Extensive Reading
Author Info
Background
- The standard method for large language model (LLM) inference, autoregressive decoding, is slow and costly because it generates tokens sequentially, one at a time.
- Existing acceleration methods like speculative sampling often struggle to find a suitable draft model; using a smaller version of the LLM can have high overhead, while training a new, appropriately-sized draft model is prohibitively expensive.
- Other approaches like Lookahead and Medusa successfully reduce drafting latency but are ultimately limited by the low accuracy of their drafts, which restricts their maximum achievable speedup.
Insights
Two key insights:
- autoregression at the feature level is simpler than at the token level
- the uncertainty inherent in the sampling process significantly constrains the performance of predicting the next feature
Approaches
Preliminaries
Vanilla autoregression at the token level is described by
$$T_{1:j} → E_{1:j} → f_j → p_{j+1} → t_{j+1}$$for any integer $j ≥ 1$.
- $T$: Tokens
- $E$: Embeddings
- $f$: Features (the output of last transformer layer, or “the second-to-top-layer feature of a LLM, the hidden state before the LM head” in the paper)
- $p$: distributions
解释一下整个过程:
- LLM 输入为一个文字序列,经过 Tokenizer 后成为 $T_{1:j}$
- $T_{1:j}$ 经过 Embedding 后变为 $F_{1:j}^0$
- 然后经过 Transformer Layers 不断丰富,得到最后包含了对所有内容语义,语法和上下文理解的 $F_{1:j}$
- 取最后一个 token 的特征表示 $f_j$
- 通过 LM Head(embedding + softmax) 得到下一个 token 的概率分布 $p_{j+1}$ (用 $f_j$ 预测 $p_{j+1}$)
- 从 $p_{j+1}$ 采样得到 $t_{j+1}$
Embedding 在两个阶段的数学操作不同:
1. 输入阶段:查表(lookup)
当我们输入一个 token (t_i) 时,它是词表中的一个索引,比如 42。 模型的嵌入矩阵是:
$$W_E \in \mathbb{R}^{V \times d}$$其中:
- (V):词表大小
- (d):embedding(隐藏)维度
查表其实就是选取 (W_E) 的某一行:
$$e_i = W_E[t_i]$$这本质上等价于:
