Extensive Reading
Author Info
Background
Long-context LLM serving is bottlenecked by attention and KV caches. Prefilling has quadratic attention cost in sequence length, while decoding is memory-bound due to ever-growing KV caches; this makes 128k–512k contexts and long reasoning traces (e.g., 20k-token CoT) slow and expensive in practice.
Existing KV cache optimizations are incomplete. Quantization and compression methods (e.g., KV quantization, paged KV cache) reduce memory and bandwidth but do not change the asymptotic attention complexity, so latency still grows linearly (decoding) or quadratically (prefilling) with context length.
Existing sparse attention methods are fragmented and limited. Static sparsity (e.g., StreamingLLM, H2O, TOVA) can hurt long-context accuracy or clash with GQA and paged KV layouts, while dynamic sparsity (e.g., MInference, Quest) often targets only one stage (prefill or decode) and struggles to integrate cleanly with quantization and GPU-friendly block execution.
Insights
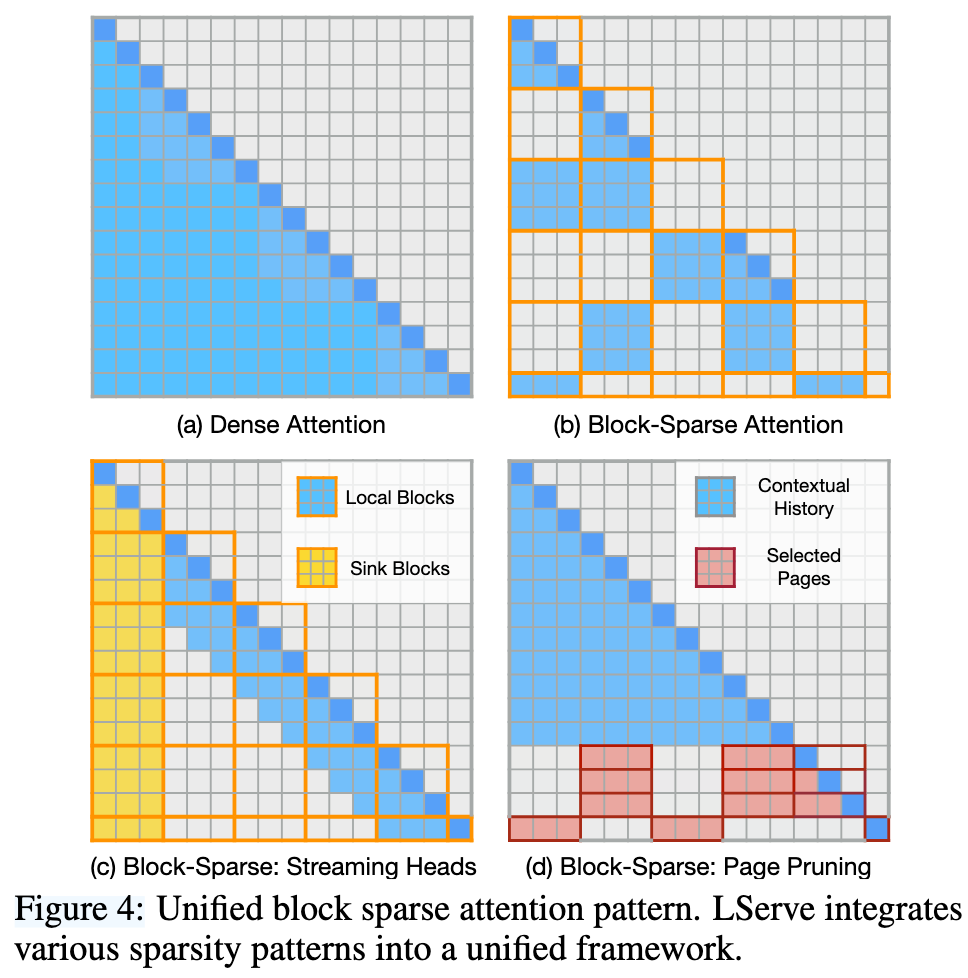
- Unified Block Sparse Attention
- Split the KV sequence into blocks (pages)
- For each block, decide: compute or skip
- Design sparsity patterns that can be expressed as “which blocks are active for this head / token”
Prune inside a block cannot gain much performance improvements due to the charterartisc of GPUs
Sparsity can further be divided into static and dynamic sparisity:
- Static sparsity
- Converting half of the attention heads into streaming-heads, which only care about the X (intiatial sink tokens) + Y (recent tokens), the remaining heads are retreval heads, which are responsible for long context information processing
- Dynamic sparsity
- The required number of KV tokens to maintain long-context capabilities remains constant (e.g., 4096), regardless of context length. We can dynamically slect the KV tokens based on the query.
