Extensive Reading
Author Info
Background
混合CPU(如包含性能核P-core和能效核E-core的CPU)由于其核心硬件能力不均衡 ,导致在运行AI推理任务时性能低下。传统的并行计算方法会平均分配工作,导致高性能核心必须等待低性能核心,造成资源浪费
Insights
放弃“均匀分配”任务的传统并行策略,转而采用“按能力分配”的动态策略
它确保在并行计算时,每个核心(无论强弱)都能在大致相同的时间完成各自的子任务,从而最大限度地提高 CPU 的整体利用率
动态地为每个核心的特定指令集维护一个性能比率 $pr_i$
也就是说其实维护的是一张表
| 核心 (Core) | 核心类型 | 性能比率 (用于 AVX-VNNI) | 性能比率 (用于 AVX2) |
|---|---|---|---|
| Core 0 | P-core | 3.5 | 2.0 |
| Core 1 | P-core | 3.5 | 2.0 |
| Core 2 | E-core | 1.0 | 1.0 |
| Core 3 | E-core | 1.0 | 1.0 |
分配任务时按照
$$\theta_i = \dfrac{pr_i}{\sum pr_i}$$进行切分
执行任务后根据实际的执行时间动态调整 $pr_i$
$$p{r_{i}}^{\prime}=\frac{pr_{i}}{\sum_{j}t_{i}pr_{j}/t_{j}}$$Approaches
由两大组件构成
- CPU Runtime
- Thread Scheduler
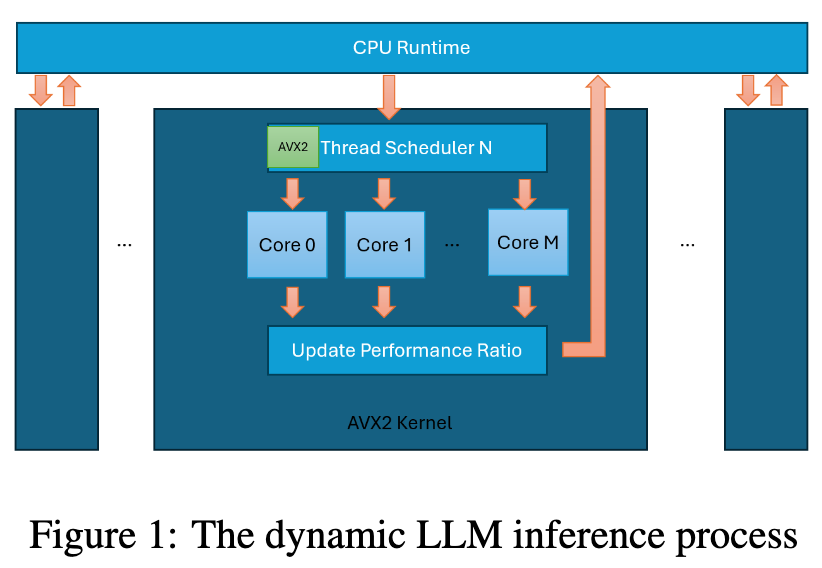
CPU Runtime
管理CPU状态,负责跟踪和更新每个核心的相对性能
- 绑定核心: 它创建的线程池会将每个线程严格绑定到特定的物理核心上
- 性能比率表 : 它为每个核心维护一个“性能比率”($pr_i$),这个比率在初始化时都设为
- 动态更新: 内核(kernel,如一次矩阵乘法)执行完成后,运行时会跟踪每个线程的实际执行时间 ($t_i$)。然后,它使用一个公式(公式2)来更新每个核心的性能比率$pr_i$, 为了避免噪声干扰,还采用了一个滤波器
- 考虑指令集: P-core 和 E-core 在执行不同指令集(ISA,如AVX-VNNI)时性能差异不同,因此会为不同的 ISA 维护不同的性能比率。
Thread Scheduler
负责在推理过程中(如矩阵乘法或张量复制)具体分发并行计算任务
Workflow:
- 查询比率: 当一个内核需要并行计算时,调度器首先向“CPU运行时”查询当前所有核心的性能比率 ($pr_i$)。
- 不均衡分配: 调度器根据这个性能比率表,不均匀地切分任务。性能强的核心($pr_i$高)分配更多的工作,性能弱的核心($pr_i$低)分配更少的工作。分配的子任务量 $s_{i}^{\prime}=\frac{pr_{i}}{\sum pr}s$(其中 $s$ 是总任务量)。
- 执行任务: 调度器激活线程池,让每个核心执行各自被分配的子任务。
- 反馈时间: 所有线程完成后,调度器会从线程池收集每个线程的实际执行时间,并将这些数据反馈给“CPU运行时”,用于更新下一轮计算的性能比率表。