Extensive Reading
Author Info
Background
When applying LLMs for infinite input streams, two main challenges arise:
- KV Cache will grow infinitely which leads to excessive memory usage and decode latency
- LLM’s performance will degrade when the sequence length goes beyond the attention window size set during pre-training
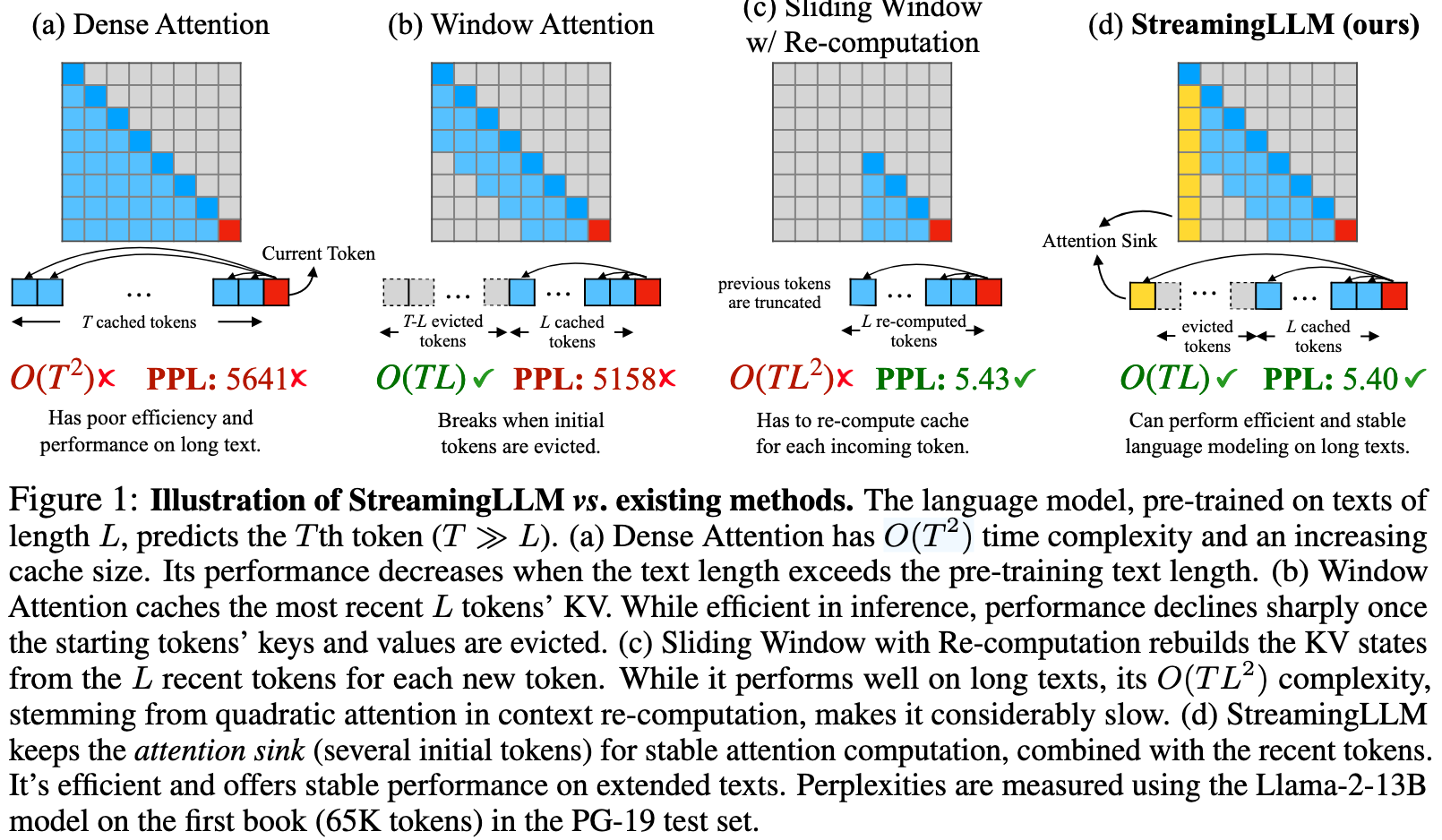
- Window Attention: Only keep $L$ recent tokens in KV cache
- Model degrades dramatically once the sequence length exceeds the cache size (even just evict the first token)
- Slide Window with Re-computation: Do not reuse KV. At every step, rebuild the whole window last $L$ tokens and run the Transformer on that small segment from scratch
Slide Window Example
- t = 1:
- Window:
[x₁] - Run the model on this length-1 sequence, use the output of x₁.
