Extensive Reading
Author Info
Background
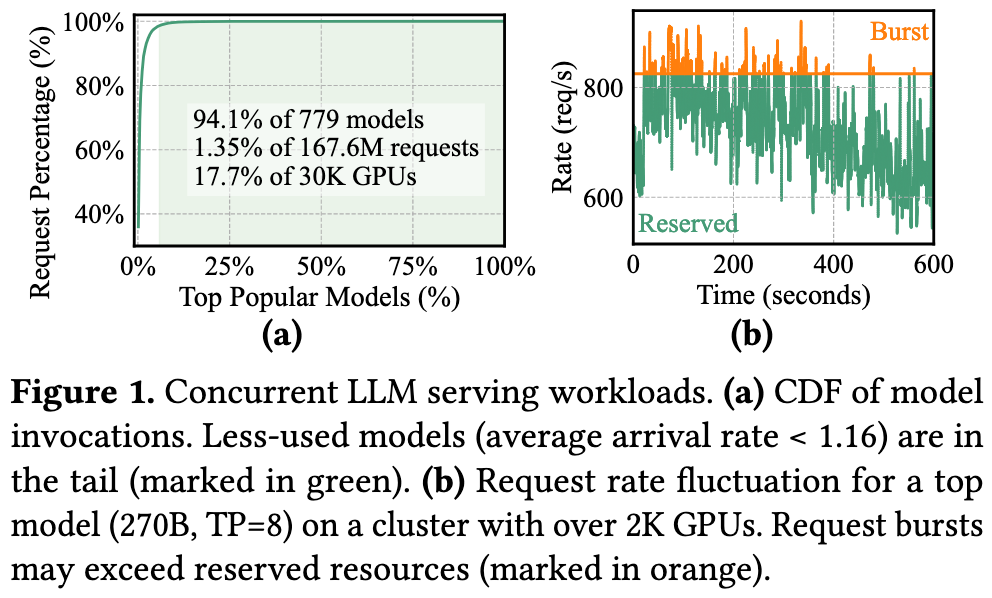
- The workloads are heavily skewed, containing a long tail (more than 90%) of infrequently invoked models.
- Hot models are prone to request bursts that can overload their provisioned sources from time to time.
按需从主机内存(DRAM)或SSD中加载/卸载模型:当一个模型A的请求处理完毕后,再加载模型B来处理其请求,会导致严重的队头阻塞 => Request-level 调度太粗了
通过数学分析(Theorem 3.1)指出,即使单个模型的请求到达率($\lambda$)很低,但只要T很长,系统中的“活跃模型数量” ($\mathbb{E}[m]$) 依然会很高
Due to the typically long service time of LLM requests, the expected active model count
E[m]can be large even when the aggregate arrival rate Mλ is low.总模型数 (M): 100
平均请求到达率 ($\lambda$): 每个模型平均 0.037 请求/秒
平均服务时间 (T): 处理一个 LLM 请求平均需要 16.79 秒
计算出的“平均活跃模型数” $\mathbb{E}[m]$ 高达 46.55, 即需要预留 46.55 个 GPU 实例,每个 GPU 实例相当于负责 2.148 个模型,利用率很低
Challenges
Aegaeon proposes a token-level auto-scaling approach, there are two key challenges:
- How to schedule the auto-scaling?
- 如何智能地决定“下一个”该运行谁,以及“要不要”切换模型,token-level 级的调度非常复杂,需要平衡下面三个因素
- 不同任务的时间: Prefill 和 Decode 的执行时间差异巨大
- 不同的截止时间: 每个请求都有自己的 TTFT 和 TBT 等 SLO 要求
- 高昂的切换代价: 自动伸缩(切换模型)本身有开销
- 如何智能地决定“下一个”该运行谁,以及“要不要”切换模型,token-level 级的调度非常复杂,需要平衡下面三个因素
- How to make auto-scaling fast?