$$e_i = \text{one\_hot}(t_i) \cdot W_E$$也就是说,把 token 变成一个 one-hot 向量,然后乘以整个嵌入矩阵 —— 只是实现上我们用查表来加速而已。
2. 输出阶段:矩阵乘法(feature → logits)
Transformer 最后一层输出一个向量 ($f_j \in \mathbb{R}^d$), 为了得到每个词的概率(logits),我们要计算:
$$\text{logits}_{j+1} = f_j W_E^\top$$把特征和所有 embedding 进行相似度计算(点积)
这一步得到一个 (V)-维向量,对应每个词的得分。再经过 softmax:
$$p(t_{j+1}) = \text{softmax}(\text{logits}_{j+1})$$| 阶段 | 操作 | 数学等价式 | 实现形式 |
|---|---|---|---|
| 输入 | one-hot → embedding | $e_i = \text{one\_hot}(t_i) \cdot W_E$ | 查表 |
| 输出 | embedding → logits | $\text{logits} = f_j W_E^\top$ | 矩阵乘法 |
Feature-level prediction
- 利用模型次顶层特征进行自回归预测比直接预测下一个 Token 更简单、更具规律性
- 直接预测 Token ❌
- 直接预测 Feature ✅
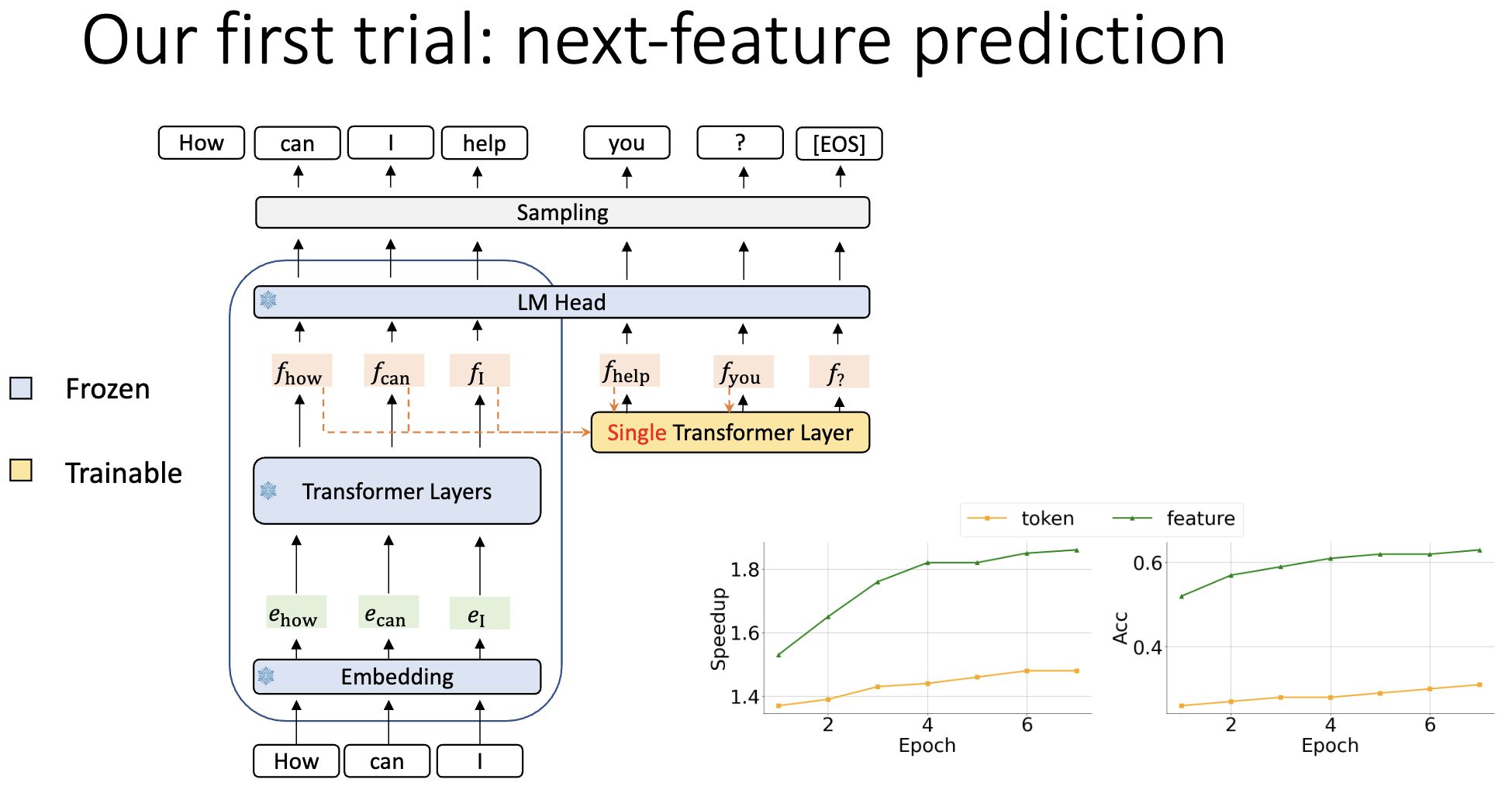
非常 Reasonable:
- $f_j$ 包括了大量的“知识”(语义语法上下文),而采样后的 $p_j+1$ 丢失了这种信息
Feature uncertainty
如果只用 $f_j$ 来进行预测,会出现一个问题:
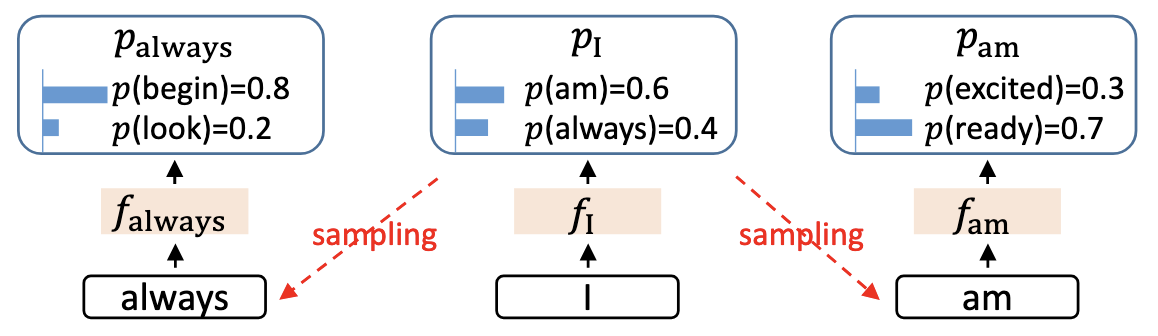
比如上图中,$f_{i}^{(I)}$ 其实包含了两种采样结果:$p_{(am)}$ 和 $p_{(always)}$,在采样时选择不同的 token 会通向不同的特征 $f_{i+1}^{(\text{am})}$ or $f_{i+1}^{(\text{always})}$
