Skimming
Author Info
- Zhenyu “Allen” Zhang: A final-year Ph.D. student at the Electrical and Computer Engineering Department of UT Austin.
- Ying Sheng
Insights
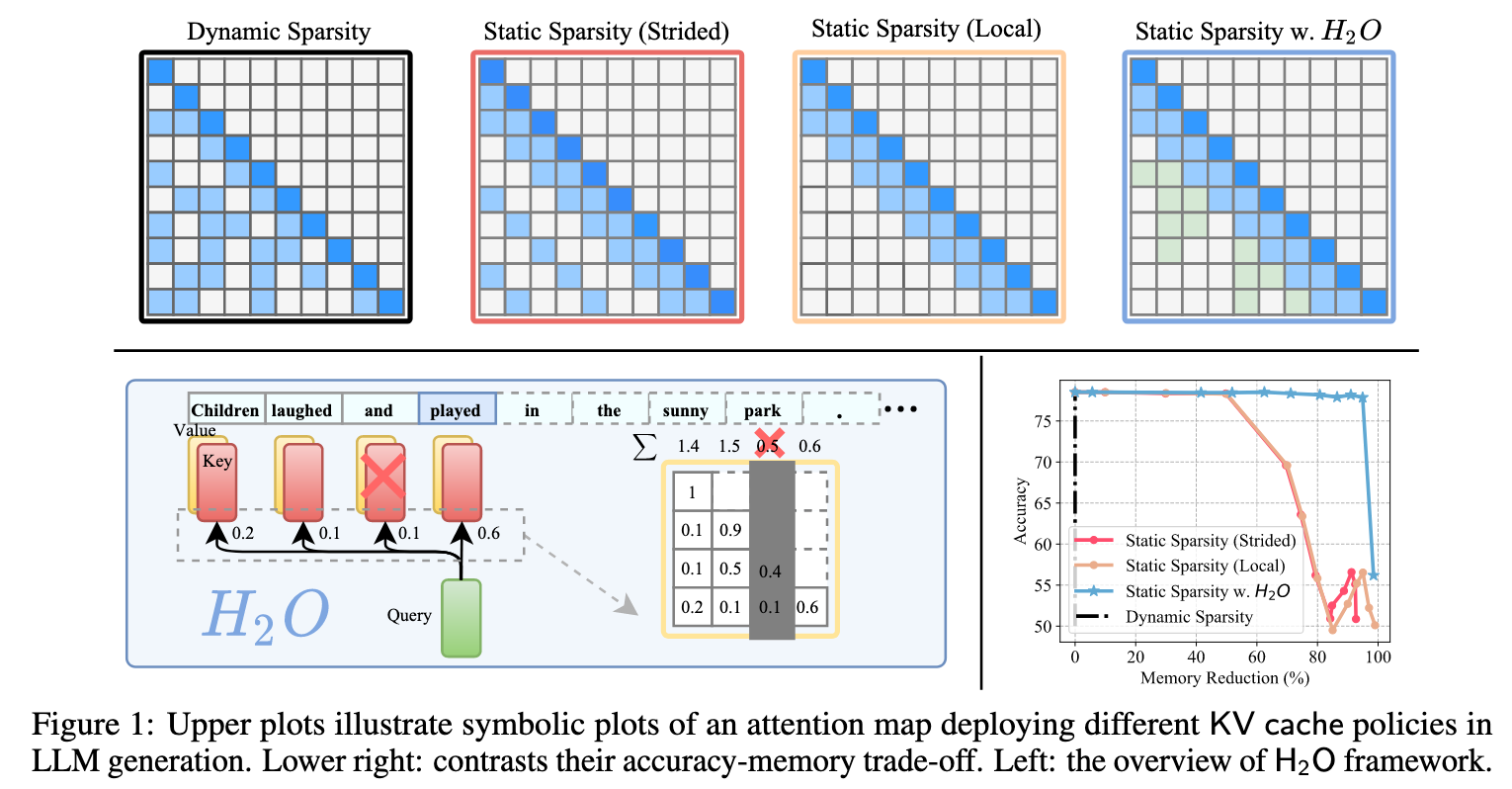
- Inherent Sparsity of Attention
- 推理过程中,其注意力矩阵表现出极高的稀疏性,超过95%的注意力值都非常小。这意味着在生成下一个 token 时,模型实际上只关注了过去所有词元中的一小部分。这为减少 KV Cache 的大小提供了可能性,因为大部分缓存的键值对实际上很少被用到
- Existence of “Heavy Hitters”
- 通过分析词元在注意力计算中的累积得分,作者发现这些得分遵循 Power-law distribution, 这意味着只有一小部分词元 (Heavy Hitters) 贡献了绝大部分的注意力价值。这些 H₂ 词元对于维持模型的性能至关重要,如果将它们从缓存中移除,模型的准确率会急剧下降
- Effectiveness of Local Statistics
- 理论上,要识别出真正的 Heavy Hitters 需要知道未来所有词元的注意力信息,这在自回归生成中是不现实的。
- 论文通过实验发现,仅使用局部信息——即在每个解码步骤中,根据已经生成的词元来计算和累积注意力分数——来动态确定 H₂,其效果与使用全局信息几乎一样好。
Note
既然不是所有的历史信息都同等重要,那么就可以设计一种智能的缓存管理策略,只保留那些最关键的信息,从而在有限的显存中实现高效推理。
Approaches
论文提出了 H₂O (Heavy-Hitter Oracle) 缓存驱逐策略。其核心是在有限的缓存空间里,动态地保留两类最重要的信息:
- Heavy Hitters (H₂) Tokens:那些被证明对全局上下文理解至关重要的词元。
- Recent Tokens:最近生成的几个词元,它们对维持局部语义的连贯性至关重要。
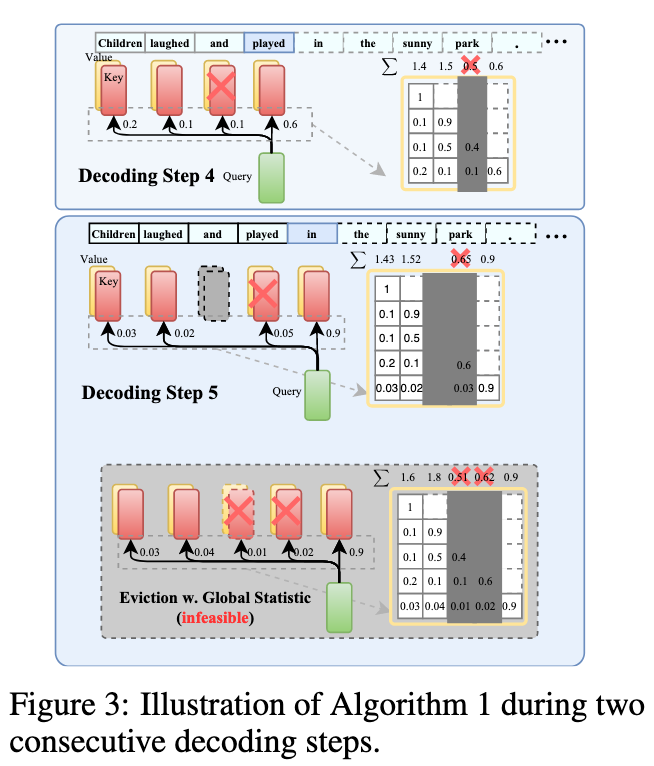
算法流程:
- 初始化与填充:在推理开始阶段,KV缓存尚未满时,所有生成词元的键值对(KVs)都会被存入缓存。
- 分数累积:在每一个解码步骤,模型都会计算新生成的词元对缓存中所有历史词元的注意力分数。这些分数会被累加到对应历史词元的累积注意力分数上。
- 驱逐决策:当缓存已满,需要为新的词元腾出空间时,H₂O 策略会启动:
- 它会保留一个固定大小的窗口用于存放最近生成的词元,确保局部上下文的完整性。
- 在余下的缓存空间中,它会根据所有“非最近”词元的累积注意力分数进行排序。
