Intensive Reading
Author Info
- About Ting Cao - Dr. Ting Cao: A Professor at the Institute of AI Industry Research (AIR), Tsinghua University.
Background
Challenges
- 挑战一:如何准确地识别出下一步计算到底需要哪些“活跃权重” 。如果识别错误,会降低模型的准确度。
- 挑战二:如何能足够早地预测出需要的活跃权重,从而将缓慢的闪存加载过程与当前的计算过程并行处理,以隐藏延迟。
- 现有的一些方法依赖 ReLU 激活函数来预测稀疏性,但这不适用于 Llama 等为追求高精度而未使用 ReLU 的现代 LLM.
Insights
利用了 Top-K 的稀疏性,实现了在非 ReLu 上的权重值预测和预取
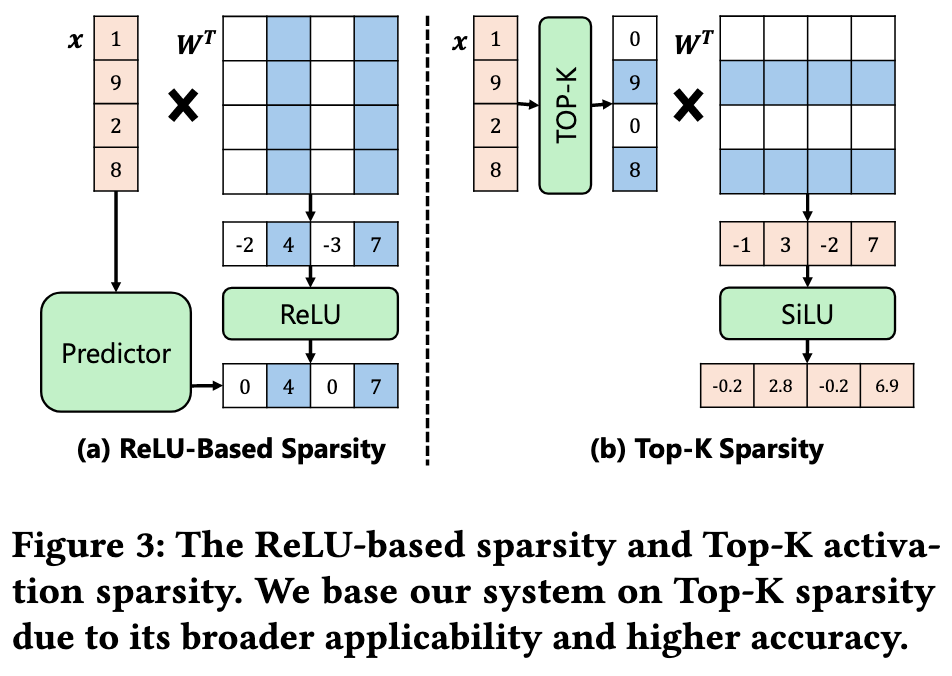 论文提出了两个核心观察:
论文提出了两个核心观察:
- Similarities in Cross-Layer Activations
- The input activations of the attention and MLP blocks in LLMs exhibit high cross-layer similarity due to residuals to the input activations.
- 由于激活值相似度很高,所以用当前层最重要的 K 个激活通道去预测下一层最重要的 K 个激活通道,准确度也很高
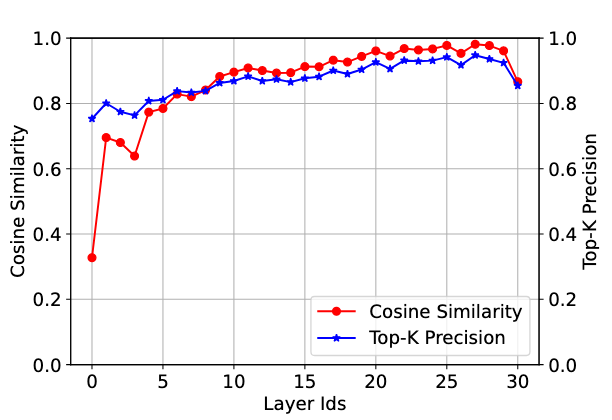
- Contextual Hot Active Weights During Decoding
- Contextual active weights exhibit high temporal locality across inference iterations during decoding.
