Extensive Reading
Author Info
Background
- Generative LLM inference is characterized by two distinct phases: a compute-intensive prompt computation phase and a memory-intensive token generation phase, each with unique resource demands.
- Current systems run both phases on the same powerful, expensive GPUs, which is inefficient because the memory-bound token generation phase underutilizes the advanced compute resources of the hardware.
- This inefficiency is worsening as new GPUs (like the H100) increase compute power much faster than memory bandwidth or capacity, leading to higher-than-necessary costs and power consumption for large-scale deployments.
Challenges
- The memory-intensive token generation phase, which accounts for the majority of end-to-end latency, severely underutilizes the expensive compute resources of modern GPUs.
- This inefficiency is exacerbated by hardware trends, as new GPUs (like the H100) provide massive compute gains (3.43x) but much smaller increases in memory bandwidth (1.6x) and no increase in capacity, making them poorly suited for the memory-bound token phase.
- Running both distinct phases on the same machine leads to inconsistent latencies and resource contention , forcing providers to over-provision expensive, power-hungry hardware to meet service level objectives (SLOs).
Insights
- Prefill phase is compute-intensive, and decoding phase is memory-intensive, decoding does not need the compute capability of the latest GPUs and can be run with lower power and cost.
Approaches
在提出具体方法之前,论文的很大部分篇幅都是在说明 LLM Inference 的一些特性,这些特性对 Splitwise 方法的设计有着非常大的影响