- Window:
- t = 2:
- Window:
[x₁, x₂] - Run the model on
[x₁, x₂](full self-attention 2×2), use the output of x₂.
- Window:
- t = 3:
- Window:
[x₁, x₂, x₃] - Run the model on these 3 tokens (3×3 attention), use x₃.
- Window:
- t = 4:
- Window slides:
[x₂, x₃, x₄] - Run the model again on this 3-token segment (3×3 attention), use x₄.
- Window slides:
- t = 5: window
[x₃, x₄, x₅], full 3×3 attention, use x₅. - t = 6: window
[x₄, x₅, x₆], full 3×3 attention, use x₆.
Observations
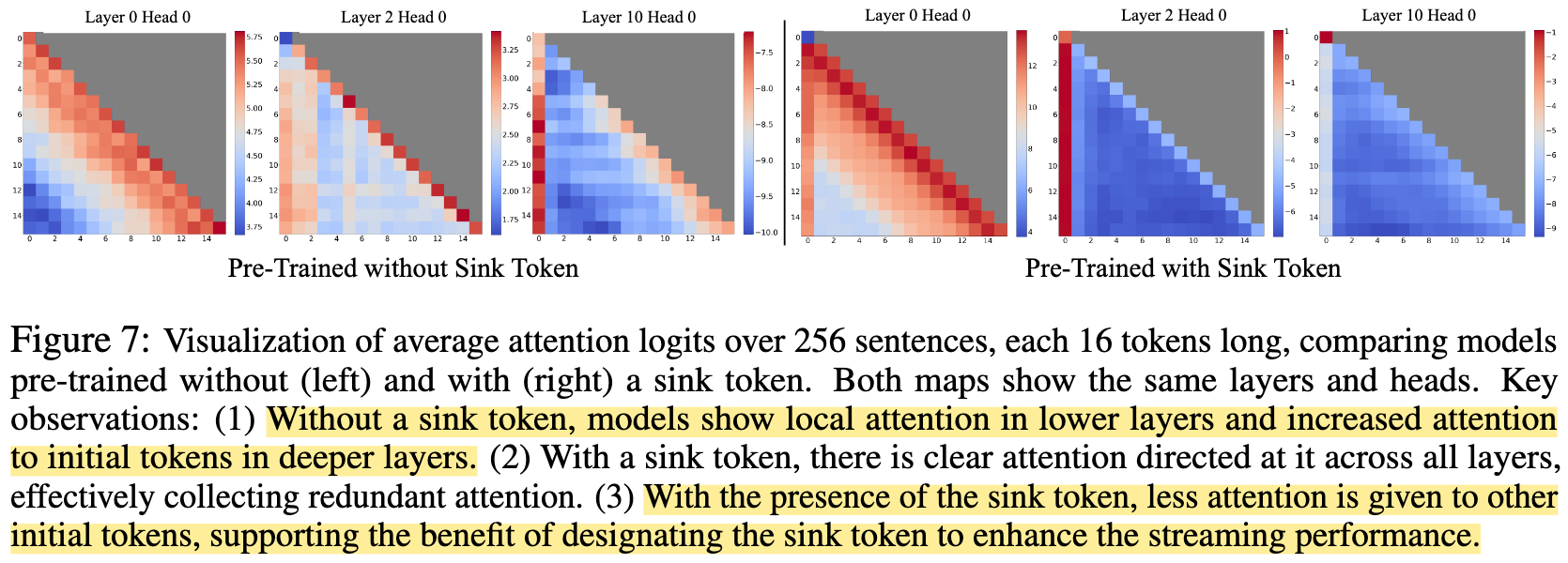
A surprisingly large amount of attention score is allocated to the initial tokens, irrespective of their relevance to the language modeling task.