- 在一个具体的对话或任务中(上下文层面),“热点权重”的重复使用率,远高于在所有通用任务中(任务层面)的平均重复使用率
- 所以根据上下文的激活频率设计缓存会更有效(缓存命中率会更高)
Approaches
Cross-Layer Active Weight Preloading
当计算第 N 层时,ActiveFlow 利用第 N 层的激活值来预测并提前加载第 N+1 层到第 N+k 层(一个“层组”)所需要的活跃权重
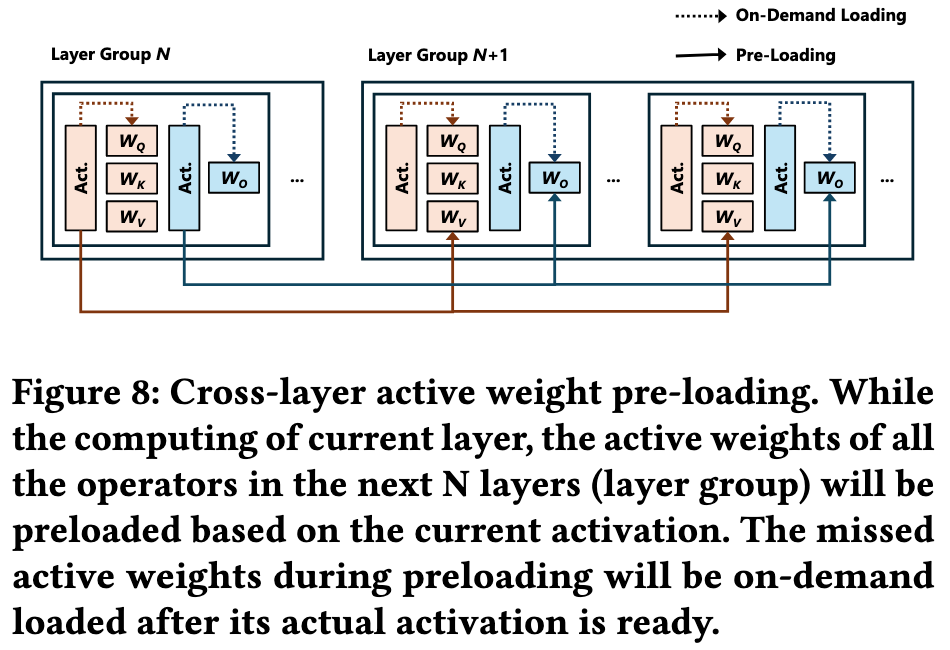
和 LLM in a flash 的观察一样,IO 每次读的块越大,IO 吞吐量越高,所以 ActiveFlow 为了让预加载更高效,它还对存储在闪存中的权重布局进行了重排,将多个层中相同 channel 的权重存储在一起。这样,一次I/O操作就可以读取多个层的同一部分权重,显著增大了数据块大小,从而最大化闪存的读取带宽。

- 在常规的 LLM 权重布局中,数据是按层、按算子(Operator)顺序存储的 。比如,存储完第10层的所有权重(Wq, Wk, Wv…),再存储第11层的所有权重。这导致如果要预加载第10、11、12、13层中同一个“通道 C”的权重,这4块数据在物理上是分散在闪存的四个不同位置的,系统需要进行4次独立的、小数据块的读取操作。
- ActiveFlow 提出的新的存储顺序是根据
算子类型 -> 通道 ID -> 层 ID(从大到小)来组织的。这样一来,所有层中同一个通道的权重在物理上就变成了连续存储。当系统需要预加载某个活跃通道时,它可以一次性将后面多个层对应的权重作为一个大的连续数据块读取出来,极大地提升了加载效率。
每个层只有 Wq 和 Wk 两个权重矩阵,每个矩阵只有3个通道(Channel 0, 1, 2)。我们要处理一个由2个层(第10层和第11层)组成的“层组”。
|-- 第10层 --|-- 第11层 --|
[Wq_Ch0, Wq_Ch1, Wq_Ch2, Wk_Ch0, Wk_Ch1, Wk_Ch2] [Wq_Ch0, Wq_Ch1, Wq_Ch2, Wk_Ch0, Wk_Ch1, Wk_Ch2]
重排后的布局
|---- Wq ----|---- Wk ----|
[Ch0_L10, Ch0_L11] [Ch1_L10, Ch1_L11] [Ch2_L10, Ch2_L11] [...]
