Extensive Reading
Author Info
Background
- Existing LLM serving systems typically colocate the prefill and decoding phases on the same set of GPUs, often using scheduling techniques like continuous batching to mix the computation of both phases.
- This colocation strategy creates severe prefill-decoding interference, where the long, compute-intensive prefill tasks block the short, memory-intensive decoding tasks, significantly degrading both the Time-To-First-Token (TTFT) and the Time-Per-Output-Token (TPOT).
- Colocation also couples the resource allocation and parallelism strategies for both phases, forcing them to share the same configuration even though their computational characteristics and latency requirements are fundamentally different, which leads to resource over-provisioning and inefficient performance.
Insights
Disaggregate the prefill and decoding phases of LLM inference, assigning them to separate GPUs, which brings two benefits:
- eliminates prefill-decoding interference
- allows to scale each phase independently with tailored resource allocation and model parallelism strategies
和 Splitwise 不同的是,DistServe 还提出了 prefill 和 decoding 阶段对 model-parallelism 要求的不同:
- the prefill phase tends to be compute-bound and benefits from more TP
- the optimal parallelism configuration of the decoding phase depends on the running batch size
Analysis
Prefill
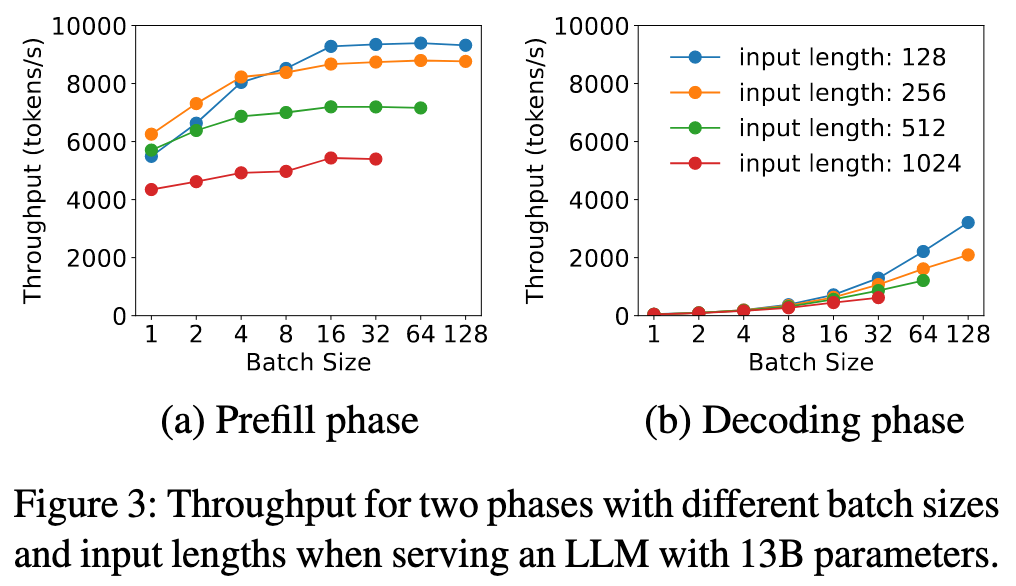
Once the GPU becomes compute-bound, adding more requests to the batch no longer improves GPU efficiency.
所以得对 LLM + GPU 的组合做 profile, 得到一个 input length threshold $L_m$,在进行 batch 时,总的 token 长度不应该超过 $L_m$
- Batching: Prefill阶段的计算量随输入长度增长很快。对于中等长度(如512 Token)的输入,单个请求就足以占满A100。因此,Prefill实例的Batch Size通常很小
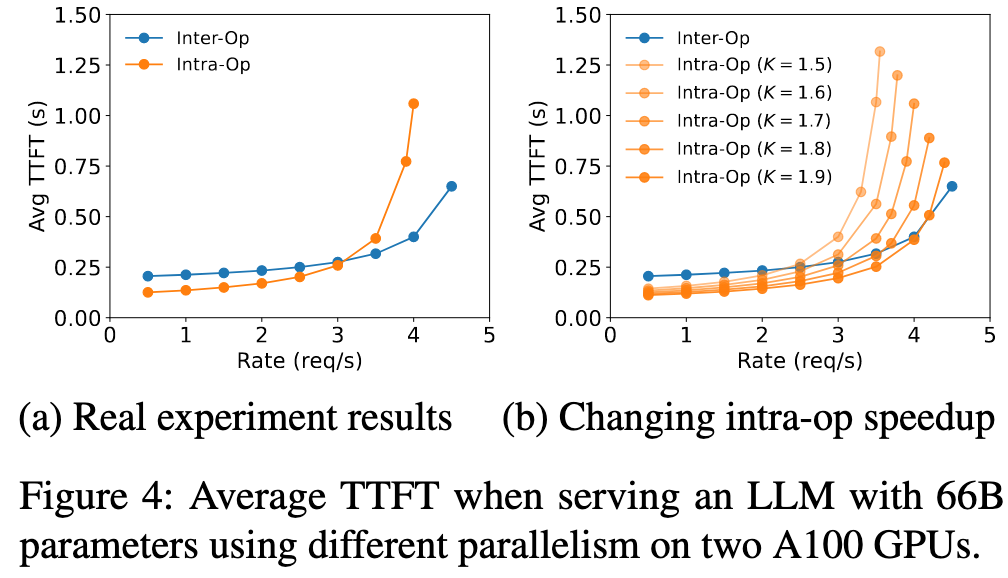
- Parallelism: TP is more efficient at lower arrival rates, while inter-op PP gains superiority as the rate increases.