- 分数最低的那个词元被认为是“最不重要”的,其对应的 KV 将被从缓存中驱逐。
Implementation
最重要的是理解 attn_weight 这个矩阵:(q_tokens, k_tokens)
Code Review
utils_hh/modify_llama.py
下面这个文件来自于官方仓库:
- 计算注意力分数,选出 heavy hitters
- 用 mask 屏蔽不重要的 tokens(让它们的注意力权重≈0)
- 但保存了完整的 KV Cache
该脚本模拟了 H2O 的选择逻辑,但是没有减少 KV Cache 的内存占用
import os
import pdb
import copy
import math
import numpy as np
from dataclasses import dataclass
from typing import Optional, Tuple, Union, cast
import torch
from torch import nn
import torch.utils.checkpoint
import torch.nn.functional as F
from torch.cuda.amp import autocast
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
from transformers.models.llama.configuration_llama import LlamaConfig
from transformers.models.llama.modeling_llama import (
LlamaRotaryEmbedding,
LlamaAttention,
apply_rotary_pos_emb,
)
__all__ = ["convert_kvcache_llama_heavy_recent", "LlamaAttention_heavy_hitter"]
class LlamaAttention_heavy_hitter(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: LlamaConfig):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.max_position_embeddings = config.max_position_embeddings
if (self.head_dim * self.num_heads) != self.hidden_size:
raise ValueError(
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
f" and `num_heads`: {self.num_heads})."