Active Weight Swapping Pipeline
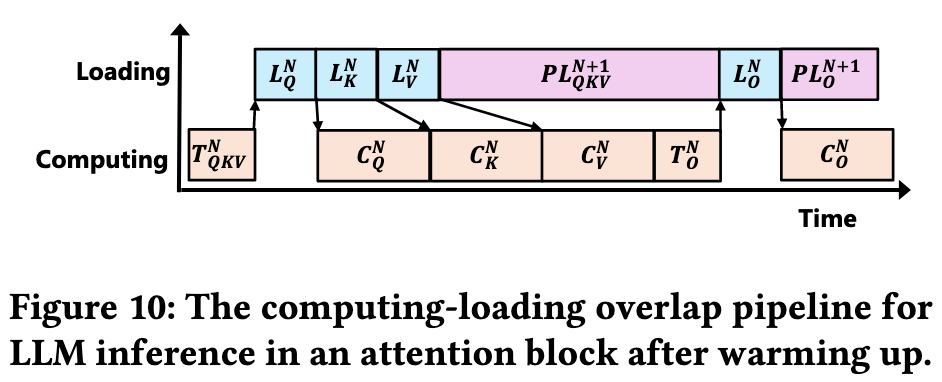
The pipeline consists of four main operations:
- Computing (C) – Performs the required computations.
- Top-k (T) - Extracts the top-k mask from activations to determine the indices of the activated weight channels.
- On-demand loading (L) – Loads weights for the current layer group.
- Preloading (PL) – Preloads weights for the next layer group.
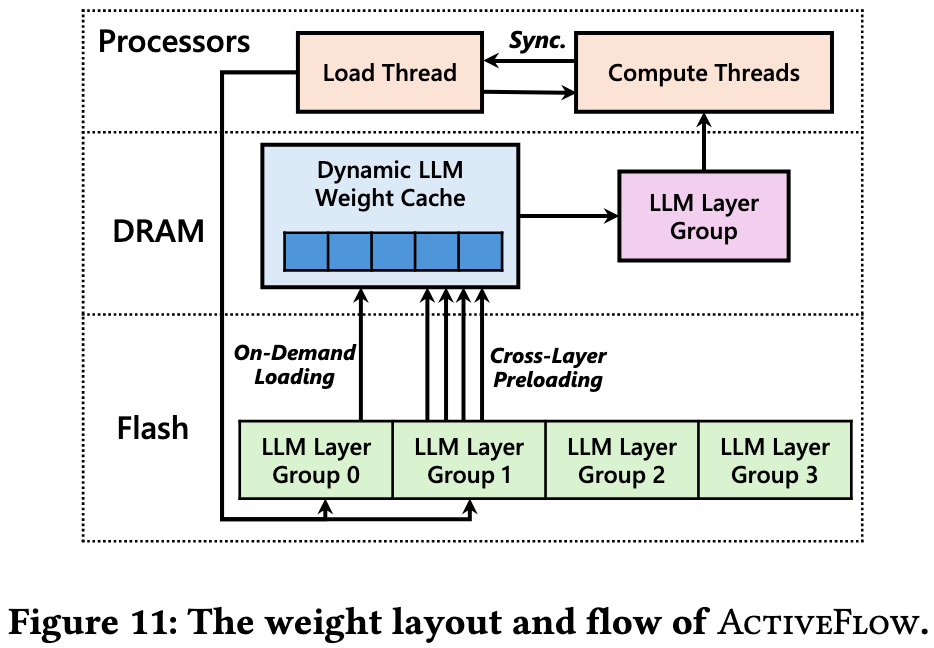
空间上,它将完整的、经过重排的模型权重存放在大容量但慢速的闪存中,只将计算必需的活跃权重和热点权重放在高速但容量有限的DRAM中。
时间上,它通过“跨层预加载”技术,让负责I/O的“加载线程”和负责计算的“计算线程”协同工作,实现了“计算当前层组,同时预加载下一层组”的高效循环,从而最大程度地隐藏了从闪存读取数据所带来的延迟。
4.1 部分的数学建模跳过
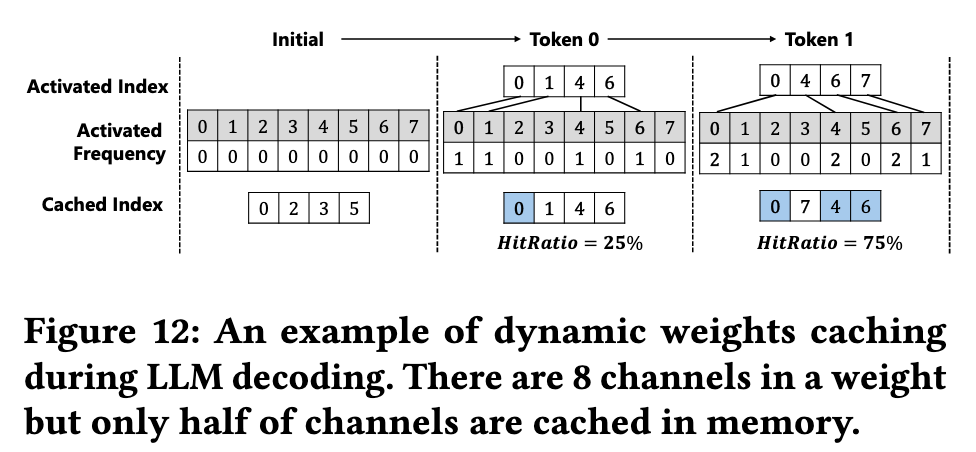
ActiveFlow 通过上下文的激活频率设计了缓存
Self-Distillation for Top-K Sparse LLM
Self-distillation uses the full model’s output distribution as a soft target to preserve essential distributional details and weight correlations.