- 作为 token-level 令牌伸缩的前提,如何实现高效的模型切换
Insights
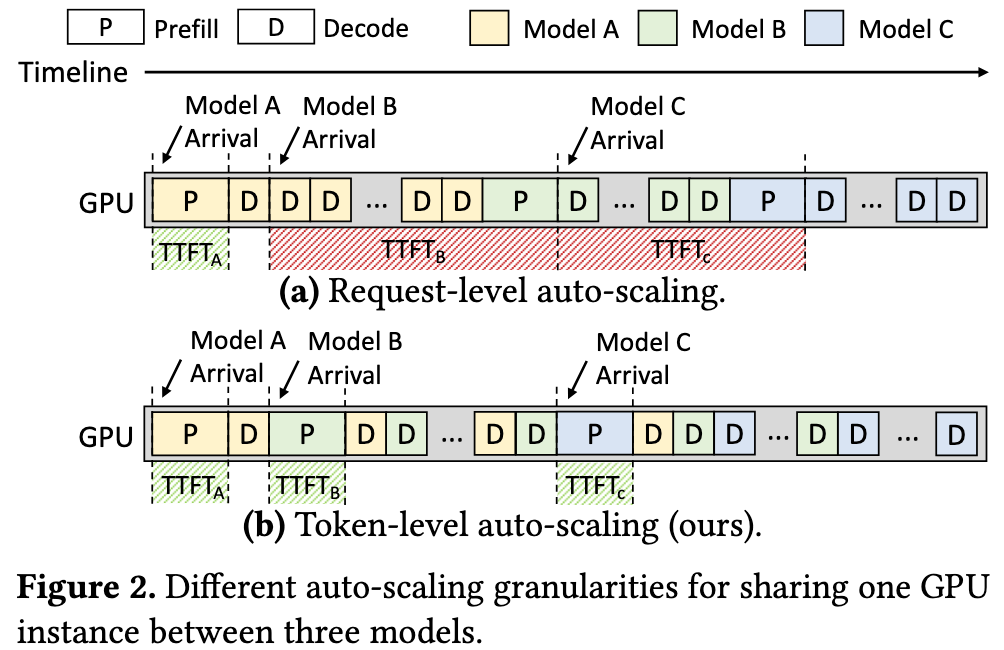
Aegaeon 的核心创新是将自动伸缩的粒度从“请求级”降低到“令牌级”。
核心理念: 系统不再需要等待一个完整的请求(成百上千个token)结束,而是可以在生成一个或几个token之后,就抢占 (preempt) 当前正在运行的模型。
这种在多个模型请求之间高频“交错执行”的能力,使得GPU可以同时服务远超显存限制的模型数量(例如7个模型/GPU),极大地缓解了HOL阻塞,在满足TTFT和TBT等SLO的同时,将GPU利用率提到最高。
Approaches
Token-Level Scheduling
Aegeaon 首先将 Prefill 阶段和 Decoding 阶段的调度分离
- Prefill-first scheduling tends to harm TBT when there are bursts in request arrivals (Figure 6(a))
- Decoding-first scheduling compromises TTFT when request lengths are exceedingly long (Figure 6(b))
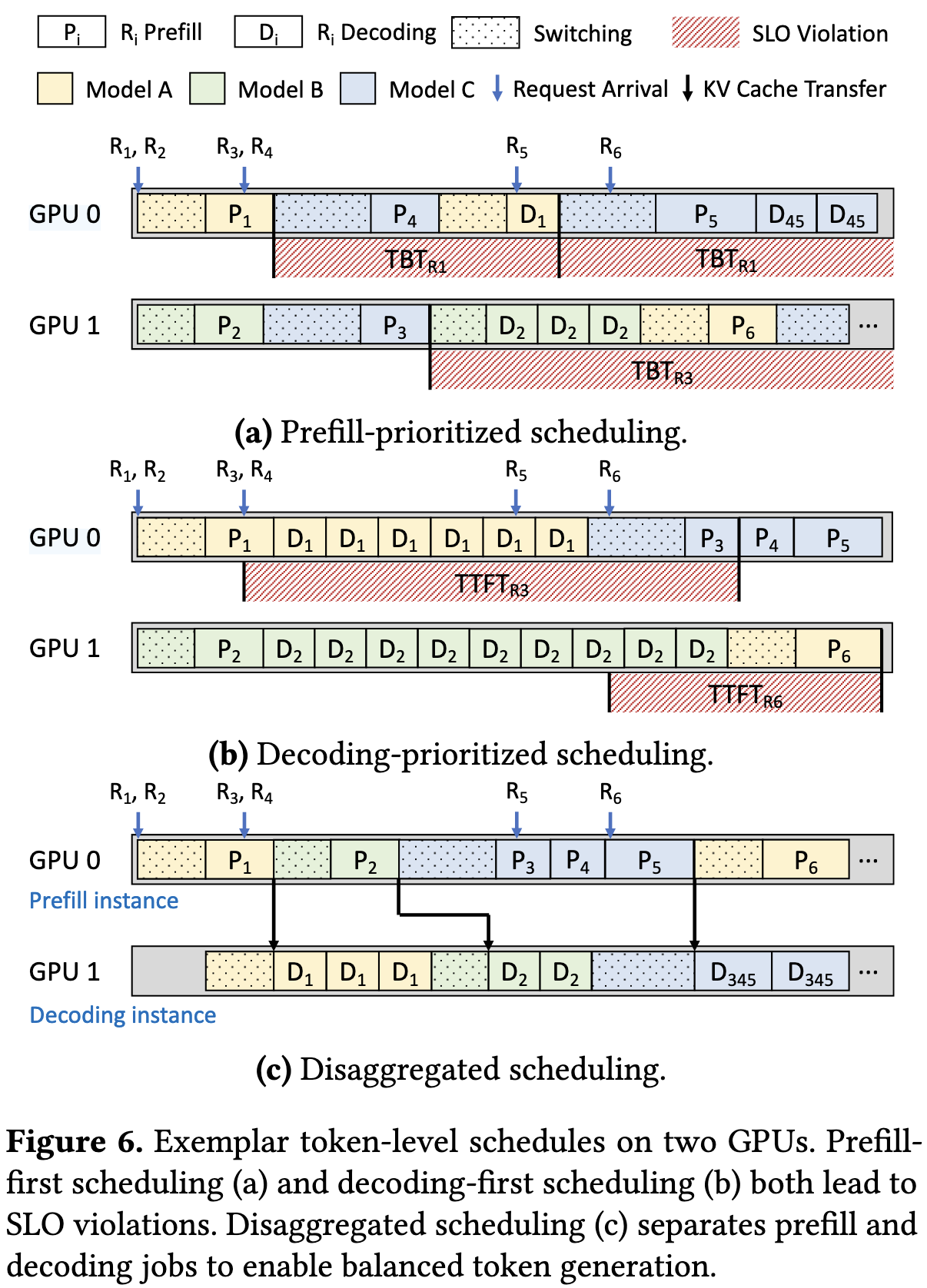
Aegaeon 维护了两个 GPU Pool,一个用于预填充,另一个用于解码。当请求到达时,Aegaeon首先使用来自预填充分区(预填充实例)的实例调度预填充执行,然后使用来自解码分区(解码实例)的实例调度后续解码作业。
- Prefill 调度