)
self.q_proj = nn.Linear(
self.hidden_size, self.num_heads * self.head_dim, bias=False
)
self.k_proj = nn.Linear(
self.hidden_size, self.num_heads * self.head_dim, bias=False
)
self.v_proj = nn.Linear(
self.hidden_size, self.num_heads * self.head_dim, bias=False
)
self.o_proj = nn.Linear(
self.num_heads * self.head_dim, self.hidden_size, bias=False
)
self.rotary_emb = LlamaRotaryEmbedding(
self.head_dim, max_position_embeddings=self.max_position_embeddings
)
self.heavy_budget_ratio = config.heavy_ratio
self.recent_budget_ratio = config.recent_ratio
self.attention_masks_next = None
self.heavy_budget = None
self.recent_budget = None
self.cache_budget = None
self.previous_scores = None
self.input_length = []
self.cache_budget_records = []
def _reset_masks(self):
self.attention_masks_next = None
self.heavy_budget = None
self.recent_budget = None
self.cache_budget = None
self.previous_scores = None
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return (
tensor.view(bsz, seq_len, self.num_heads, self.head_dim)
.transpose(1, 2)
.contiguous()
)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
output_attentions: bool = False,
use_cache: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
bsz, q_len, _ = hidden_states.size()
# query_states/key_states/value_states -> (batch_size, num_heads, seq_len, head_dim)
query_states = (
self.q_proj(hidden_states)
.view(bsz, q_len, self.num_heads, self.head_dim)
.transpose(1, 2)
)
key_states = (
self.k_proj(hidden_states)
.view(bsz, q_len, self.num_heads, self.head_dim)
.transpose(1, 2)
)
value_states = (
self.v_proj(hidden_states)
.view(bsz, q_len, self.num_heads, self.head_dim)
.transpose(1, 2)
)
kv_seq_len = key_states.shape[-2]
if past_key_value is not None:
kv_seq_len += past_key_value[0].shape[-2] # += cache len
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
query_states, key_states = apply_rotary_pos_emb(
query_states, key_states, cos, sin, position_ids
)
# [bsz, nh, t, hd]
if past_key_value is not None:
# reuse k, v, self_attention
# NOTE: after cat operation, q-> seq_len, k/v -> kv_seq_len due to selected heavy hitters
# (batch_size, num_heads, kv_seq_len, head_dim)
key_states = torch.cat([past_key_value[0], key_states], dim=2)
value_states = torch.cat([past_key_value[1], value_states], dim=2)
past_key_value = (key_states, value_states) if use_cache else None
# (batch_size, num_heads, seq_len, kv_seq_len)
attn_weights = torch.matmul(
query_states, key_states.transpose(2, 3)
) / math.sqrt(self.head_dim)
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
raise ValueError(
f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
f" {attn_weights.size()}"
)
# causal mask, elements: 0.0 or -inf
if attention_mask is not None:
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
)
attn_weights = attn_weights + attention_mask
# prevent overflow
attn_weights = torch.max(
attn_weights, torch.tensor(torch.finfo(attn_weights.dtype).min)
)
# H2O mask, elements: 0.0 or 1.0
# 1.0 means keep, 0.0 means drop
# raw: [0.5, 0.3, 0.2, 0.1]
# applied: [0.5, -65504, -65504, 0.1]
if self.attention_masks_next is not None:
attn_weights = (
attn_weights * self.attention_masks_next
+ (1 - self.attention_masks_next) * torch.finfo(attn_weights.dtype).min
)
# upcast attention to fp32
attn_weights = nn.functional.softmax(
attn_weights, dim=-1, dtype=torch.float32