Decoding
- Batching: Decoding是访存密集型,必须使用大批量(Large Batch) 才能充分利用GPU(Figure 3b)。解耦使得这成为可能(例如,多个Prefill实例可以“喂”一个Decoding实例)。
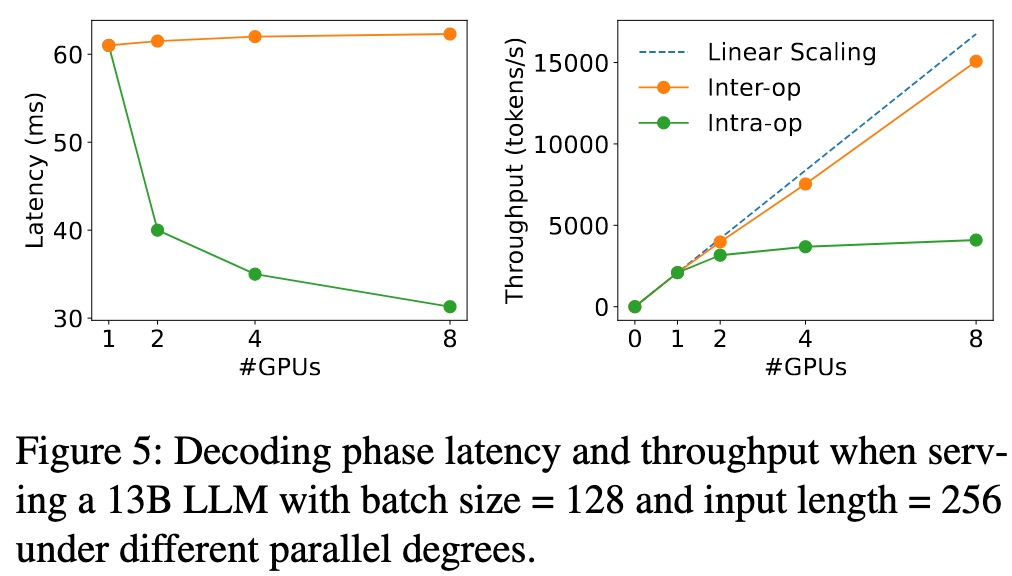
- Parallelism: 偏好使用 PP,因为吞吐量能够呈线性扩展;当TPOT的SLO很严格时,优先用张量并行(TP) 降低延迟;一旦满足SLO,优先用流水线并行(PP) 来线性提升吞吐率。
As the decoding batch size continue to increase to approach the compute-bound, the decoding computation begins to resemble the prefill phase.
Approaches
DistServe 给出了两种 Placement 算法
- Placement for High Node-Affinity Cluster
由于不需要考虑 prefill 实例和 decoding 实例之间的 KV Cache 的传输,算法可以独立地为 Prefill 和 Decoding 两个阶段分别寻找最优配置
它通过枚举所有可行的并行策略 ,并利用模拟器 (Simulator) 结合二分搜索 (binary search) 来快速估算每种配置在满足延迟要求(SLO)下的最大有效吞吐量(goodput)
- Placement for Low Node-Affinity Cluster
该算法的 insight:KV Cache 只在 Prefill 和 Decoding 的“对应层”之间传输
所以强制要求在使用 PP 时,Prefill 的 stage 1 和 Decoding 的 stage 1 必须在同一个物理节点上(可以使用 NVLink)
Example
假如有两个节点:A,B,使用 2 阶 PP,需要分为 Prefill 实例和 decoding 实例
Prefill 实例 = Prefill 片段1 + Prefill 片段2 Decoding 实例 = Decoding 片段1 + Decoding 片段2
会有下面两种部署方式:
节点 A: 部署完整的 Prefill 实例(包含片段1 和 片段2)
节点 B: 部署完整的 Decoding 实例(包含片段1 和 片段2)
节点 A: 部署 Prefill 片段1 和 Decoding 片段1
节点 B: 部署 Prefill 片段2 和 Decoding 片段2
在第二种部署方式下,KV Cache 能够通过 NVLink 在同一个节点内部快速传输
在线调度方面
- 为了减少流水线气泡,通过预先分析找出 $L_m$,prefill 和 decoding 实例都不能超过这个限制
- Prefill 实例完成计算后,只是将 KV Cache 保留在自己的 GPU 显存中 。Decoding 实例在自己有空闲容量时,才主动从 Prefill 实例那里“拉取” KV Cache 数据进行处理