这个算法的核心目标:在处理新到达的 Prefill 请求时,尽可能地减少昂贵的“自动伸缩”(即模型加载/切换)次数。
分组 + 负载均衡
一个请求(对应模型 A)到达时:
如果有空闲的 A Group,直接加入
如果没有,在 GPU Pool 中选择一个负载最小的实例创建新的组
Decoding 调度
算法的核心洞察是:LLM 生成一个 token 的实际计算时间(例如 t = 25ms)通常远小于服务等级目标 (SLO) 中规定的“令牌间时间” (TBT)(例如 d = 100ms)
加权轮询调度器
在一个新的调度“轮”(Round) 开始时,算法会执行以下两个关键的准备步骤:
- 分配时间配额, 保证不违反 TBT
- 重排序工作列表
为了减少模型切换开销,它会执行重排序 (Reorder)
假设工作列表是:[Batch1(A), Batch2(B), Batch3(A), Batch4(C), Batch5(B)]
调度器会重排序为:[Batch1(A), Batch3(A), Batch2(B), Batch5(B), Batch4(C)]
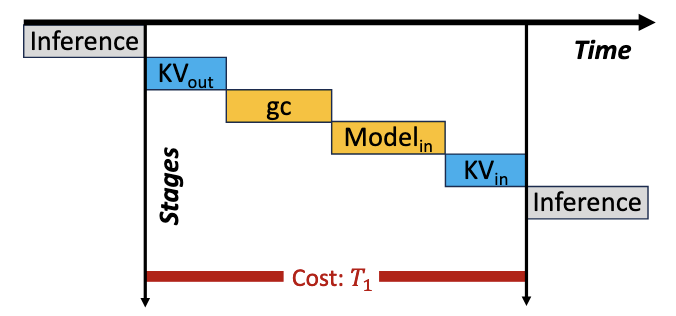
Efficient Preemptive Auto-Scaling
核心目标:实现高效地模型切换
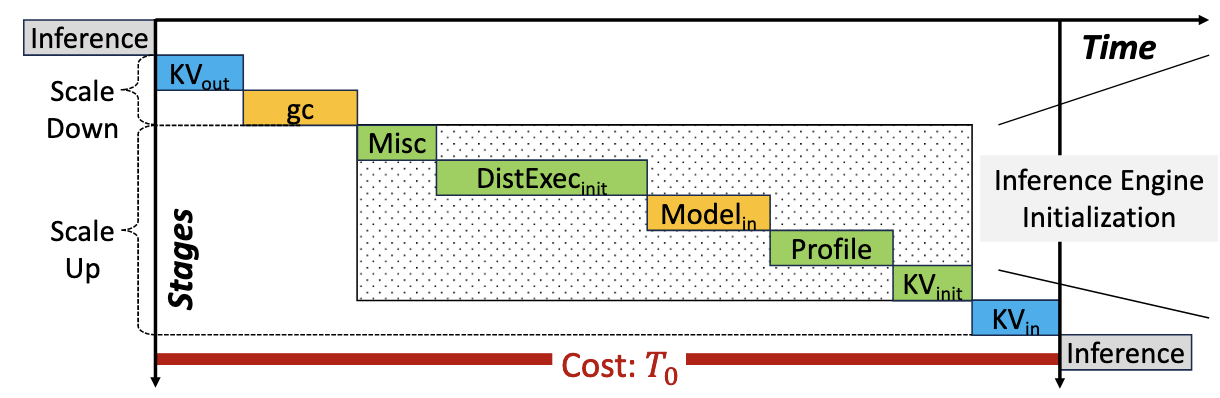
分为两步
- Scale Down
- 移除 KV, 进行 gc
- Scale Up
- 推理引擎初始化
- 分配 KV 空间
- 加载 KV
三个技术:
- (Re)initialization Breakdown and Component Reuse