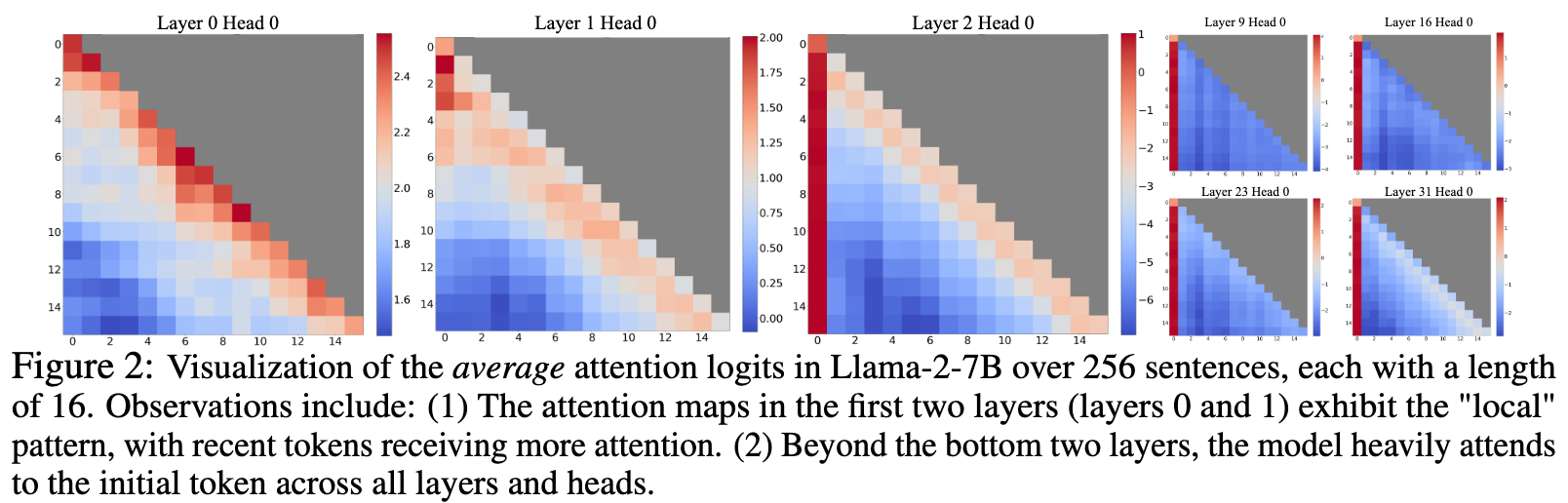
These high-score tokens are termed attention sinks
This paper contribute this phenomin to the softmax operation in the self-attention
- Althrought some tokens do not have a strong match in many previous tokens, attention score must sum up to one
- The first token is visible to the all subsequent tokens
Insights
Preserving the attention sink tokens can maintain the attention score distribution close to normal.