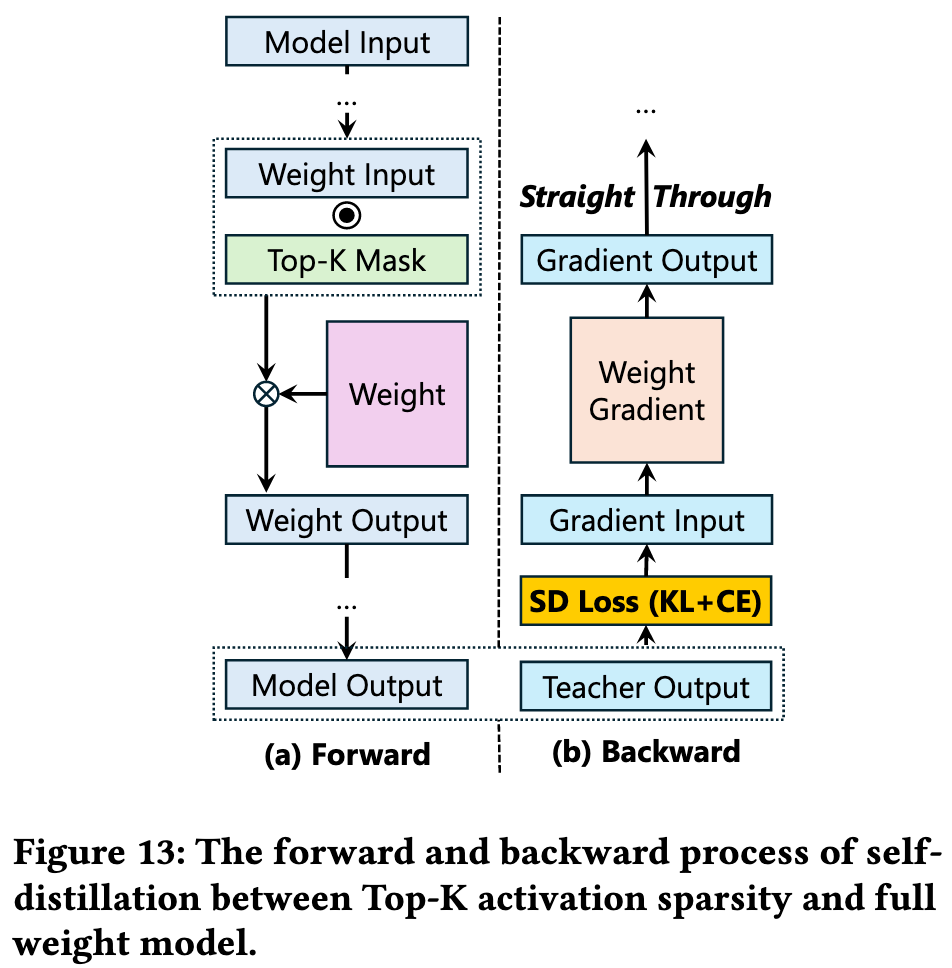
对于反向传播时遇到的挑战,ActiveFlow 使用了两个技术:
梯度直通估计 (Gradient Straight-Through Estimation, STE):为了解决稀疏化导致的大量梯度为零、模型难以训练的问题,该方法在反向传播时绕过了稀疏掩码(mask)的梯度清零效应,确保模型参数能得到有效更新。
组合损失函数: 使用了KL散度(Kullback-Leibler Divergence)和交叉熵(Cross-Entropy)组合的损失函数,以更好地对齐稀疏模型和全量模型的输出。
Evaluation
Thoughts
When Reading
这篇文章每张图都画得很好,干净简洁,一看就懂,值得学习!
再温故一下 contextual sparsity 的定义
再温故一下 hot active weights 中 hot 和 active 的含义
contextual sparsity 强调 active: small, input-dependent sets of attention heads and MLP parameters that lead to (approximately) the same output as the full model for an input
- contextual sparsity 和 power law distribution 强调的不同,以及对应的优化策略方向?
Related Works
- ToRead: Training-Free Activation Sparsity in Large Language Models.