- Batch utilization
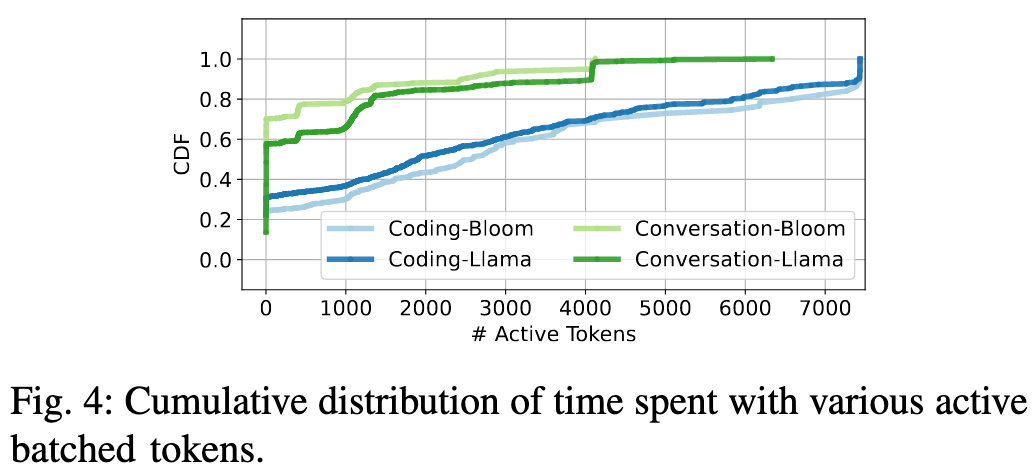
主流的 chunked prefill 方法对 GPU 的利用率不高:
- 对于“对话”任务,GPU 在 60-70% 的时间里,处理的活跃令牌数不超过 20 个 。
- 对于“编码”任务(通常输出很短),情况更糟:超过 20% 的时间里,GPU 只在处理区区 1 个活跃令牌 。
我感觉这个统计方法有点牵强
- Latency
先简单明确一下:
- FTFF: 由 Prefill phase 造成,该阶段需要并行计算大量的 prompt token, 所以是 compute-bound
- TBT: 由 Decoding phase 造成,该阶段每轮读取模型完整的权重只能生成一个 Token,大量的时间用于内存访问,所以是 memory-bound
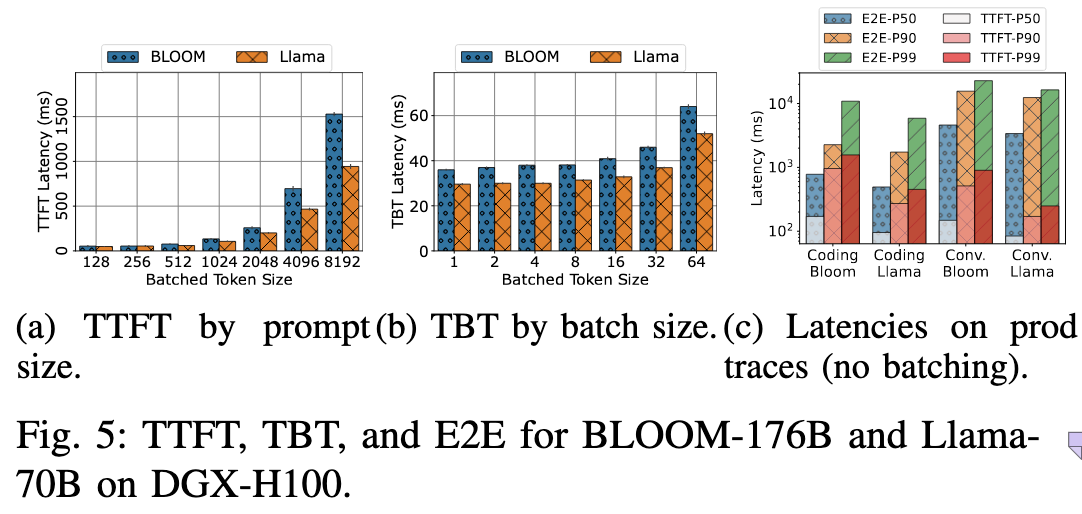
所以在 Figure 5a 中,原本就为 compute-bound 的 prefill phase 增加更多的 token,延迟也会成比例增加;但是在 Figure 5b 中,处理的 token 数增加了 64 倍,延迟才变为了之前的两倍
其实这张图的上的 Batched Token Size 很有启发性,我们是不是可以认为,Prefill 阶段和 Decoding 阶段特性的不同,其实就是因为每个阶段处理的 Batch Token Size 不同?
比如 Decoding 阶段处理的 Batch Token Size 足够大,也会从 memory-bound 变为 compute-bound?
在 {Chunked Prefill} 这篇文章中,有着进一步的分析
- Throughput
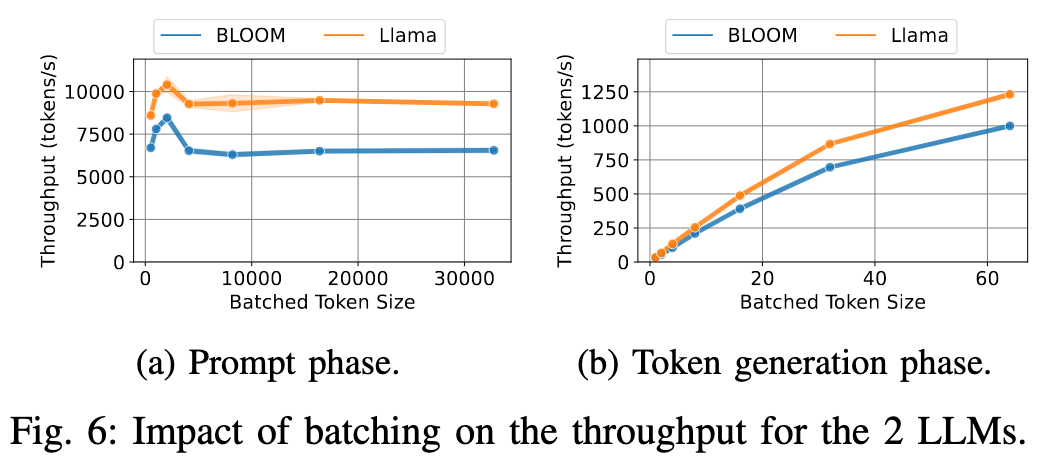
Figure 6 其实是从另一方面(Throughput)展示了 Figure 5 的情景:Decoding 阶段 GPU 的算力使用还未饱和,使用更大的批次意味着更大规模的并行计算,吞吐量更高,GPU 的利用率也就越高;同时我们也应该限制 Prefill 阶段的 batch size,让其达到最好的性能
- Memory Utilization
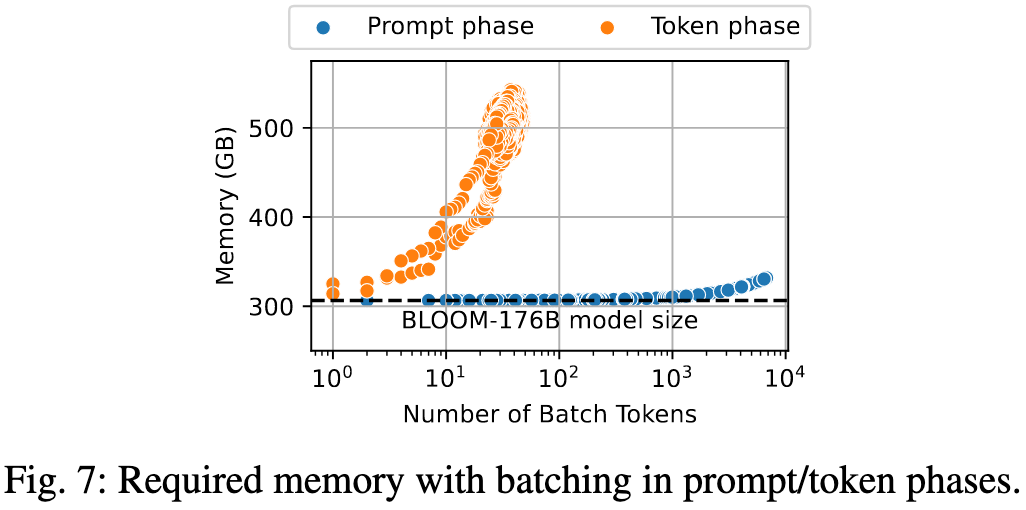
Figure 7 展示了两个阶段 batching 对 memory 的占用情况:
- prefill phase 的 batched token 包括了 prompt 的长度,但是 decoding 阶段的没有
- 比如同样是 100 个 batched tokens, prefill 阶段就是一个长度为 100 的输入序列,而 decoding 阶段就是 100 个输入,每个输入的历史长度也可能为 100
所以我们可以看出,阻碍 decoding 阶段进行超大批次并行计算的核心原因就是内存不够
进一步分析,其实是因为在 decoding 阶段每一个 request 都有自己的 KV cache,KV cache 的体积不容忽视,所以如何管理这些 KV cache 也是一个非常重要的问题,可以参考 Efficient Memory Management for Large Language Model Serving with PagedAttention
- Power Utilization
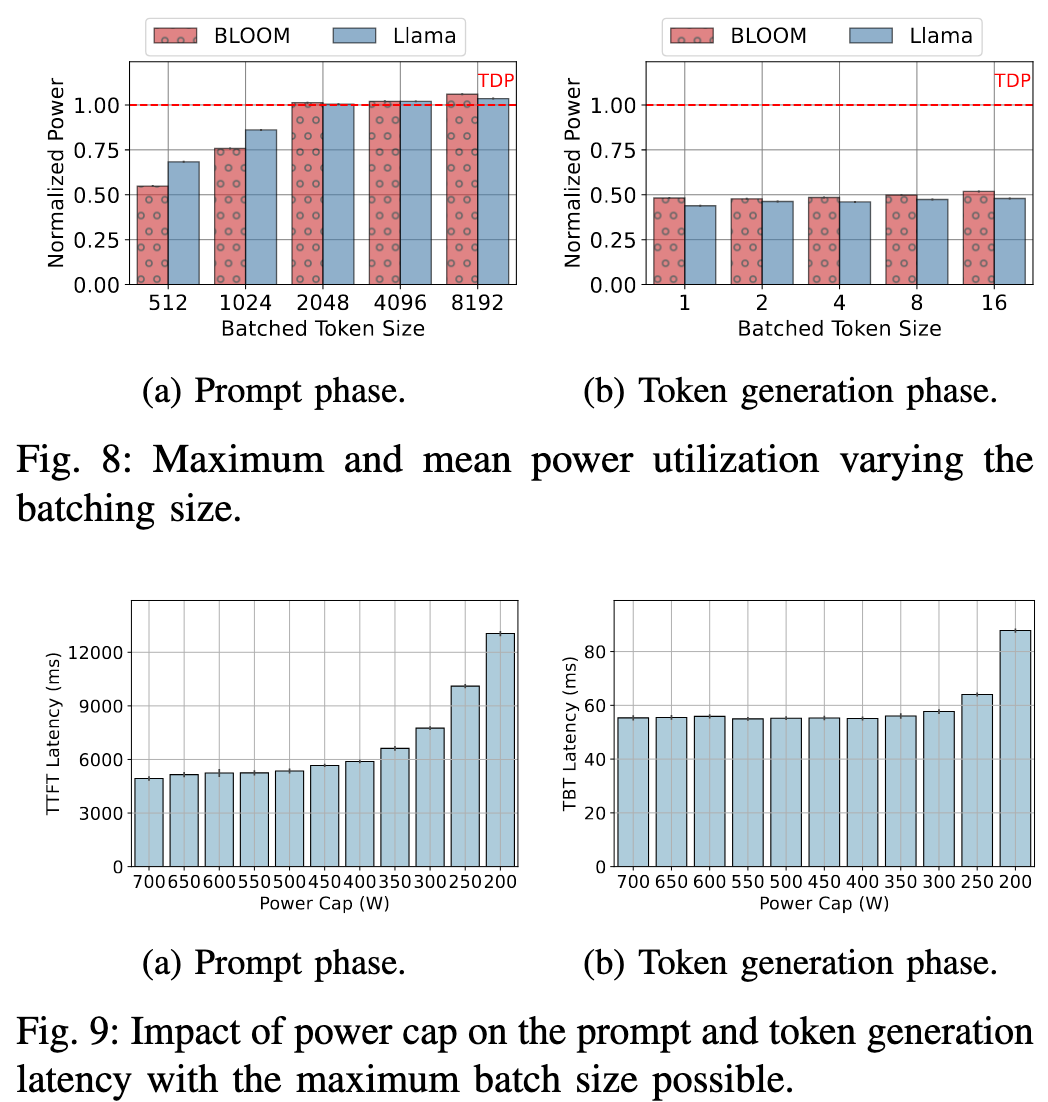
一句话总结就是,decoding 阶段由于计算没有满载,对低功率容忍性更高
