Extensive Reading
Author Info
- About Me — Tim Dettmers: A research scientist at the Allen Institute for Artificial Intelligence (Ai2) and an incoming Assistant Professor at Carnegie Mellon University (CMU).
- Mike Lewis - Google Scholar
Related Blogs
- LLM.int8() and Emergent Features — Tim Dettmers
- A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using transformers, accelerate and bitsandbytes
Background
常见的 8 bit 量化有两种:
- Absmax quantization
- 在所有数据中,找到绝对值的最大值,我们称之为
abs_max,然后计算一个全局的 scaling factor - 用数据中的每一个数字乘以这个 scaling factor, 再四舍五入到最近的整数完成量化
- 在所有数据中,找到绝对值的最大值,我们称之为
- Zeropoint Quantization
- 找到数据中的最大值和最小值,计算 scaling factor
- 同时引入一个偏移量 zeropoint 来利用整个映射后的数值范围
- 精度更高,但是开销更大
Challenges
- How to preserve high quantization precision at scales beyond 1B parameters?
- How to deal with the systematic outliers emerged in all transformer layers starting at scales of 6.7B parameters?
Insights
- Regular quantization methods introduce larger quantization errors for outliers.
- The amount of outlier can be small, but contributes the majority to the LLM’s quality.
- Isolate the outlier feature dimensions into a 16-bit matrix multiplication while other values are multiplied in 8-bit.
Approaches
主要包括两部分内容:
- Vector-wise Quantization: 对传统 Tensor-wise Quantization 的改进,主要用于处理常规数值。
- Mixed-precision Decomposition: 用于处理 outliers.
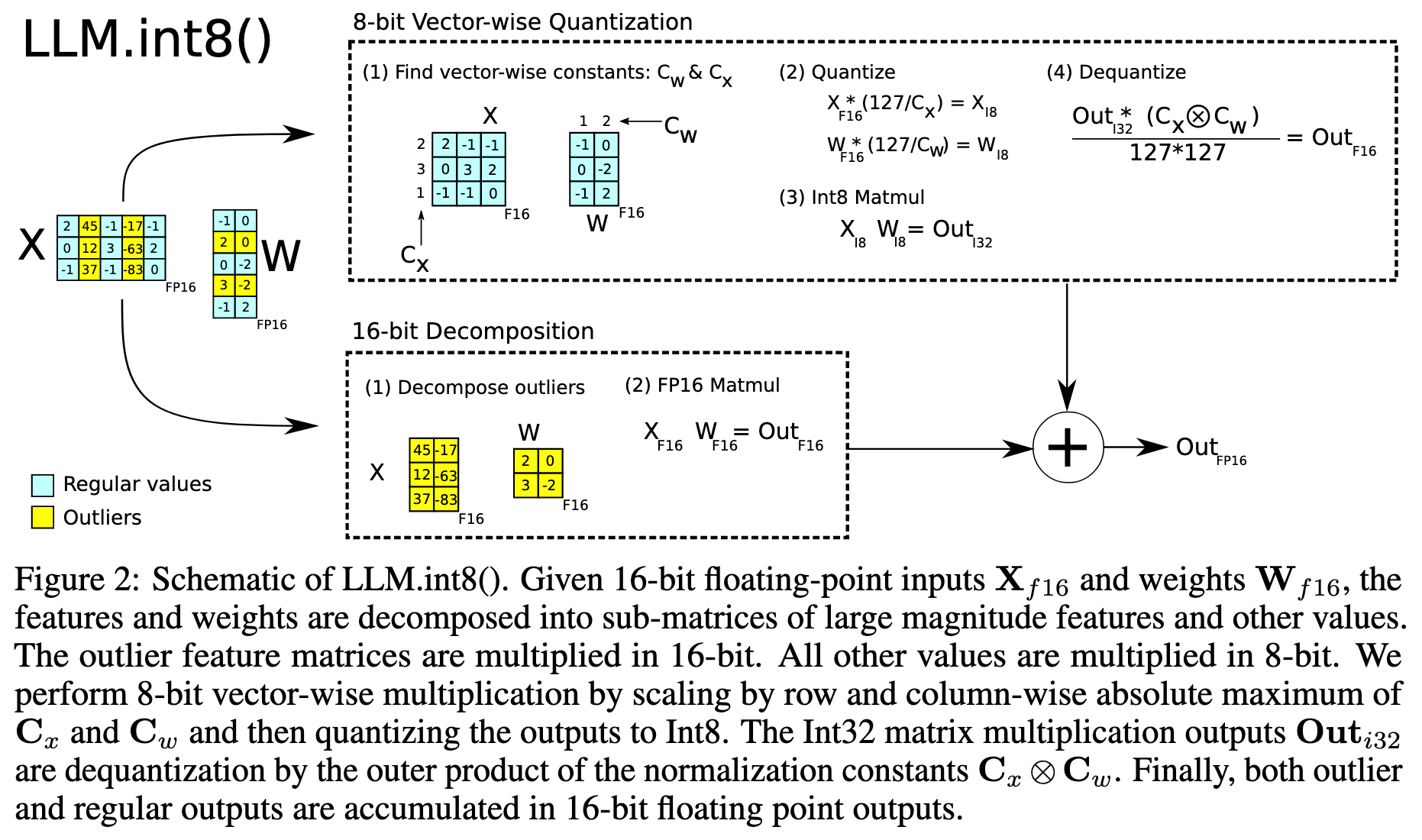
Vector-wise Quantization
向量级量化其实就是现在常说的 Per-channel Quantization,没什么区别。
考虑机器学习中两个矩阵 X 和 W 的计算 X @ W.T
- 只要对 X 和 W 都采用按行量化,实际在计算内积时就是 X 的 Per-row 和 w.T 的 Per-col
Mixed-precision Decomposition
LLM.int8()的核心创新点。
可以分为两个阶段:
- 模型加载阶段
- 对模型原始的 16 位权重进行向量级量化,转换位 INT8
- 推理阶段
- 模型的某一层接收到来自上一层的输入 X 时
- 实时检查矩阵 X 的所有数值,根据一个阈值把特征维度 (X 的列) 划分为常规和离群
- 进行混合精度分解计算
- 离群路径:
X中被识别为离群的列,会与W中对应的行(以 FP16 格式)进行 16 位浮点数矩阵乘法 - 常规路径:常规列实时地进行向量级量化 (Per-row) 转换为 INT8, 与 INT8 格式的权重矩阵进行计算
- 离群路径:
- 最后合并结果
Note
LLM.int8()不做离线 Profiling,只在推理阶段做实时分析
Question
- 有些工程上的细节没有讲清楚,比如在离群路径中, W 的 FP16 格式是从哪里来的,显存中不是只保存了 INT8 类型的权重吗?
- 是将 INT8 类型的权重反量化?
- 还是重新从硬盘中读取原始的 FP16 的权重?
- Update: 根据源码,FP16 格式的权重保存在内存中
Evaluation
着重关心一下性能问题:
- 对于小型模型,
LLM.int8()的量化开销会减慢推理速度 - 对于大型模型,
LLM.int8()能保持与 FP16 基线相当的端到端推理性能
Thoughts
When Reading
LLM.int8() 不需要离线分析,只是在线动态分解,在每次实际推理时,实时检查当前输入 X 的每一个值,看其绝对值是否超过一个固定的阈值,超过阈值后就被划分为离群维度进行处理。
这样做的开销是不是挺大的?