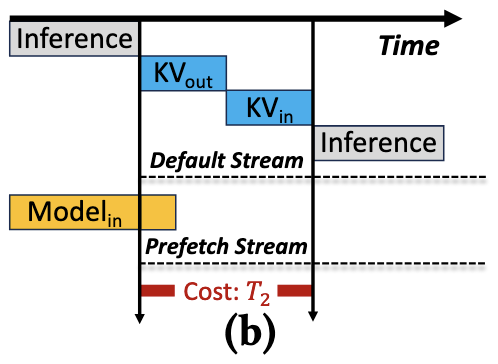
分析发现,引擎初始化的开销占大头(如Ray、NCCL等分布式组件的初始化)。
Aegaeon 使这些组件在实例启动时只初始化一次并常驻。模型切换时,只交换模型权重 (Model Weights) 和 KV Cache,从而节省了超过80%的切换延迟。
改进后:
- Explicit Memory Management
分为三类:
- VRAM 管理
- 模型加载与预取
- DRAM 管理
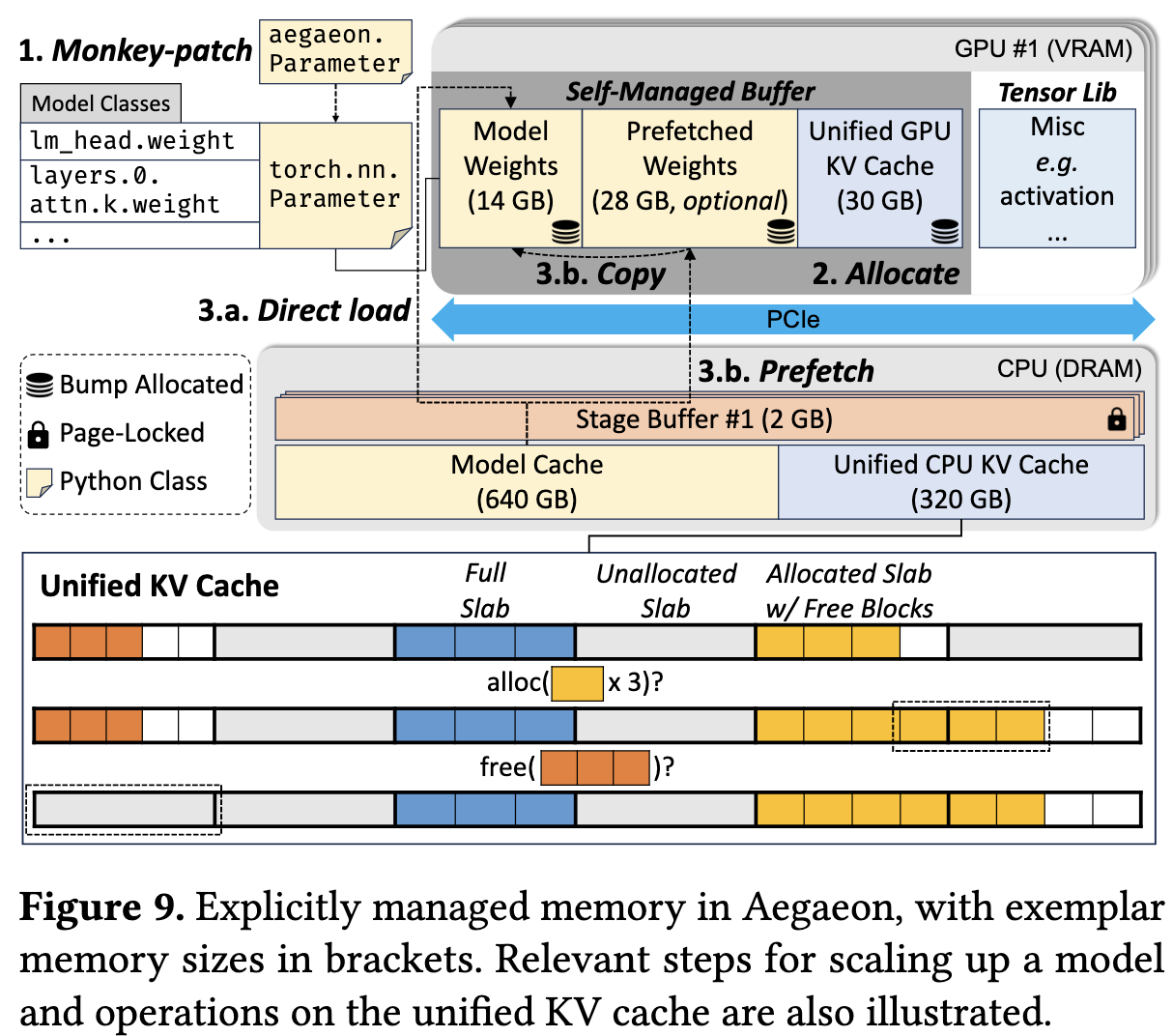
VRAM 管理
为避免PyTorch等框架的内存分配器导致的内存碎片和垃圾回收(GC会造成数秒卡顿),Aegaeon 实现了一个 Self-managed VRAM buffer。
它在启动时一次性分配一大块 VRAM,并使用高效的碰撞指针 (Bump Allocator) 进行管理。
通过 Monkey-patching 技术(在Python层面修改 torch.nn.Parameter 等类),让模型权重和 KV Cache 绕过 PyTorch,直接使用这个自管理缓冲区,从根本上消除了 GC 开销
模型加载与预取
- Aegaeon 在主机DRAM中维护一个 Model Cache
- 调度器会预测下一个要运行的模型,并在后台 CUDA流 (Prefetch Stream) 中将其权重 预取 (Prefetch) 到VRAM的空闲区域。
- 当真正需要切换时,权重已经存在于VRAM中,只需一次极快的设备内拷贝 即可完成加载,实现切换。
DRAM 管理