在通过 $f_{i+1}$ 预测 $f_{i+2}$ 时,我们只希望 $f_{i+1}$ 中包含一个确定的 $t_{i+2}$
Idea: feature & shifted-token -> next feature
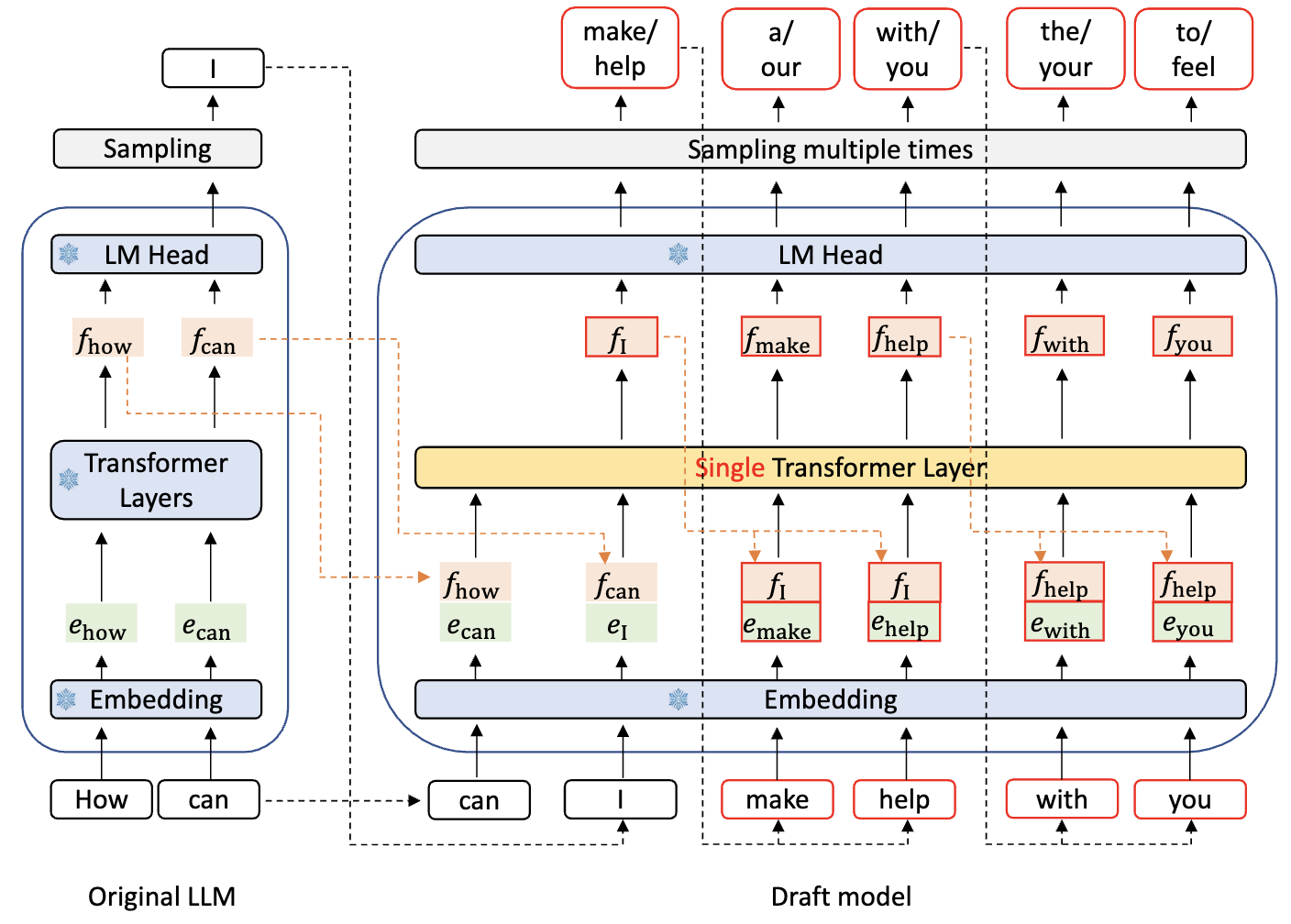
伪代码:
# 已知:上一时刻真特征 f_i(来自目标模型某层的隐藏态)
# 步骤:
# 1) 先用 f_i 的 LM Head 采样出 t_{i+1}
logits_i = lm_head(f_i) # 复用目标模型 LM Head
t_next = sample_from_logits(logits_i) # 采样(或取 top-k/温度采样)
# 2) 把 tokens_right_shifted 更新到包含 t_{i+1},喂 AR-Head 预测 \hat f_{i+1}
# feats_hist 包含到 i 的特征序列;tokens_shifted 包含 t2..t_{i+1}
f_next_hat = ar_head(feats_hist, tokens_shifted, return_all=False) # [B, H]
# 3) 再用 \hat f_{i+1} 走 LM Head 得到下一步分布,继续采样 t_{i+2}
logits_next = lm_head(f_next_hat)
t_next2 = sample_from_logits(logits_next)
# (可扩展为树:对 t_{i+1} 取多分支并行各自预测 \hat f_{i+1}^{(branch)})
Overall Comparison
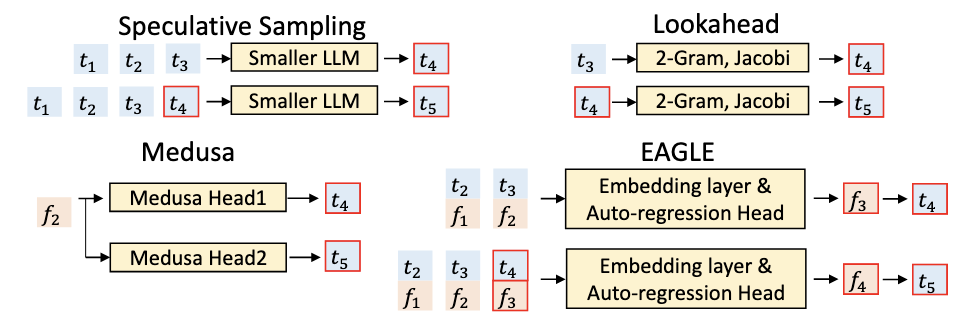
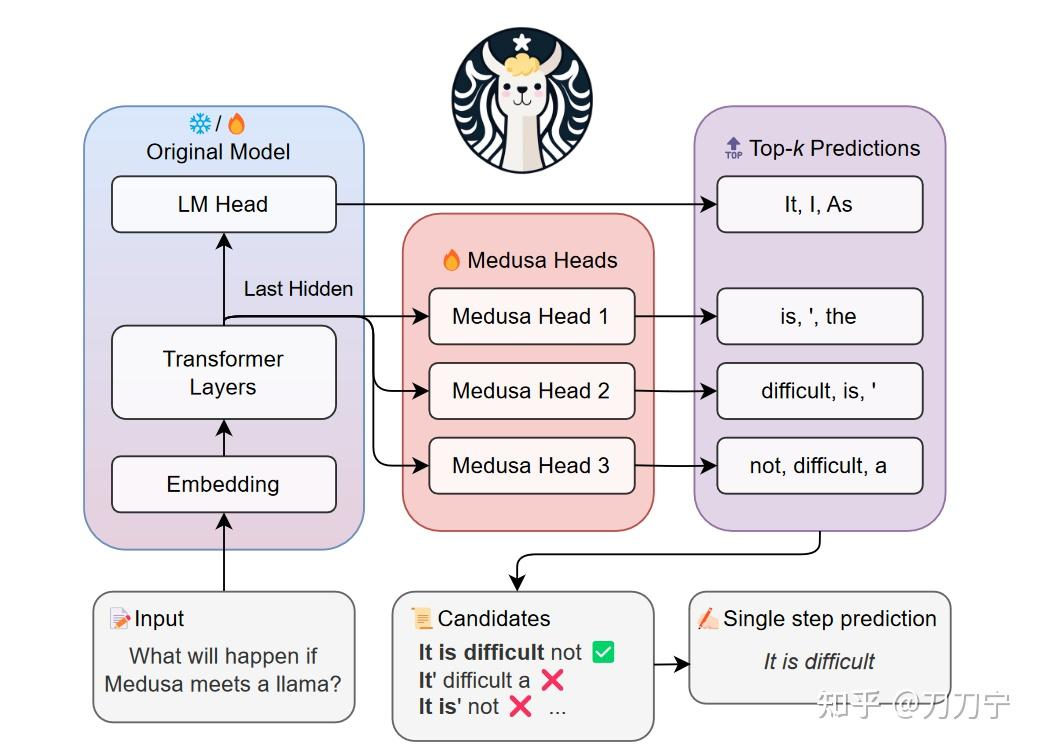
By the way, Medusa overview: