Extensive Reading
Author Info
Background
Insights
论文的出发点基于对 LLM 推理过程的两个关键观察:
Prompt 编码是并行的:输入提示词(Prompt)的处理可以高度并行化,因此即使是大模型,这部分的计算效率也相对较高。
自回归解码是串行的:生成响应(Response)必须逐个 Token 进行,受限于显存带宽(Memory Wall),大模型在此阶段非常缓慢且昂贵。
Idea 是将这两部分任务解耦。使用一个冻结的 LLM 来处理 Prompt,提取高质量的深层语义表征(“Think Big”);然后将这些表征传递给一个小模型(SLM),由 SLM 负责后续的自回归解码生成(“Generate Quick”)
Approaches
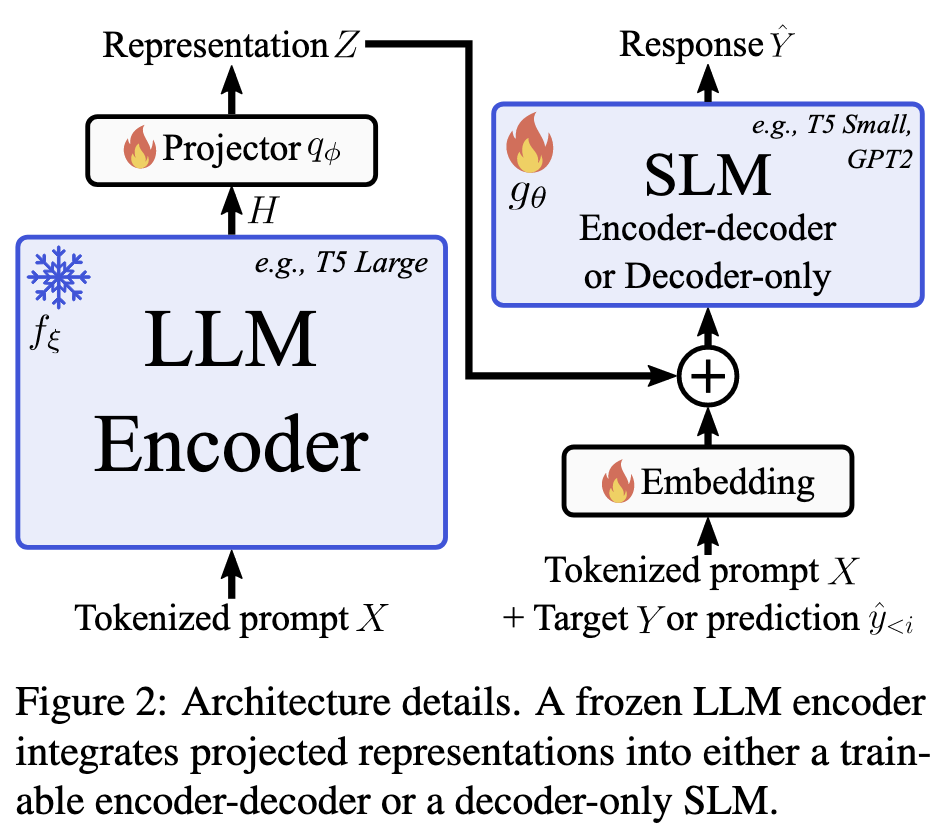
架构包含三个主要组件:
- LLM Encoder ($f_{\xi}$):作用:负责对输入 Prompt 进行编码,提取高维、高质量的表征 $H$。状态:在训练和推理期间保持冻结(Frozen),不需要更新参数,节省训练资源。选择:通常使用 Encoder-Decoder 架构(如 T5)的 Encoder 部分。如果是 Decoder-only 模型(如 GPT),则提取中间层的特征(但论文发现 Encoder-Decoder 的效果更好)。
- 投影器 (Projector, $q_{\phi}$):作用:解决 LLM 和 SLM 维度不匹配的问题。结构:一个简单的轻量级 MLP(Linear $\to$ ReLU $\to$ Linear)。流程:将 LLM 的高维特征 $H$ 映射到 SLM 的嵌入空间维度,得到 $Z$。
- SLM ($g_{\theta}$):作用:接收投影后的特征和原始 Prompt,进行自回归生成。状态:全量微调(或微调部分参数),使其学会利用 LLM 提供的强语义特征。选择:可以是 Encoder-Decoder 或 Decoder-only 架构(如 GPT-2, T5 Small)。
如何将 LLM 的“思考”注入到 SLM 中是关键。
论文对比了替换(Replacement)和相加(Addition),最终推荐相加策略
操作:将投影后的 LLM 表征 $Z$ 直接逐元素相加到 SLM 的 Prompt Embedding ($E_X$) 上。
公式:输入给 SLM 的最终 Embedding = $E_X + Z$。优势:保留了 SLM 自身的 Embedding 语义,同时利用 LLM 的特征进行增强。对齐问题:如果 LLM 和 SLM 使用不同的 Tokenizer,导致序列长度不一致,论文建议在 SLM 输入端复用 LLM 的 Tokenizer 和 Embedding Matrix,通过线性层适配维度,从而保证序列长度对齐。
Evaluation
Thoughts
When Reading
这个工作的 LLM 和 SLM 模型架构限制比较大,LLM 最好是 Encoder-Decoder 架构,所以参考价值不大
核心原因在于表征目标的差异:
- Encoder-Decoder (如 T5) 的 Encoder:
- 它的 Encoder 是双向注意力(Bidirectional Attention)。
- 它的训练目标就是“理解并压缩”整个 Prompt,生成一个高度浓缩的、全局的语义表征 $H$。这个表征天然适合作为上下文(Context)喂给另一个模型。
- Decoder-only (如 Llama/GPT) 的层:
- 它是单向因果注意力(Causal Attention)。它的每一层都在为“预测下一个 Token”做准备。中间层的 Hidden States 包含了大量关于“下一个词可能是什么”的低级预测信息,而不是对“Prompt 整体语义是什么”的高级概括。
- 论文提到,Decoder-only 模型的最后一层表征主要是为了低级别的 Next-token prediction 服务的,直接拿来做 Prompt 编码并不高效。