当大量不同模型的KV Cache被换出到DRAM时,会因形状各异(取决于层数、头数等)导致内存碎片。Aegaeon 使用经典的 Slab 分配器 来构建 统一CPU KV Cache (Unified CPU KV Cache),高效管理DRAM。
Slab Allocation (Slab 分配) 是一种高效的内存管理技术,它专门用于解决“频繁分配和释放相同大小的对象”时所导致的内存碎片问题。
它的核心思想是“整存零取,循环利用”:
- Slabs (大内存块): 系统首先从操作系统那里申请几个大的、连续的内存块(称为 Slabs)。
- Blocks (小对象块): 然后,Slab 分配器将一整个 Slab 切割成许多固定大小的小块(称为 Blocks)。这个“固定大小”就对应你要存储的对象的大小(例如 512 KB)。
- 分配: 当程序需要一个 512 KB 的对象时,分配器会从专门存放 512 KB 块的 Slab 中取出一个 free block 并交给程序 。
- 释放: 当程序用完这个对象后,它不会真的被“释放”掉,而是被简单地标记为“空闲”,并“还回”到它原来的 Slab 池中,等待下一次被重用 。
最终改进后
- Fine-Grained KV Cache Synchronization
KV Cache的换入(DRAM->VRAM)和换出(VRAM->DRAM)必须在独立的CUDA流上异步执行,以实现与计算的重叠 (overlap)。
但这会引入复杂的数据依赖问题(例如,换入流不能在换出流完成前读取数据)。
Aegaeon 使用轻量级的 CUDA Events (如 cudaEventRecord, cudaStreamWaitEvent) 来在不同流、不同进程间进行细粒度同步。这确保了数据一致性,同时避免了粗暴的全局锁,最大化了异步执行的效率。