FAQ
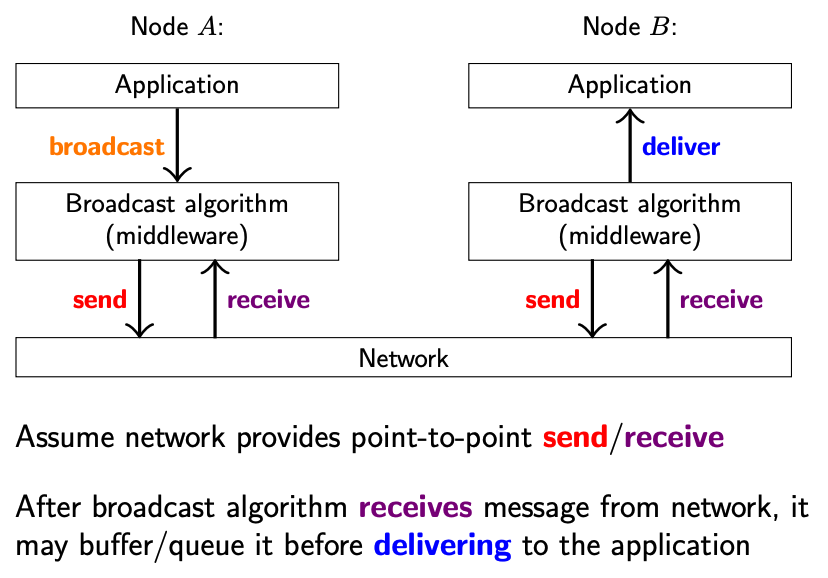
What is the difference between receive and deliver?
What does it mean by saying “Zab’s transaction log doubles as the database write-ahead transaction log” in page 3?
ZooKeeper uses an in-memory database and stores transaction logs (Write-ahead log) and periodic snapshots on disk.
Before a transaction is executed and its changes are applied to the in-memory database, it is first logged. This means that if the system crashes before the changes can be applied, the transaction can be replayed from the log to ensure data integrity.
Because of the need of recovering failures in Zab, Zab also need to store transaction logs.
Because the transaction log is used both for replicating data across the ZooKeeper ensemble (via Zab) and as the write-ahead transaction log, each transaction is written to disk only once. It’s not logged separately for replication and for the purpose of the in-memory database durability. The same log is used for both, which optimizes disk operations.
Analyze
Requirements
ZooKeeper 对于下层的广播协议做了如下要求:
- Reliable delivery
- If a message, $m$, is delivered by one server, then it will be eventually delivered by all correct servers.
- Total order
- If message $a$ is delivered before message $b$ by one server, then every server that delivers $a$ and $b$ delivers $a$ before $b$.
- Causal order
- If message $a$ causally precedes message $b$ and both messages are delivered, then $a$ must be ordered before $b$.
- Prefix property
- If $m$ is the last message delivered for a leader $L$, any message proposed before $m$ by $L$ must also be delivered.
With these three guarantees we can maintain correct replicas of the ZooKeeper database:
- The reliability and total order guarantees ensure that all of the replicas have a consistent state;
- Replicate State Machine 的思想,初始状态一致,操作一致,那么最后的状态肯定也是一致的。
- The causal order ensures that the replicas have state correct from the perspective of the application using Zab;
- Total order 只能保证所有副本的状态是一致的,由于不一定包含 causal order,对于上层应用来说,消息的递送可能是“乱序”的,即最基本的因果关系都没有遵循。
- The leader proposes updates to the database based on requests received.
It is important to observe that there are two types of causal relationships taken into account by Zab:
- If two messages, $a$ and $b$, are sent by the same server and $a$ is proposed before $b$, we say that $a$ causally precedes $b$;
- 同一个进程内部的 “Happened Before” 关系。
- Zab assumes a single leader server at a time that can commit proposals. If a leader changes, any previously proposed messages causally precede messages proposed by the new leader.
- 如果 Leader 发生改变,前任 Leader 可能还有刚接受但未 broadcast 的事件,如果该进程之后重新获得 Leadership,这样的事件不应该被提交。
We do not assume synchronized clocks, but we do assume that servers perceive time pass at approximately the same rate. (We use timeouts to detect failures.)
Protocol
Zab’s protocol consists of two modes: recovery and broadcast.
Broadcast
广播的过程整体比较像 2PC, 但是由于没有 abort 这个选项,所以 Zab 可以在收到大多数节点的 ack 后就进行提交,而不需要等待所有节点进行响应。

消息广播的具体细节:
- Leader 服务器接收到请求后在进行广播事务 Proposal 之前会为这个事务分配一个 ZXID,再进行广播。
- Leader 服务器会为每个 Follower 服务器都各自分配一个单独的队列,然后将需要广播的事务 Proposal 依次放入这些队列中去,并根据 FIFO 策略进行消息的发送。
- 其实就是一个 TCP 会话。
- 每个 Follower 服务器在接收到后都会将其以事务日志的形式写入到本地磁盘中,并且在成功写入后返回 Leader 服务器一个 ACK 响应。
- 当有超过半数的服务器 ACK 响应后,Leader 就会广播一个 Commit 消息给所有的 Follower 服务器,Follower 接收到后就完成对事务的提交操作。
Recovery
To enable such a protocol to work despite failures of the leader there are two specific guarantees we need to make: we must never forget delivered messages and we need to let go of messages that are skipped.
