Extensive Reading
Author Info
Background
- MoE LLMs and hybrid setups
- Modern MoE models (DeepSeek, Qwen-MoE, etc.) are huge but activate few experts per token.
- On single-GPU or low-concurrency setups, we naturally pair a small GPU with a big CPU + large DRAM.
- Limitations of current hybrid / offloading systems
- Tools like Fiddler or basic offloading keep attention on GPU and push experts or layers to CPU.
- CPU becomes the bottleneck; generic AMX/AVX-512 kernels are far from peak, and GPU often waits on CPU.
- Hardware inefficiencies on CPU and NUMA
- Poor weight layouts and scheduling starve caches and AMX units.
- Multi-socket (NUMA) machines suffer from cross-socket memory traffic and weak scaling.
- Crude accuracy–latency tradeoffs in MoE
- Existing accelerations often reduce or skip experts (smaller top-k, pruning).
- These approaches speed up inference but can noticeably hurt accuracy.
There are tow major inefficiencies:
- Underutilized CPU compute during the prefill phase
- Current approaches fail to achieve the theoretical peak performance
- Primarily to suboptimal memory layouts
- Inefficient CPU-GPU/CPU coordination during the decode phase
- Excessive kernel launch latency
- Limited CPU-GPU execution overlap
- Multiple NUMA nodes bring challenges to CPU-CPU coordination
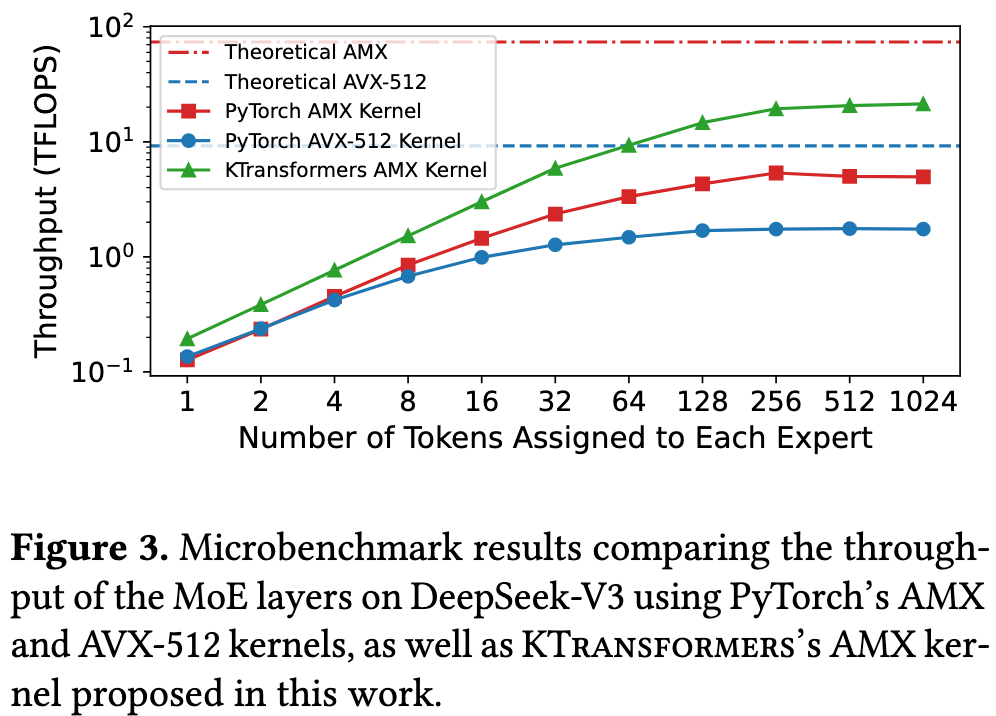
Insights
KTransformers places shared experts on the GPU and routed experts on the CPU.
A mixed-instruction backend optimzied explicitly for MoE workloads on CPUs:
- For prefill stage, use Intel AMX instructions with a specialized memory layout co-designed with AMX tiling
- For decoding stage, use AVX-512 instructions
The paper call this as “Arithmetic Intensity-Aware Hybrid Inference Kernel” – The charm of naming
An asynchronous CPU-GPU task scheduling mechanism
- Encapsulate the entire decode stage into a single CUDA graph instance
Expert Deferral
- Within each MoE layer, only a subset of experts (immediate experts) are processed immediately, while the remaining experts (deferred experts) are scheduled concurrently with the computation of the subsequent layer (primarily the attention module)

Approaches
Unleashing the Full Potential of the CPU
AMX: Intel’s Advanced Matrix Extensions – significantly acclerate dense matrix multiplications
To fully utilize AMX capabilities, KTransformers aligns memory layout with AMX tile registers.
