Analyze
Key Features
- Processing and generating large data sets.
- Exploits a restricted programming model to parallelize the user program automatically and to provide transparent fault-tolerance.
Details
By distributing the workload to many machines and let them execute the tasks in parallel.
Specifically, input files are split into $M$ pieces and master assign each one to an idle worker. Worker process it with the map function and save each key/value pair to one of the $R$ files according to the partioning function. When finishing processing all $M$ pieces, $R$ reduce workers will read data from the corresponding intermediate files, process it with the reduce function and save to output file eventually.
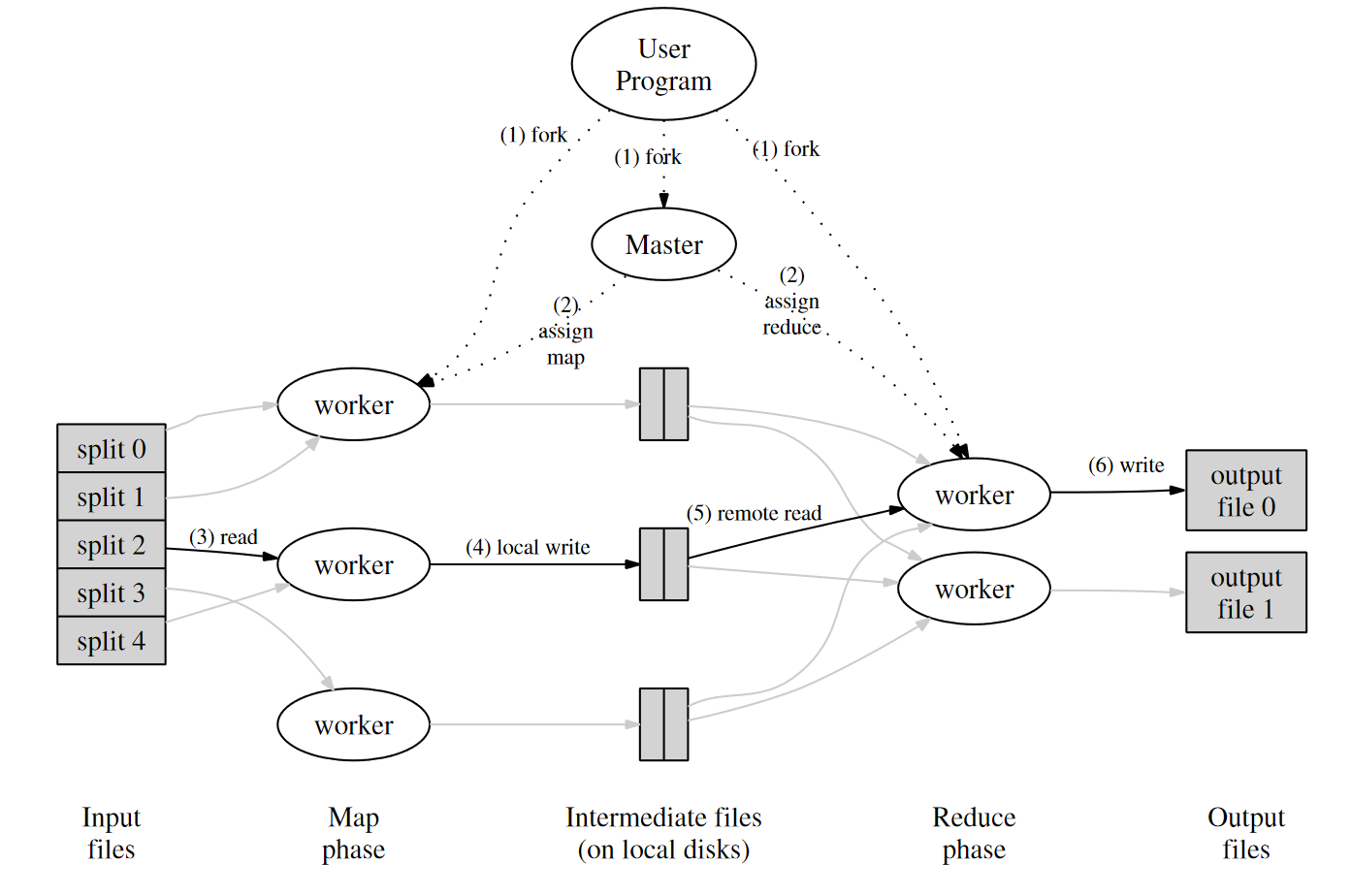
Limit
Task has to fit in the form of map and reduce.
Reliability
It can tolerant both worker and master failures.
How
The master will send heartbeat to the workers, a worker will be marked as failed when there is no response received by the master in a certain amount of time, and its task will be rescheduled.
MapReduce is resilient to large-scale worker failures, if there are workers alive, the progress can be prompted.
However, if master fails, Google’s choice is to abort the MapReduce computation. To achieve reliability, we can store the state on ZooKeeper or etcd, or just write periodic checkpoints to local disk.
When the master has seen more than one failure on a particular record, it indicates that the record should be skipped when it issues the next re-execution of the corresponding Map or Reduce task.
Performance
High
Several Tricks
Backup Tasks
When a MapReduce operation is close to completion, the master schedules backup executions of the remaining in-progress tasks.
Locality
Network bandwidth is a relatively scarce resource. When running large MapReduce operations on a significant fraction of the workers in a cluster, most input data is read locally and consumes no network bandwidth.
Scalability
High.
More machines, better performance.