Extensive Reading
Author Info
Background
Current LLM inference schedulers can be broadly classified into two categories:
- Prefill-Prioritizing
- Throughput first: allows subsequent decodes to operate at high batch sizes
- Compromise on latency: prefill can take arbitrarily long time depending on the lengths of the given prompts
- Decode-Prioritizing
- Latency first - new requests do not affect the execution of ongoing requests in their decode phase
- Compromise on throughput: even if some requests in a batch finish early, the execution continues with reduced batch size until the completion of the last request
Analysis
论文指出, matrix multiplication 的执行时间可以看做 $T=max(T_{math}, T_{mem})$
- 如果一个操作的 $T_{mem} > T_{math}$, 则认为是 memory-bound, Memory-bound operations have low Model FLOPs Utilization (MFU) => 对计算资源利用不充分
- 如果一个操作的 $T_{math} > T_{mem}$, 则认为是 compute-bound, compute-bound operations have low Model Bandwidth Utilization (MBU) => 对带宽利用不充分
- Arithmetic intensity quantifies the number of math operations performed per byte of data fetched from the memory. At the optimal point, the arithmetic intensity of operation matches the FLOPS-to-Bandwidth ratio of the device.
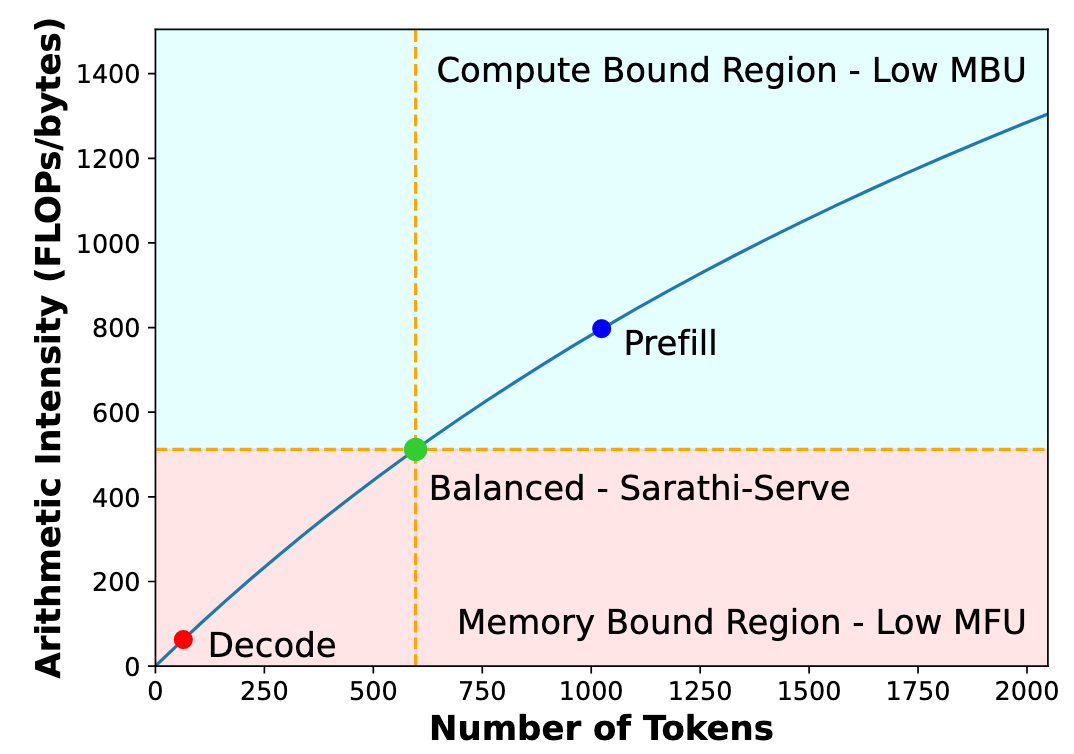
Decode batches have low arithmetic intensity i.e., they are bottlenecked by memory fetch time, leading to low compute utilization. Prefill batches are compute bound with sub-optimal bandwidth utilization.
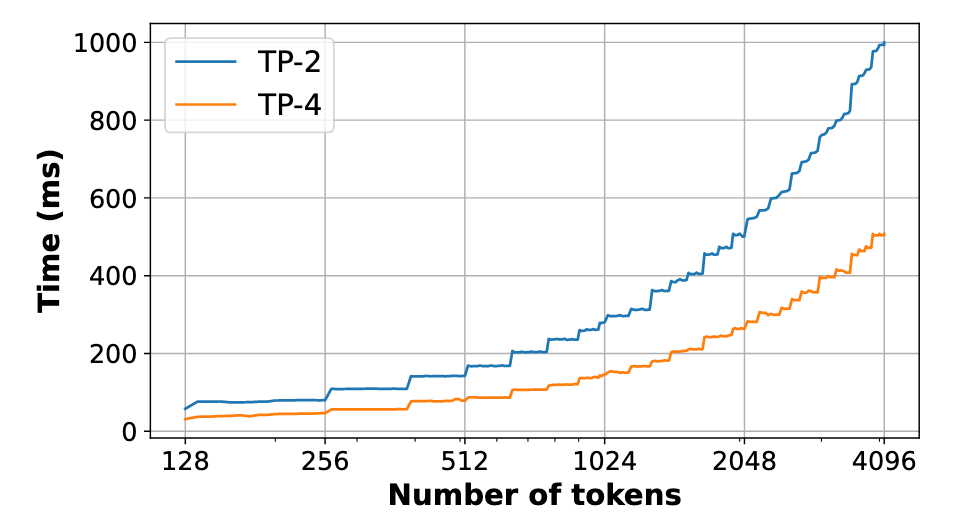
Once the number of tokens in the batch cross a critical threshold, the operation become compute bound and the runtime increases linearly with number of tokens.
Insights
Decode phase of LLM inference is memory-bound and suffers from extremely low GPU compute utilization, creating arithmetic intensity slack.
Rather than stalling the Decode process, Sarathi-Serve exploits idle compute cycles within Decode batches. It chunks Prefill tasks into smaller units and fuses them into in-flight Decode batches. This enables the concurrent processing of Prefill and Decode tasks in the same iteration, creating “stall-free” mixed batches to boost throughput while preserving latency.
Approaches
Sarathi-Serve 提出了两项技术
- Chunked-prefills
- stall-free batching
Chunked-prefills
Decoding 阶段是 memory-bound,算术强度很低,可以往其中加入 Prefill 来让其到达 $T_{math} = T_{mem}$ 的平衡点,也就是把一个 prefill 请求分为多个 chunk,每次往 decoding batch 中添加一个或多个 chunk of prefill
Stall-free batching
整个调度算法也比较直观,在每个调度循环中,算法会构建一个“混合批次”,构建过程的优先级如下
- 打包所有正在进行的 Decode 请求
- 打包正在进行的 Prefill chunk
- 接纳新的 Prefill 请求
整个构建过程中会维护一个 token budget,混合批次的 token 数量不能超过这个预算,并且要接近这个预算
通过限制预算:
- 满足 TBT SLO 实现 stall-free
- 最小化 PP 中的气泡
确定这个预算可以通过一次性的性能分析,找到那个在不违反 TBT 延迟目标前提下的最大令牌数
令牌预算是一个由 SLO(服务等级目标)决定的“硬上限”,而系统会在这个“上限”内,尽可能地去接近 T_math = T_mem 这个“硬件效率最优平衡点”