Intensive Reading
Author Info
- Wangsong Yin - Google Scholar
- Rongjie Yi - Google Scholar
- Daliang Xu (徐大亮) - Daliang Xu’s Website: An Assistant Professor (Associate Researcher) at BUPT.
- Mengwei Xu
- Xuanzhe Liu
Background
- Existing LLMs lack the flexibility to accommodate the diverse Service-Level Objectives (SLOs) regarding inference latency across different applications.
Prerequisite
In-context learning is a paradigm that allows language models to learn tasks given only a few examples in the form of demonstration.
Challenges
Designing an LLMaaS with efficient elasticity faces the following unique challenges:
- Costly runtime switching between elasticized models.
- Sensitive prompt-model orchestration strategy.
The LLM requests from different apps or tasks have diversified SLO demands on inference latency.
Insights
- TTFT is influenced by both prompt length and model size
- TPOT is mainly determined by model size
Main insights
- Transformer 模块具有置换一致性,可以根据不同块的重要性得分对其进行重排而不影响最终结果,因此将高开销的动态剪枝操作转变为几乎零成本的在线内存指针移动。
- 模型和提示词是两个独立的弹性维度,为满足特定延迟目标,必须对二者进行与内容相关的智能协同,以最大化输出质量。
Approaches
Model elastification
主要就是模型层内的重排:一个注意力块内的所有注意力头会根据其重要性得分进行相互重排,但不会和另一个注意力块或者MLP块的单元混合排序。
剪枝比例的分配是“层间均匀”的:当系统需要一个特定尺寸的子模型时(例如,全局参数量为80%),这个比例会均匀地分配到所有需要进行弹性化的Transformer层。
ELMS 发现有少数几层的重要性远高于其他层,称之为 anchor layers, 对这些 anchor layers 采用锁定策略,不进行任何剪枝或重排。
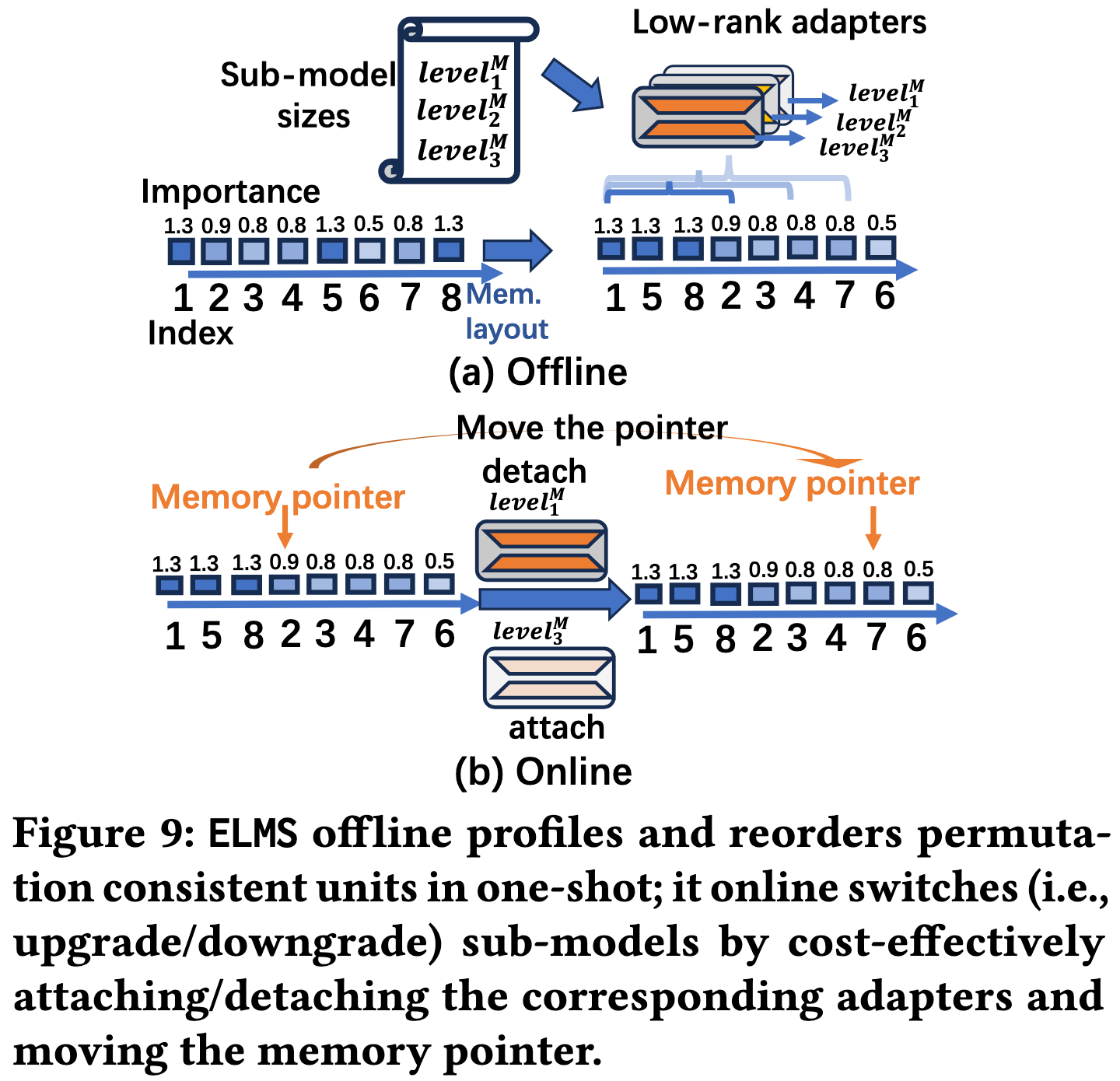
重排的准则就是依据模型的重要性评分,重要的排前面。
重排后的整个模型也需要加载到内存中,只是每次请求(模型切换时)改变计算时使用的权重张量末尾的内存指针。
使用子模型时相当于剪枝,所以 ELMS 对于每个预设的子模型都额外训练了一个 LoRA 作为 pruning recovery
Prompt elastification
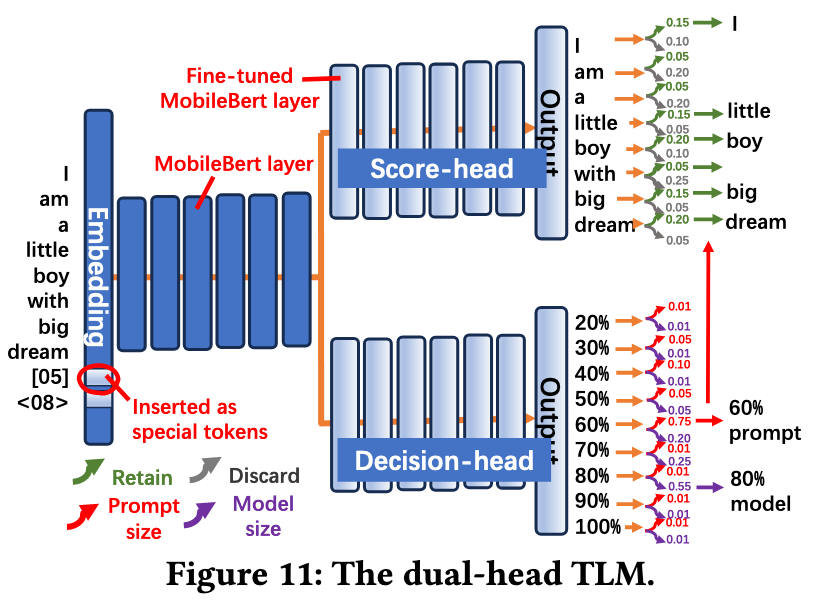
ELMS 设计并训练了一个 TLM,给定一个输入和 SLO 指标,TLM
- 确定每个 token 的重要程度
- The score-head treats each token of the prompt as a two-class classification problem, where each token can be classified into “discard” or “retain”.
- 确定 prompt 和 model 的剪枝百分比
- The decision-head treats the entire sequence of prompt with SLO as two multi-class classification problems.
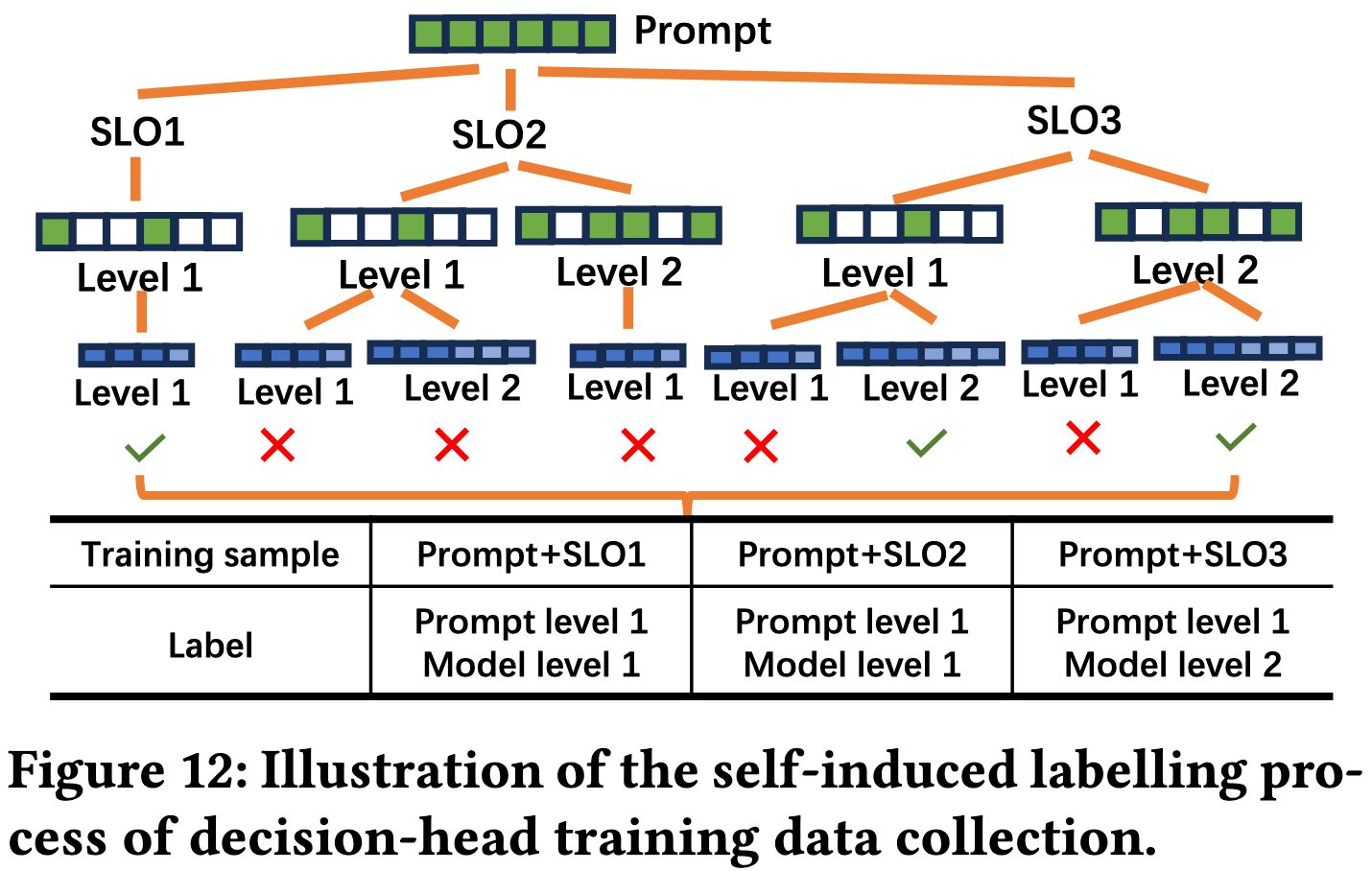
TLM 训练时采用了自诱导的方式:
- 给定一个 prompt 输入和不同的 SLO 要求
- 遍历所有策略并运行
- 分析所有策略的运行结果,记录最优策略为标签
TLM 相当于是上下文稀疏性相关工作中的 online predictor
Evaluation
虽然智能手机的SoC中普遍配备了GPU和NPU等硬件加速器,但截至2024年8月,这些加速器及其软件开发工具包(SDK)存在一些遗留问题 。这些问题包括对动态形状(dynamic shape)、图构建(graph building)等的支持不完善,导致无论是ELMS还是其对比的基线方法,都无法在这些加速器上无缝运行
Thoughts
When Reading
- 实用性?
- 离线一次性重排序需要训练轻量级的 LoRA
- Dual-head TLM 也需要训练
置换一致性从数学角度来说就是矩阵乘法的外积展开视角
整个思路和 Deja Vu Contextual Sparsity for Efficient LLMs at Inference Time 中提出的上下文稀疏性有点类似
分析一下,其实也是 offline profile online predict 那一套
与 Speculative Decoding 比较相关:两者都用小模型辅助大模型。推测解码加速Token生成速度(TPOT),而ELMS调整模型以满足延迟目标(TTFT/TPOT)。它们可以结合:ELMS选择一个子模型(如50%模型)来作为另一个更大子模型(如90%模型)的草稿模型。
Self speculative decoding? 好像已经有这方面的研究了,没看过这方面的论文