- GPU hardware
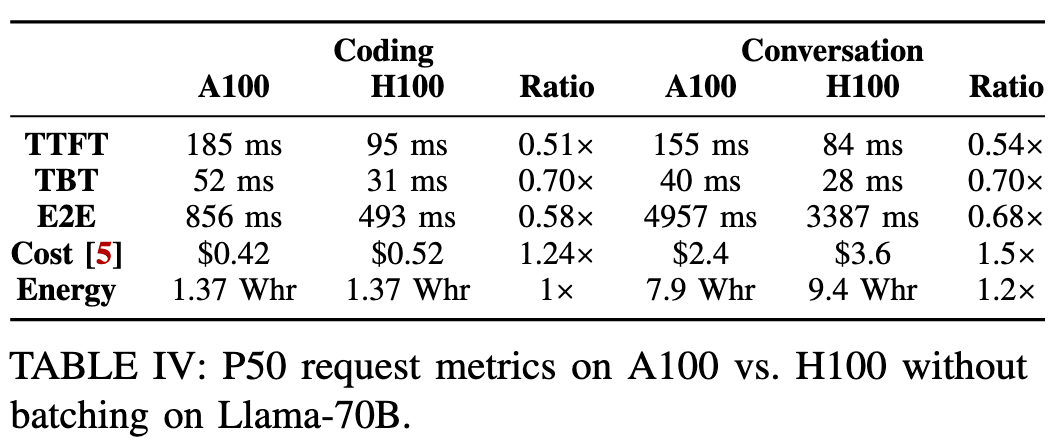
核心观点为:使用昂贵的最新 GPU (H100) 来运行“令牌生成”阶段是一种巨大的浪费,使用老一代的 GPU (A100) 反而更具性价比和能效比。
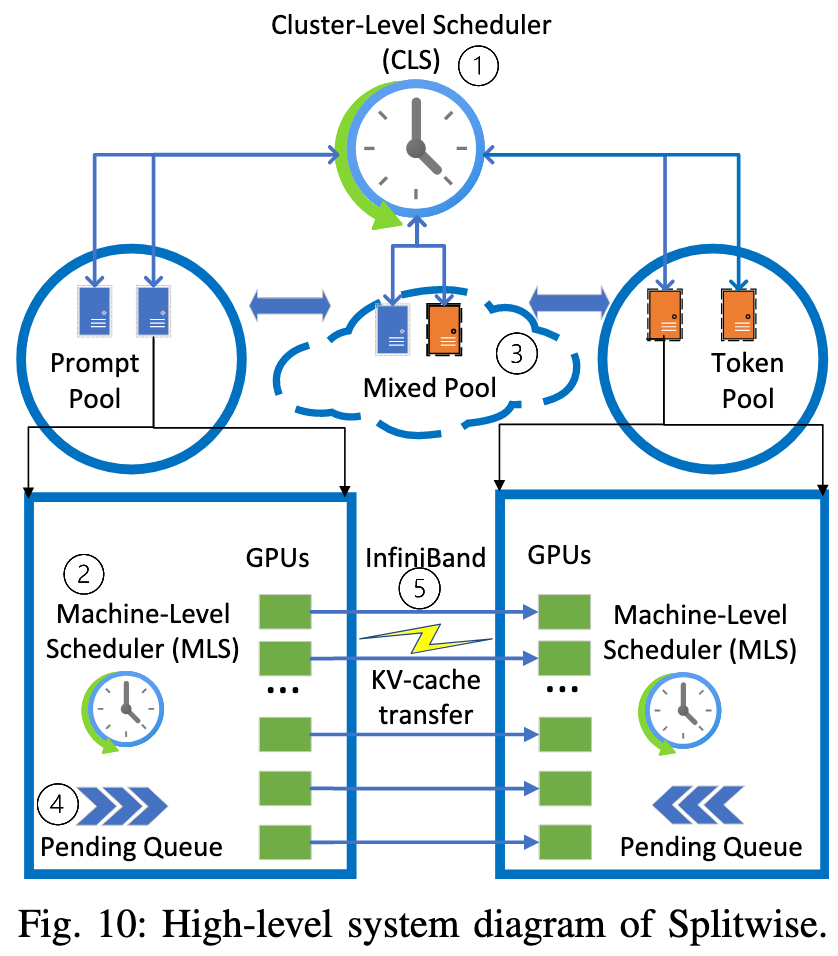
基于上述的这些特性观察,Spiltwise 的架构也很简单
- 专门的机器池
- Prefill pool
- Decoding pool
- Mixed Pool: 在高负载下动态调整两个池的机器
- 分级调度系统
- Cluster-Level Scheduler
- 当一个新请求到达时,CLS会使用“加入最短队列”(JSQ)策略,同时为该请求分配一对机器:一台来自“提示词池”和一台来自“令牌池”
- Machine-Level Scheduler
- 在 prefill machine 上:会限制总的批处理Token数(例如2048),以避免性能下降
- 在 decoding machine 上:尽可能地聚合更多请求,直到达到内存容量上限
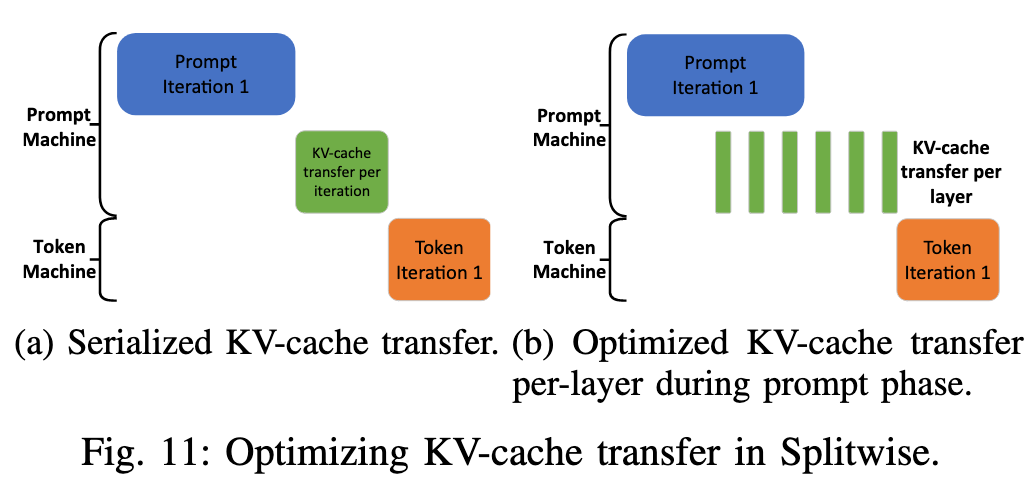
- 跨节点 KV Cache 传输
- 采用 Pipeline 的方式,一层 transformer layer 完成计算后,这一层的 KV cache 就已经确定了,可以通过异步的方式从 prefill machine 传输到 decoding machine
最后论文给出了两种方案:
- Splitwise-HA: H100 跑 Prefill, A100 跑 Decode
- Splitwise-HHcap: 正常的 H100 跑 Prefill, 低功耗的 H100 跑 Decode