).to(query_states.dtype)
# attn_weights (BS, heads, q-tokens, k-tokens) 16, 15, 15 // 16, 1, 16
# NOTE: sum on the batch_size dim? I guess H2O only support single request
# sum(0) here is just to remove the dim
# sum(1) sum on the q-tokens dim
# 得到每个 head 中,k-tokens 的注意力分数的列累加值
# 也就是 k-tokens 目前的累计的注意力分数
current_scores_sum = attn_weights.sum(0).sum(1) # (heads, k-tokens)
# offset = attn_weights.gt(0).sum(0).sum(1)
# Accumulate attention scores
# current_scores_sum: (heads, k-tokens)
# previous_scores: (heads, k-tokens - 1)
if self.previous_scores is not None:
# align and accumulate historical scores
current_scores_sum[:, :-1] += self.previous_scores # (Enlarged Sequence)
else:
# initialize
self.heavy_budget = int(
self.heavy_budget_ratio * current_scores_sum.shape[-1] # k-tokens
)
self.recent_budget = int(
self.recent_budget_ratio * current_scores_sum.shape[-1] # k-tokens
)
self.cache_budget = self.heavy_budget + self.recent_budget
self.cache_budget_records.append(self.cache_budget)
self.input_length.append(attn_weights.shape[-1])
# current_scores_sum = current_scores_sum / offset
dtype_attn_weights = attn_weights.dtype
attn_weights_devices = attn_weights.device
assert attn_weights.shape[0] == 1
self.previous_scores = current_scores_sum # (heads, k-tokens)
# attn_mask: (heads, k-tokens + 1)
# prepare attention mask for next step
attn_mask = (
torch.ones(current_scores_sum.shape[0], current_scores_sum.shape[1] + 1)
.to(dtype_attn_weights)
.to(attn_weights_devices)
)
attn_tokens_all = self.previous_scores.shape[-1] # k-tokens
self.cache_budget = cast(int, self.cache_budget)
self.recent_budget = cast(int, self.recent_budget)
self.heavy_budget = cast(int, self.heavy_budget)
if attn_tokens_all > self.cache_budget:
# activate most recent k-cache
if not self.recent_budget == 0:
# exclude recent k tokens, all others are set to 0
attn_mask[:, : -self.recent_budget] = 0
selected_set = self.previous_scores[:, : -self.recent_budget]
else:
# activate historical best self.cache_budget - self.recent_budget tokens.
# self.previous_scores # (k-Cache - 1)
attn_mask[:, :] = 0
selected_set = self.previous_scores
if not self.heavy_budget == 0:
# selected_set: (heads, k-tokens - recent_budget)
_, keep_topk = selected_set.topk(
k=self.heavy_budget, dim=-1, largest=True
)
# keep_topk: (heads, heavy_budget)
attn_mask = attn_mask.scatter(-1, keep_topk, 1)
# reshape attn_mask to (1, heads, 1, k-tokens + 1)
self.attention_masks_next = attn_mask.clone().unsqueeze(0).unsqueeze(2)
score_mask = attn_mask[:, :-1] # (heads, k-tokens)
score_mask[:, -self.recent_budget :] = 1 # ensure recent tokens are all kept
self.previous_scores = self.previous_scores * score_mask
attn_output = torch.matmul(attn_weights, value_states)
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.transpose(1, 2)
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
attn_output = self.o_proj(attn_output)
if not output_attentions:
attn_weights = None
return attn_output, attn_weights, past_key_value
def convert_kvcache_llama_heavy_recent(model, config):
for name, module in reversed(model._modules.items()):
if len(list(module.children())) > 0:
model._modules[name] = convert_kvcache_llama_heavy_recent(module, config)
if isinstance(module, LlamaAttention):
model._modules[name] = LlamaAttention_heavy_hitter(config)
return model