Approaches
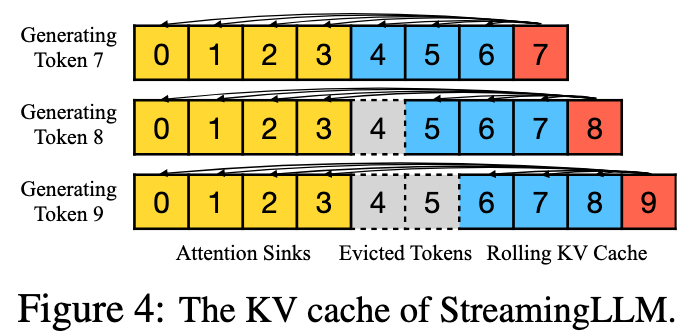
Organize KV Cache:
- X initial tokens as attention sink
- Y rolling tokens close to the last token
- When adding positional information to tokens, StreamingLLM uses the position within the cache
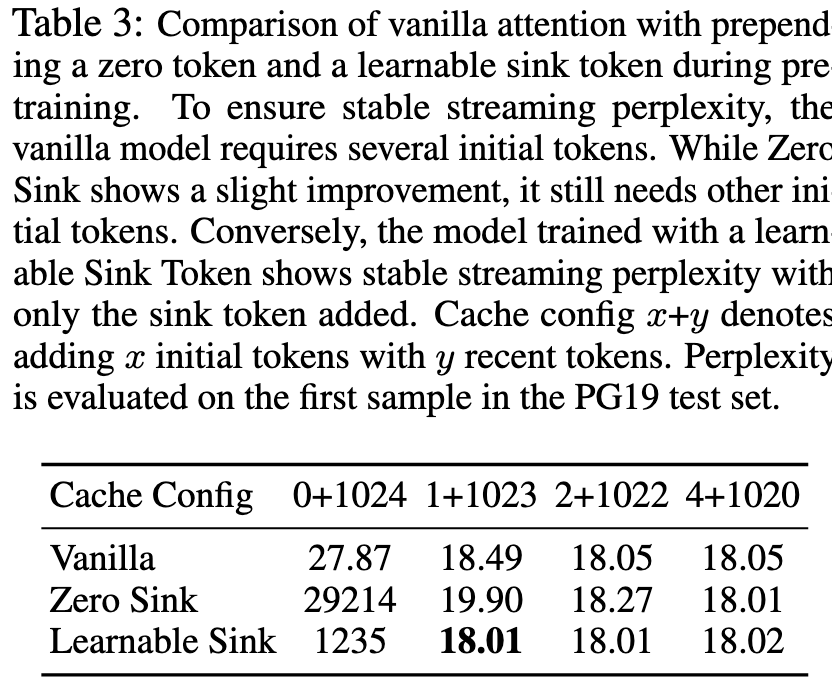
The paper also pre-trains a model with sink tokens, which demostrate their theories
Evaluation
Thoughts
StreamingLLM 主要解决的是“长历史导致数值行为崩坏(PPL 爆炸)”,不是“让模型记住无限多内容”。真正可用的上下文仍由 KV cache 决定,超出窗口的信息,对后续 Query 来说就等同于丢失。
StreamingLLM solves the problem which the sequence length is longer than the attention window size set during the pre-train phase causes perplexity dramatically increase, but the context size is still fixed – the model cannot remember infinite contents, it still depends on the KV cache size
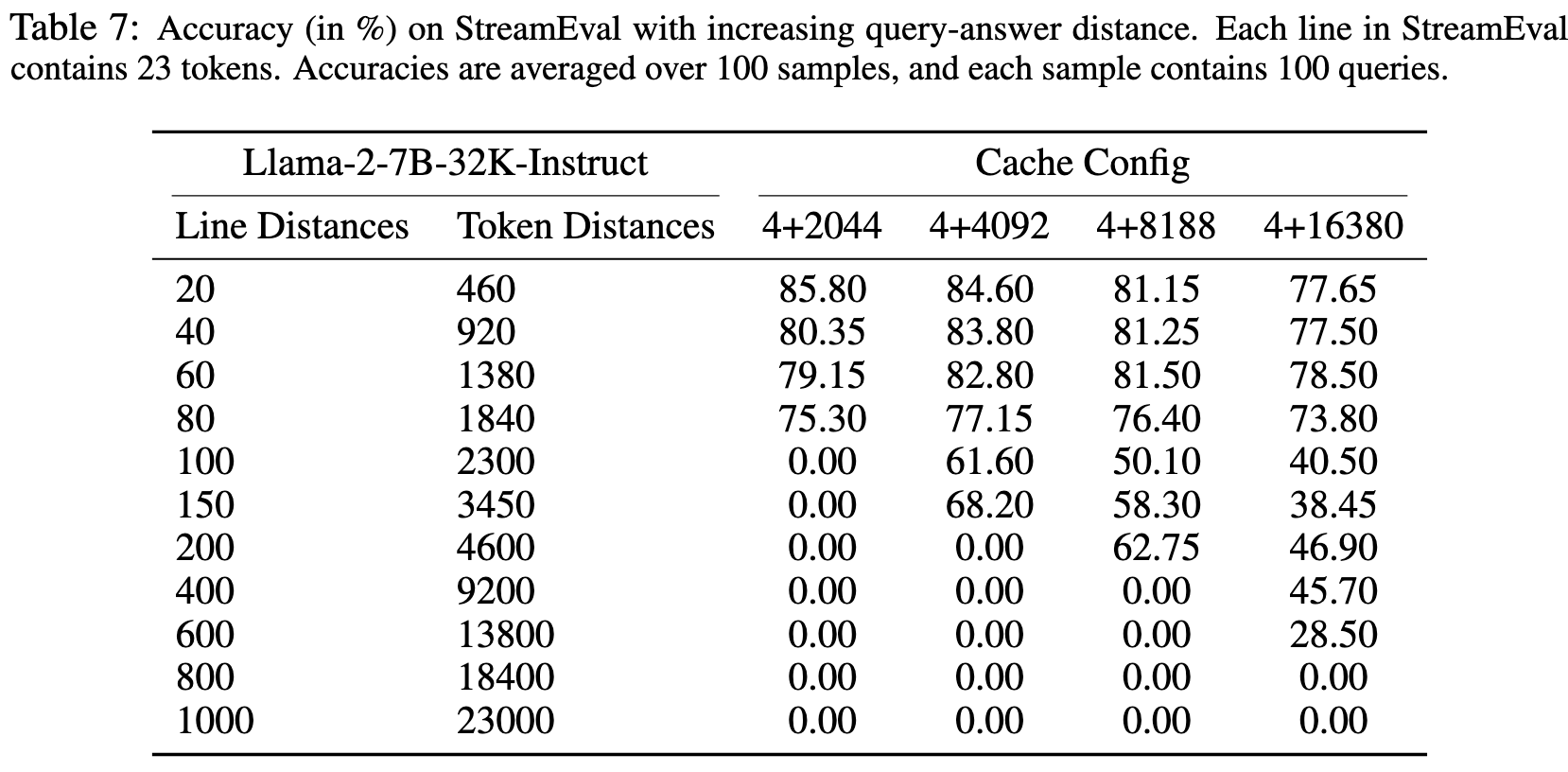
Consider a scenario:
- Input sequence length is 1000
- Attention window is 500
- StreamingLLM chooses a KV cache of
4+496 - Query-answer, but the answer lives in about 100-200th tokens
- The information is not included in the KV cache, so the model cannot give a correct answer
Appendix C gives a detailed evaluation:
So the authors says in the related work:
“Extending the context size of LLMs doesn’t improve the model’s performance beyond the context size, and neither approach ensures effective use of the long context.”
Q: If streamingLLM cannot read contents beyond its token ranges, why not just truncating the input sequence to the context size?
A: Bingo! Congratulations, you just employ the “sliding windows with recomputation” strategy in Figure 1 – Under the scenario of streaming, e.g. conversations, you have to recompute the whole sequence whose time complexity is $O(TL^2)$ after $T$ rounds, which is unacceptable due to the poor performance