Prequsitions
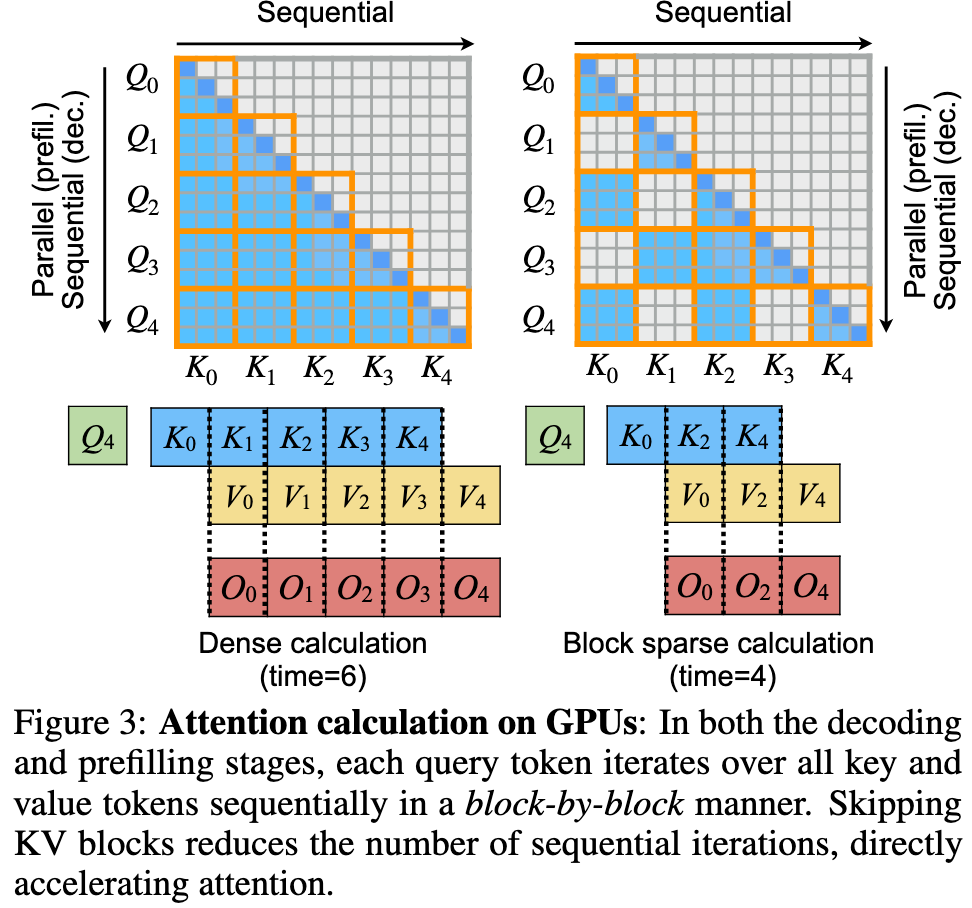
Why? K1,V0,O0 are in the same colunm
Approaches
Overview
Architecture changes:
- Statically parition the attention heads into two groups
- Dense heads: retreval heads which need full attention
- Streaming heads: focus on the sink tokens and the recent tokens
- Co-design sparate KV caches for different heads
- Dense heads: full context with key statistics that facilitate page selection during the decoding phase
- Streaming heads: only include
X+Ytokens
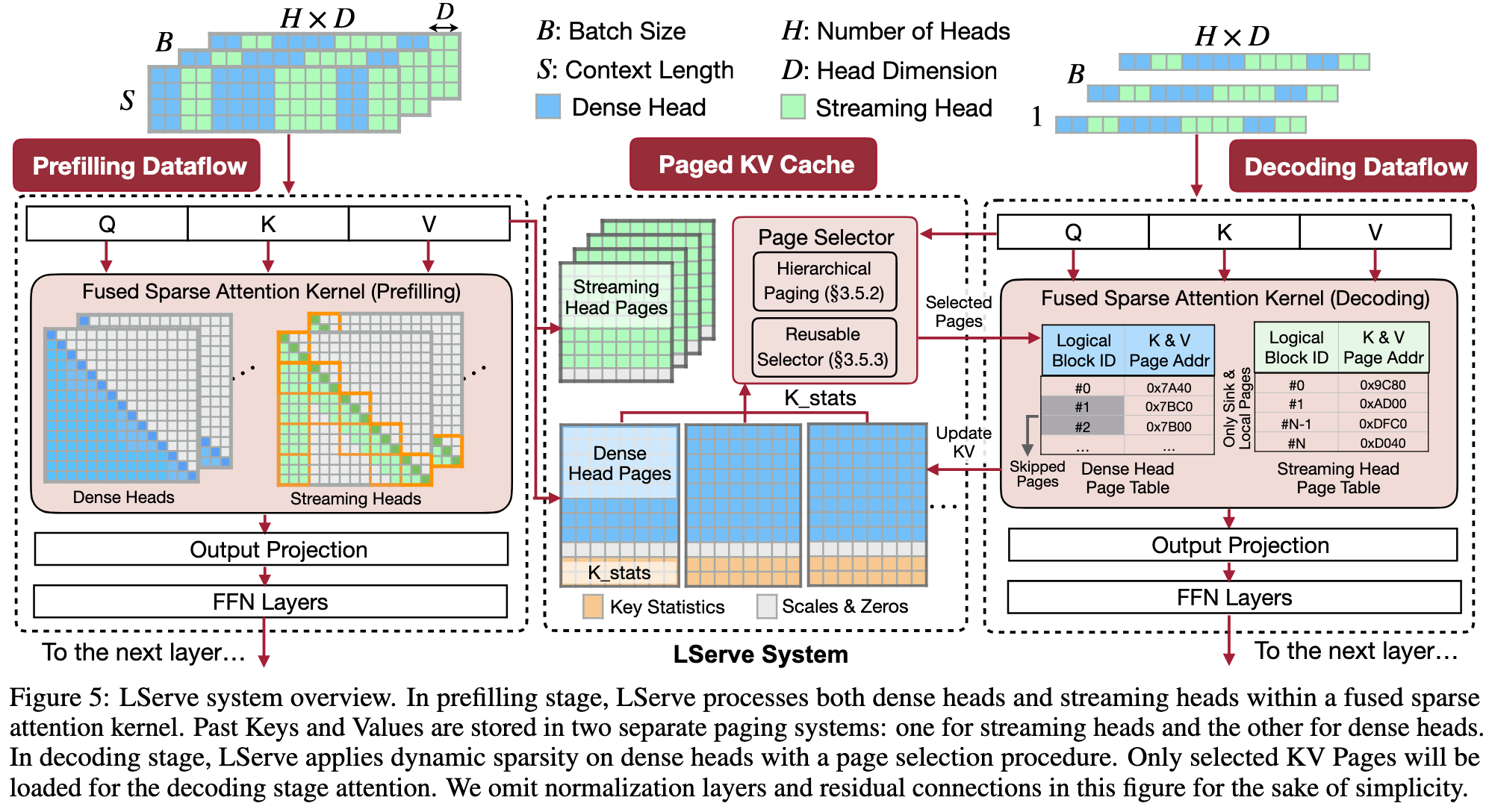
Prefilling Stage
Using static sparsity
Use retreval heads and streaming heads
Implementation:
Iterators are determined outside the attention kernel:
int active_blocks[num_active];
compute_active_blocks(active_blocks); // done once outside the hot loop
for (int i = 0; i < num_active; ++i) { // loop only over used blocks
int b = active_blocks[i]; // b is the real block id
load_block(b); // direct offset computation
compute_attention(b);
}
Decoding Stage
Introduce dynamic sparsity upon the dynamic sparsity
There is a dilemma between KV cache quantization and page selections
- Reducing the bit-width of KV tokens necessitates large page size
- Precisely selection pages needs smaller page size
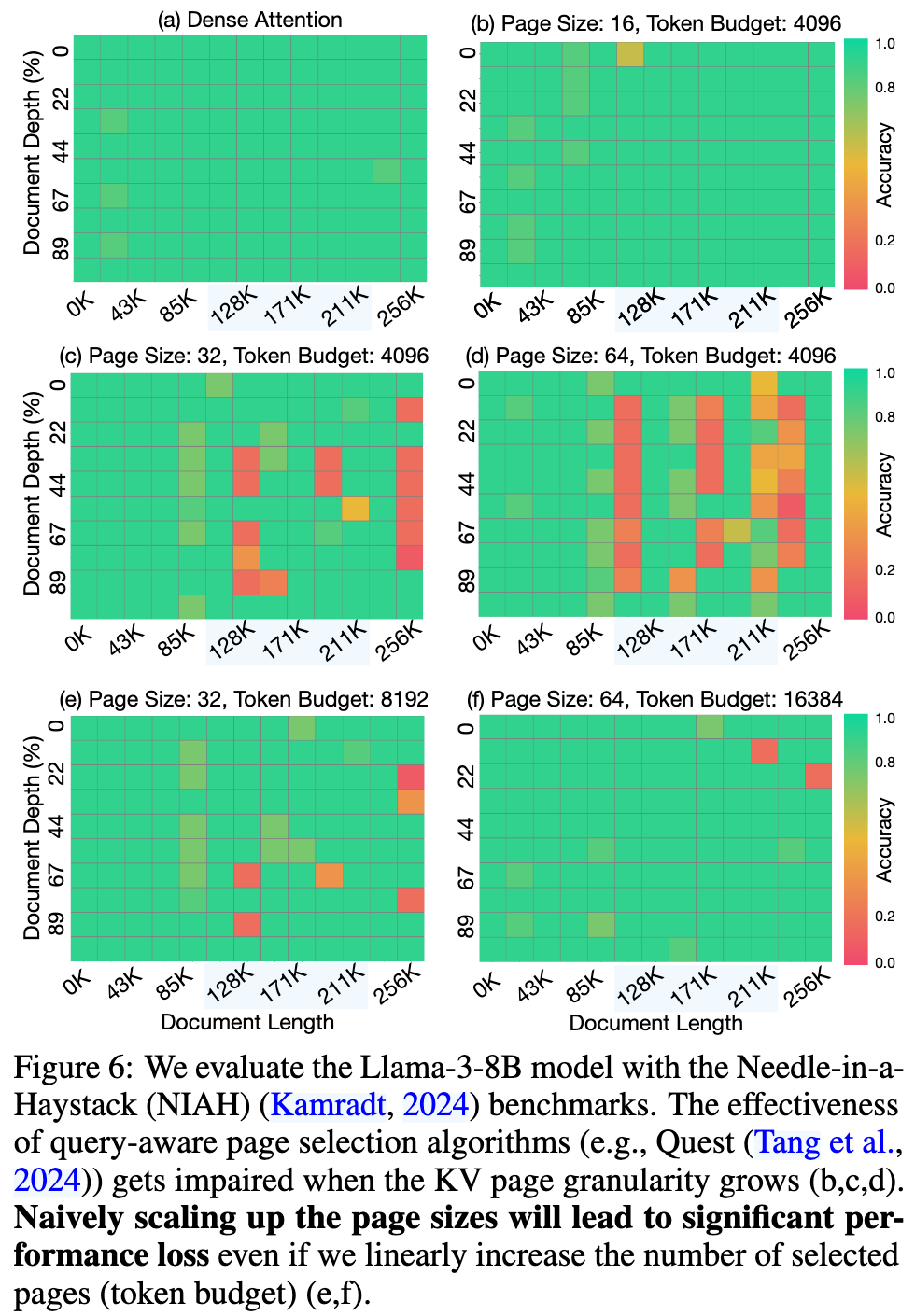
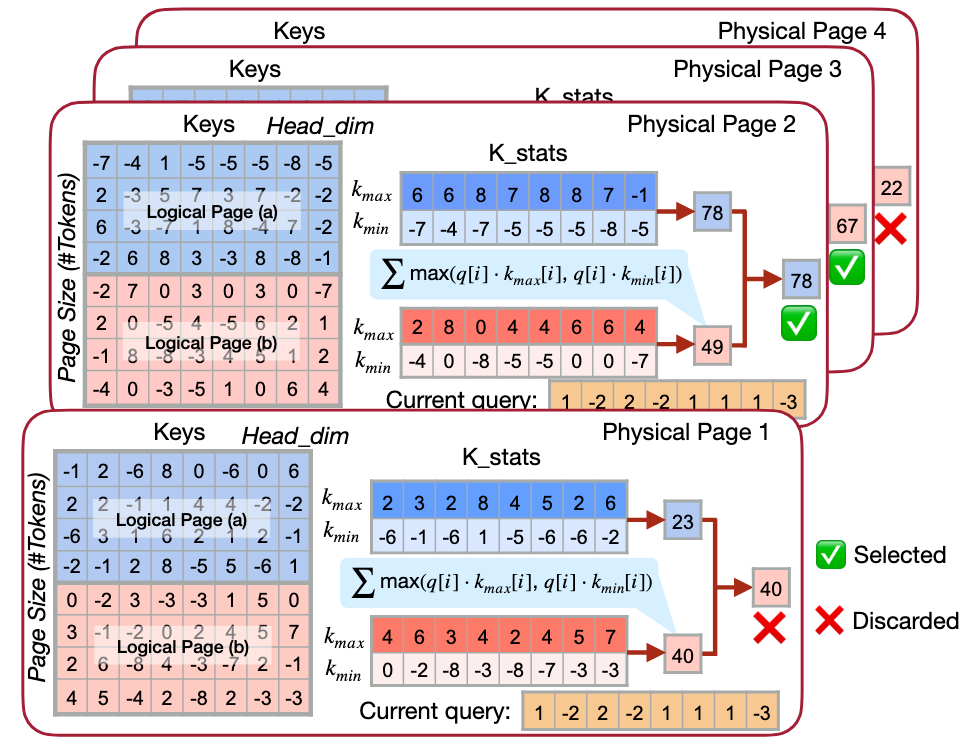
Authors observe that the failure of query-aware KV cache selection paradigm is not due to the coarser granularity of sparse attention, the underlying cause lies in that page-wise statistical indicators become homogenized and less representative.
To address this issue, LServe proposes an abstract layer of virtual logical page: A physical page may contain multiple logical pages
The score of a physical page is the max scores of its logical pages
To further reduce the page selection overheads, LServe introduce two kinds of localities:
- Spatial locality
- Important content tends to live in contiguous regions of the sequence, so important pages are clustered in position, not scattered randomly
- Effectively alleviates the need fot a increased token budget
- Temporal locality
- Adjacent query tokens heavily attend to similar historical pages
- The page selection decision can be shared across queries
Evaluation
Thoughts
When Reading
This work seems like an engineering aggregation from different papers in MIT Han Lab:
- DuoAttention to split attention head to retrieval heads and stream heads
- StreamingLLM’s KV Cache design (
X sink tokens + Y recent tokens) for streaming heads - Quest’s KV Cache page selection for retrieval heads in the decoding phase
- QServe for KV quantization