Extensive Reading
Author Info
SEC: CCF C
Background
Insights
Pure implementation of Speculative decoding in edge scenarios
- Edge device holds draft models
- Edge servers holds verifier models
Approaches
Route to the server when the confidence score associated with token generated by the edge device falls below a given threshold
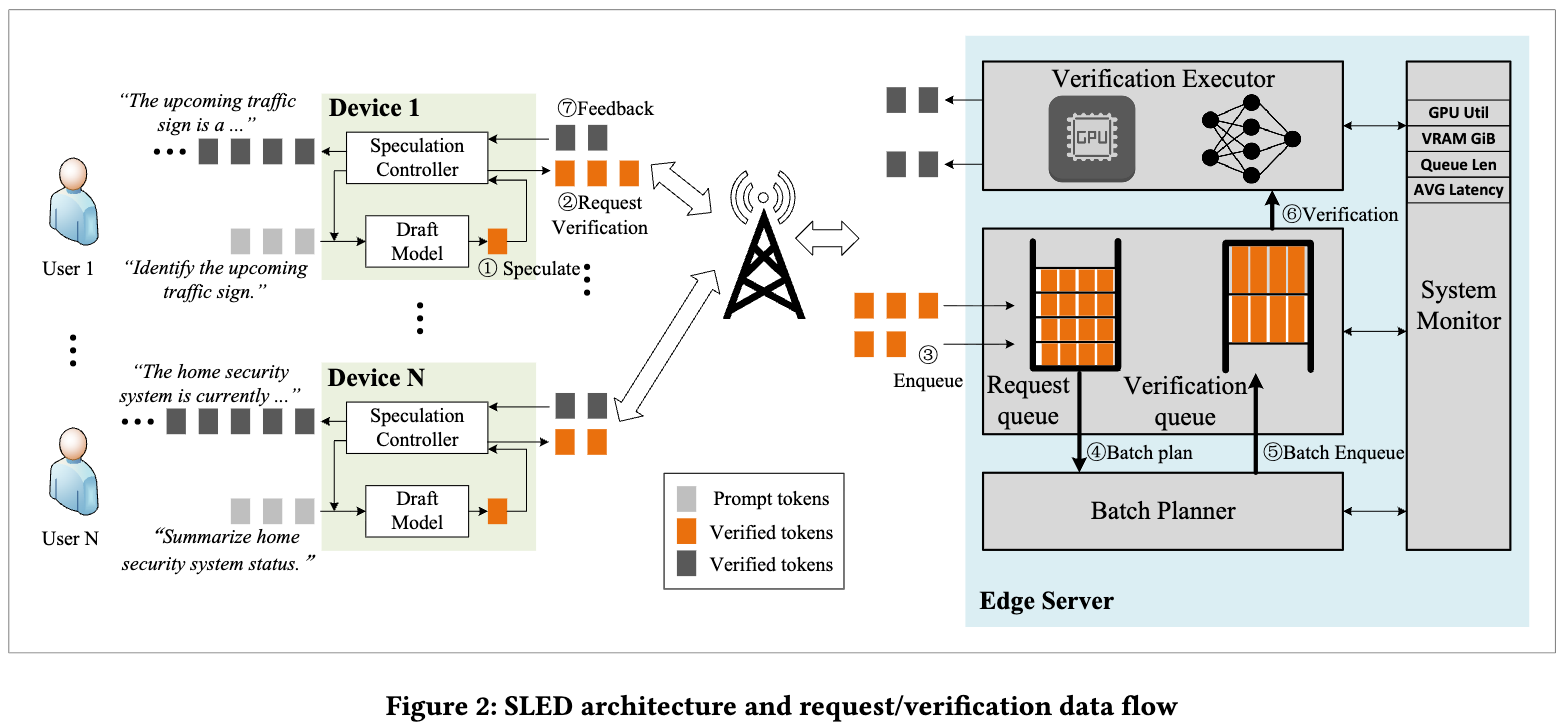
Two details:
- When sending tokens to the server, the edge device keeps generating draft tokens, expecting the verifier would accept all sent tokens
- When retrying due to network issues, the edge device can append new generated tokens to the draft sequence
Evaluation
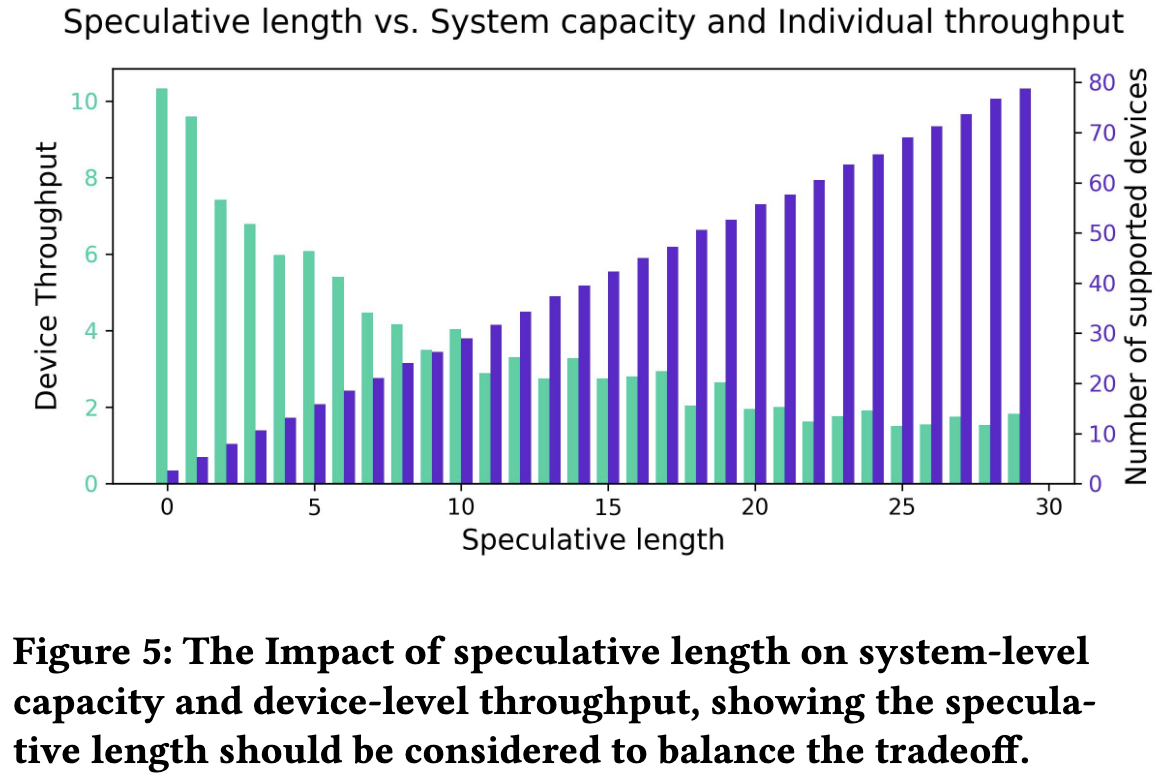
推测长度增加对系统性能存在 Trade-off:
- 设备吞吐量下降:推测长度增加会导致验证延迟 Verification Latency 变长,从而拖慢单个设备的最终响应速度。
- 系统容量上升:推测长度增加会降低设备向服务器发送请求的频率,减轻服务器负载,使其能支持更多并发设备
Thoughts
When Reading
没有和 SOTA 比较
Edge device 和 Edge Server inference 的 overlap 已经是一个比较工程的优化了,没有创新