).
- This process is done asynchronously.
Details
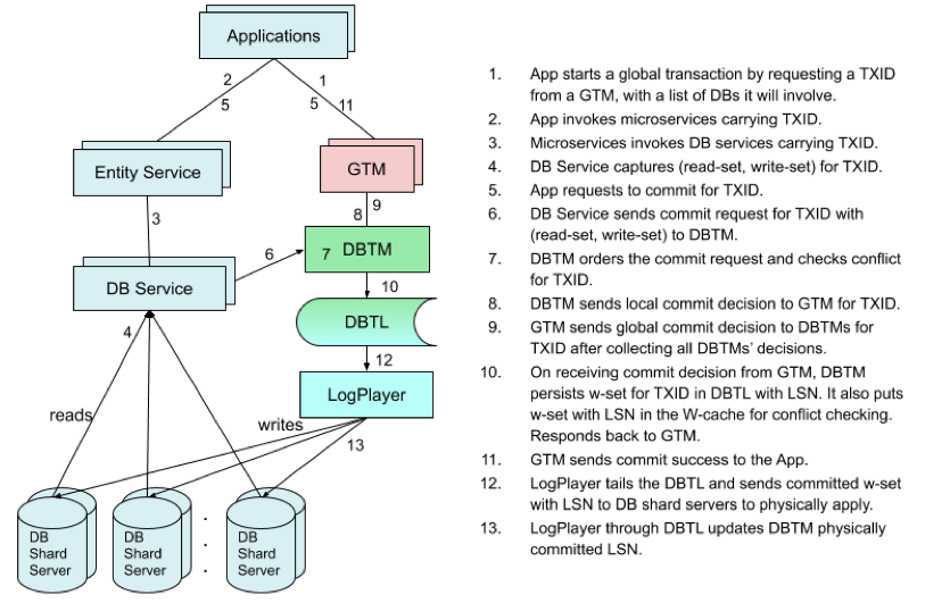
Details:
- Use snapshot to solve wr-conflicts.
- Use version info to solve ww-conflicts.
- Use DBTM’s conflict resolution to solve rw-conflicts.
- The log player asynchronously sends DBTL entries to backend storage servers.
- Avoid pessimistic locking during both execution and commit process and avoid waiting for physical commit.
Conflict resolution:
The goal of conflict checking is to see if there is any other transaction that has changed an entry since the transaction read it.
So basically it iterates the write set to see any of them has been changed.
Conflict checking at a DBTM is sufficient with the cache of w-sets from all the recently committed transactions, as long as all the updates go through the same DBTM for the covered scope of the database.
Conclusions
Highlights
- A mechanism similar to 2PC but apply at logical commit phase, which avoids longer duration.
- The key for the scalability and performance is the techniques to avoid coordination during execution phase as well as transaction materialization (physical commit) that are of relatively longer duration.
- Take advantage of deterministic database engines.