Skimming
Author Info
Implementation and Benchmark
Corresponding virtualization is here
Background
Challenges
Insights
- Ring attention suffers from workload imbalance
- Due to the casual mask mechanism, some devices are doing meaningless computations in the iterations while other devices stays busy all the time.
- Stripped attention propose an another way to distribute workloads across devices to eliminate the imbalance.
Approaches
Striped Attention 让每个设备都持有了在原始序列中均匀分布的、不连续的词元
Example
理解这个例子最重要的一点:Ring Attention 和 Striped Attention 都不是采用朴素的注意力计算
- 朴素的注意力计算会先计算完整的 $QK^T$ 矩阵,然后再应用 causal mask, 被遮蔽的是计算结果,计算过程没有被遮蔽
- Ring Attention 和 Striped Attention 都是采用了 FlashAttention, 核心思想是不一次性计算整个 $QK^T$ 矩阵,而是把它切成很多 tiles,逐 tiles 计算,并在计算每个 tiles 之前进行检查。
FlashAttention 以及 Ring/Striped Attention 能够逐 tile 计算的关键前提是 online softmax.
假设有 3 个设备(设备 0、设备 1、设备 2),以及一个包含 12 个词元的输入序列。
序列 (Sequence): [T_0, T_1, T_2, T_3, T_4, T_5, T_6, T_7, T_8, T_9, T_10, T_11]
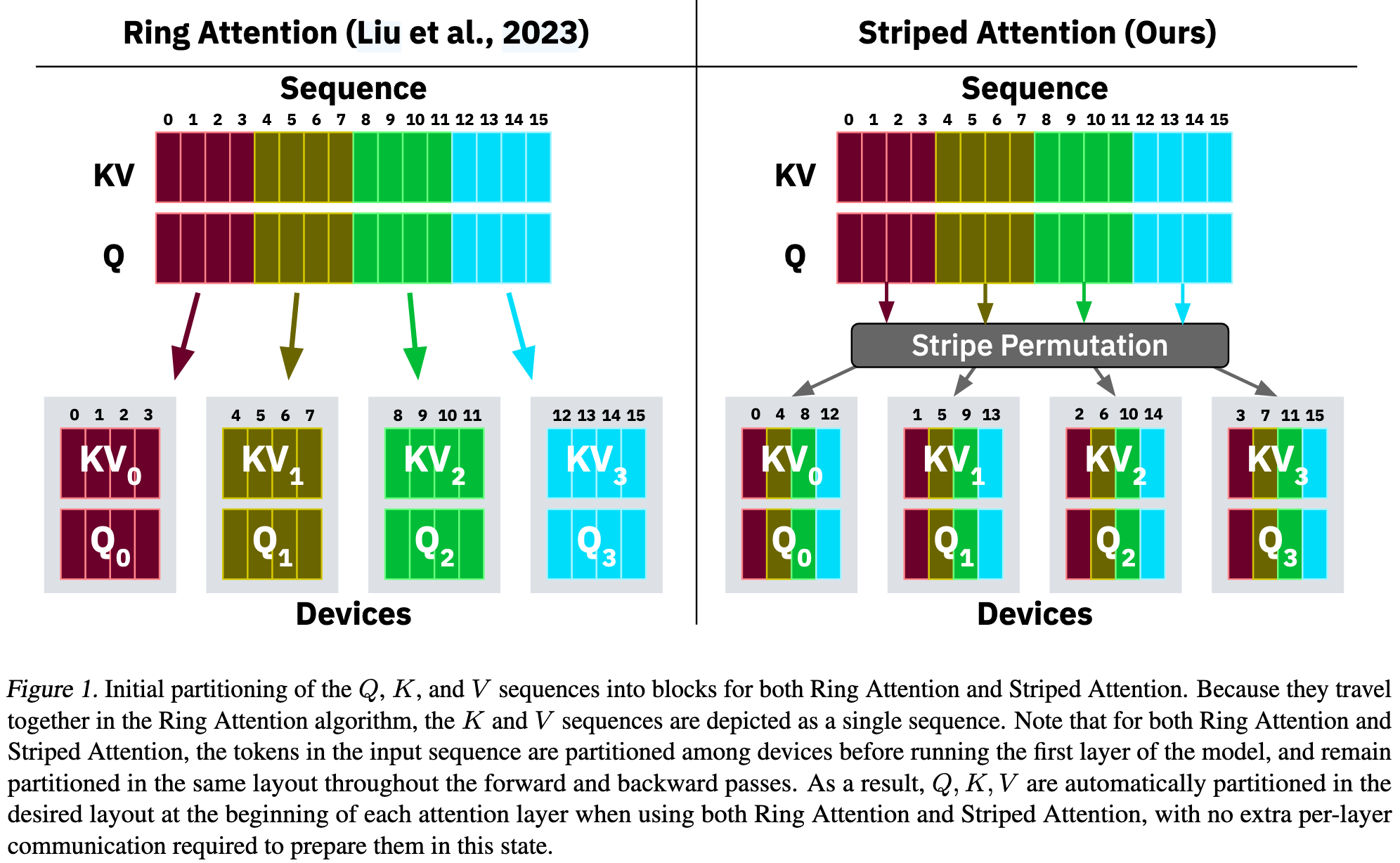
Ring Attention 的做法 (连续分块)
Ring Attention 会把序列连续地切成 3 块:
- 设备 0 获得:
[T_0, T_1, T_2, T_3](序列的前 1/3 - 设备 1 获得:
[T_4, T_5, T_6, T_7](序列的中间 1/3) - 设备 2 获得:
[T_8, T_9, T_10, T_11](序列的后 1/3)
这就是论文中提到的“工作负载不平衡”的根源。比如在计算的某一轮,当设备 0 需要用它的查询 Q_0 (来自 T_0 到 T_3) 去和设备 2 的键 K_2 (来自 T_8 到 T_11) 交互时,由于 T_8 到 T_11 全都在 T_0 到 T_3 的“未来”,根据因果关系,所有的计算都会被完全屏蔽 (masked),设备 0 就在空转。
Striped Attention 的做法 (条带式划分)
Striped Attention 不再连续切分,而是像发扑克牌一样,轮流地、交错地把词元分给 3 个设备。
划分的规则是:词元的索引 (index) 除以设备数 (3) 的余数,决定了它去哪个设备。
设备 0 获得余数为 0 的词元:
T_0(因为 0 % 3 = 0)T_3(因为 3 % 3 = 0)T_6(因为 6 % 3 = 0)T_9(因为 9 % 3 = 0)- 所以,设备 0 的数据块是:
[T_0, T_3, T_6, T_9]
设备 1 获得余数为 1 的词元:
T_1(因为 1 % 3 = 1)T_4(因为 4 % 3 = 1)T_7(因为 7 % 3 = 1)T_10(因为 10 % 3 = 1)- 所以,设备 1 的数据块是:
[T_1, T_4, T_7, T_10]
设备 2 获得余数为 2 的词元:
T_2(因为 2 % 3 = 2)T_5(因为 5 % 3 = 2)T_8(因为 8 % 3 = 2)T_11(因为 11 % 3 = 2)- 所以,设备 2 的数据块是:
[T_2, T_5, T_8, T_11]
| 方法 | 设备 0 | 设备 1 | 设备 2 |
|---|---|---|---|
| Ring Attention | T_0, T_1, T_2, T_3 | T_4, T_5, T_6, T_7 | T_8, T_9, T_10, T_11 |
| Striped Attention | T_0, T_3, T_6, T_9 | T_1, T_4, T_7, T_10 | T_2, T_5, T_8, T_11 |
3. 为什么这样做能解决问题?
现在我们再来看之前那个让 Ring Attention 空转的场景:设备 0 的查询 Q_0 和设备 2 的键 K_2 进行交互。
- 设备 0 的查询
Q_0来自:[T_0, T_3, T_6, T_9] - 设备 2 的键
K_2来自:[T_2, T_5, T_8, T_11]
让我们看看它们之间的交互:
- 当
Q_0中的查询T_3要和K_2中的所有键交互时:- 它可以关注
T_2(因为 2 < 3)。这是有效计算。 - 它不能关注
T_5,T_8,T_11(因为它们都在 3 之后)。这是被屏蔽的计算。
- 它可以关注
- 当
Q_0中的查询T_6要和K_2中的所有键交互时:- 它可以关注
T_2,T_5。这是有效计算。 - 它不能关注
T_8,T_11。这是被屏蔽的计算。
- 它可以关注
在这种条带式划分下,任何两个设备的数据块之间,都既存在因果关系允许的交互,也存在被屏蔽的交互。这意味着,在计算的每一轮中,每一个设备的工作负载都近似是“一半有效,一半被屏蔽”。没有任何一个设备会像在 Ring Attention 中那样出现计算任务被完全屏蔽的极端情况。
最后用论文里的例子说明一下:

- 在 Round 2 中
- Ring Attention 已经有两个设备处于 idle 了
- Striped Attention 仍然让所有设备保持工作,每个设备需要执行的计算量下降了,因此就更快了
Evaluation
Thoughts
When Reading
有没有一种更好的图结构来支持 Ring Attention?
整个问题建模还是比较简单的。
所以 attention 部分权重的加载能不能做到 attention-aware 之类的?