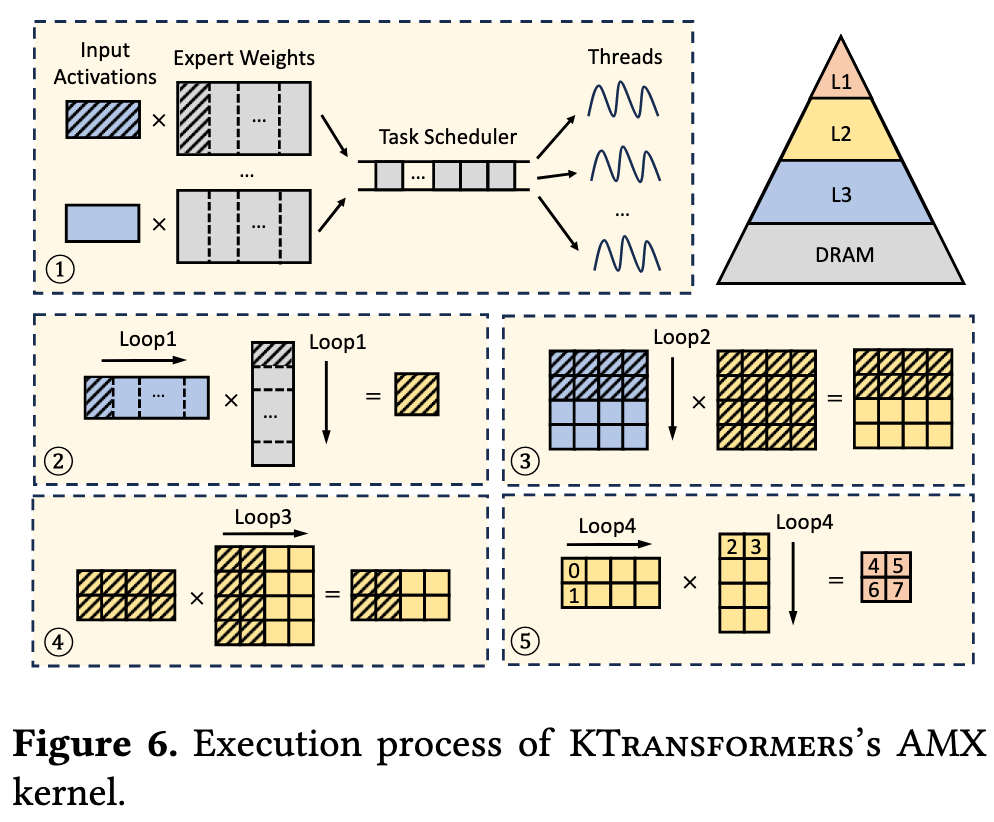
Workflow:
- Expert weight matrices are vertically partitioned into tasks dynamically scheduled across threads, while input activations reside typically in the shared L3 cache
- Because the activations are reused across tasks and accessed often, the hardware naturally keeps them in the shared L3
- KTransformers does not pin activations on L3
- Each task partitions expert weights horizontally into blocks precisely fitting the L2 cache
- We know the approximate L2 size per core
- We choose block dimensions (rows × columns × data type) so that weight block + a slice of activations + partial outputs fit into L2
- Each block comprises AMX tile-sized submatrices
- Tile-level computations use AMX instructions to produce and accumulate results directly in tile registers
- Inside each L2 block, we break data into tile-sized chunks that map exactly to AMX tile registers
KTransformers:
- Chooses tile/block sizes based on L1/L2/L3 capacities
- Designs loop nests so the working set of each level matches a specific cache
In the decoding stage, KTransformers replaces AMX with AVX-512 kernels foe low arithmetic intensity vector-matrix multiplications
AVX-512 is a CPU instruction set for wide vector (SIMD) operations on modern x86 processors (mainly Intel, some AMD). In plainer terms:
- “AVX” = Advanced Vector Extensions
- “512” = it operates on 512-bit wide registers
CPU-GPU/CPU Coordiantion
KTransformers places shared experts on the GPU and routed experts on the CPU.
- CPU-GPU Coordiantion
A naive design must synchronize twice per MoE layer, once when the GPU sends activations to the CPU (submit) and again when the CPU returns its results (sync).
KTransformers encapsulates both submit and sync in cudaLaunchHostFunc, which lets CUDA invoke the callbacks inside the current stream – the entire decoding stage can fit into a single CUDA graph.
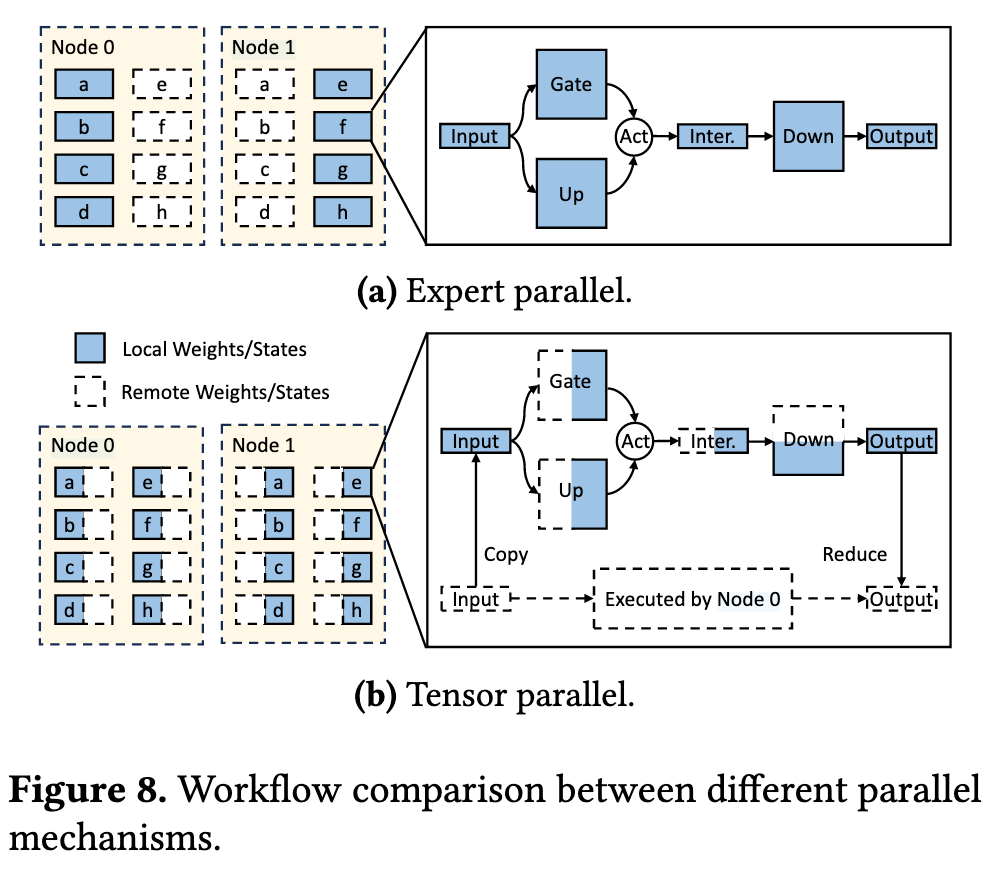
- CPU-CPU Coordiantion
KTransformers choose Tensor Parallel between different CPUs to avoid almost all remote memory traffic and for better balanced work
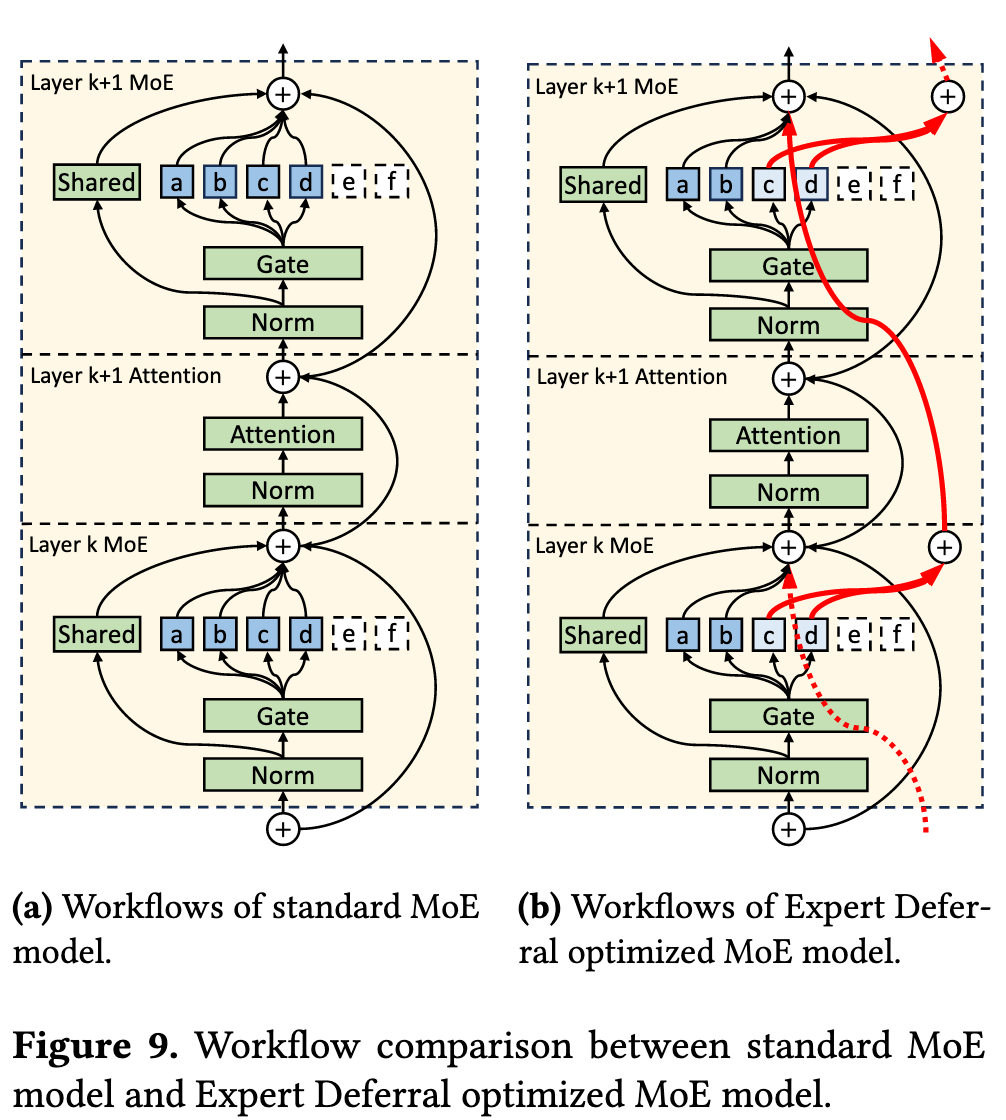
Expert Deferral
In a standard Transformer with MoE, the data flow looks like this at layer (k):
- Input to the layer: $I_k$.
- MoE computes:
- Shared experts on the GPU: $S_k(I_k)$.
- Routed experts on the CPU: $R_k(I_k)$.
- Output of the layer: $$ O_k = I_k + S_k(I_k) + R_k(I_k) $$
- This $O_k$ becomes the input to the attention (or next sublayer) at layer $k+1$.
In a hybrid system, step 3 means we must wait for all routed experts to finish before feeding $O_k$ into layer $k+1$.
KTransformers introduces a twist:
At each MoE layer, we split the routed experts into two groups:
- Immediate experts: their outputs contribute to the next layer’s input as usual.
- Deferred experts: their outputs are injected one layer later.
Let’s denote:
- $R_k^{\text{imm}}(I_k)$: immediate experts at layer $k$.
- $R_k^{\text{def}}(I_k)$: deferred experts at layer $k$.
Then for layers in the middle of the network, we change the layer output computation to something like:
$$ O_k = I_k + S_k(I_k) + R^{\text{def}}_{k-1}(I_{k-1}) + R^{\text{imm}}_k(I_k) $$Intuitively:
- The deferred outputs from the previous layer $k-1$ arrive here and are added into $O_k$.
- The immediate experts at the current layer still influence the next layer directly.
- The deferred experts at the current layer will show up at layer $k+1$.
Expert deferral enables greater CPU-GPU overlap and improved hardware utilization
An intuitive idea: Transformers are residual networks