A message that gets delivered on one machine must be delivered on all even if that machine fails.
This situation can easily occur if the leader commits a message and then fails before the COMMIT reaches any other server.
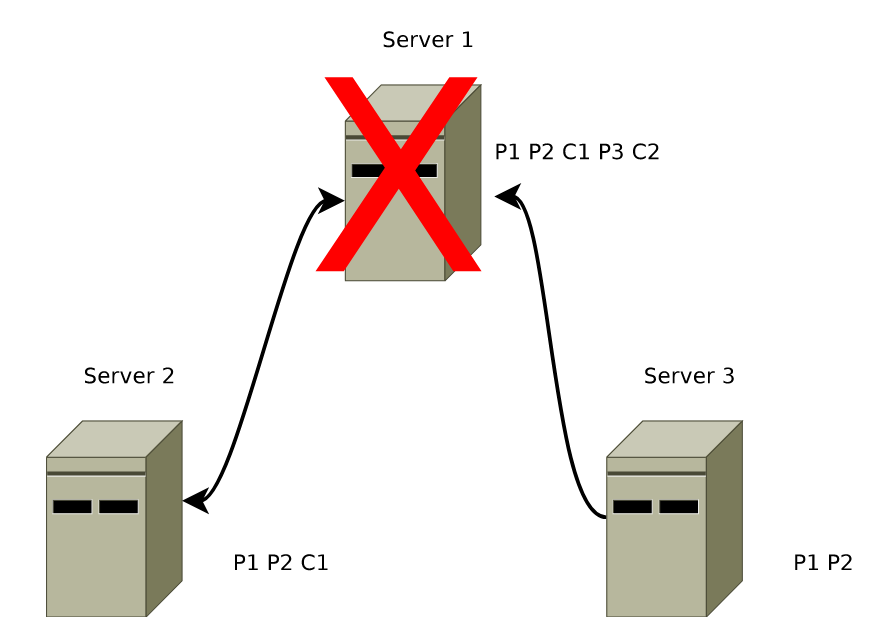
Because the leader committed the message, a client could have seen the result of the transaction in the message, so the transaction must be delivered to all other servers eventually so that the client sees a consistent view of the service.
A skipped message must remain skipped.
This situation can easily occur if a proposal gets generated by a leader and the leader fails before anyone else sees the proposal.
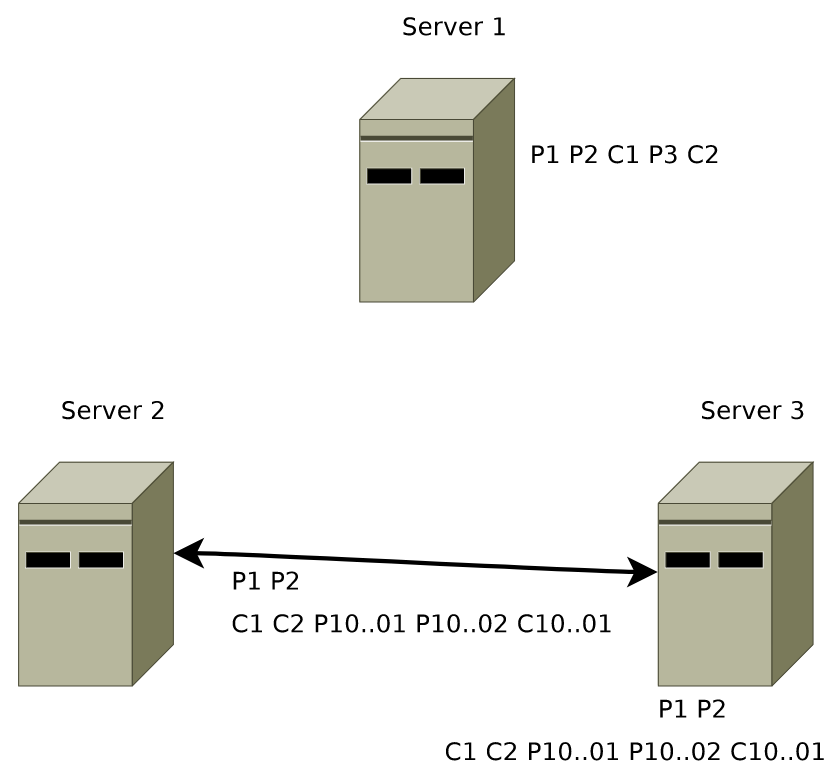
针对以上两个条件,Zab 在选 Leader 时只需要选出拥有最大 ZXID 的进程就行:
If the leader election protocol guarantees that the new leader has the highest proposal number in a quorum of servers, a newly elected leader will also have all committed messages.
Before proposing any new messages a newly elected leader first makes sure that all messages that are in its transaction log have been proposed to and committed by a quorum of followers.
奔溃恢复模式下 Leader 选举的过程细节如下:
- 检测节点处于 LOOKING 阶段,开发选举 Leader
- 发起投票时有两种情况:
- 在服务启动的初始阶段,每个服务器都会投票给自己以(myid,zxid)的信息形式发送,那初始阶段没有 zxid 值,就会发送(myid,0)
- 在服务器运行期间,每个服务器上的 zxid 都有值,且 zxid 都不相同,所以就正常发送(myid,zxid)
- 各节点收到信息后将收到的(myid,zxid)和自己的比较,比较的过程前面已经说过,这里不再赘述
- 然后判断是否有半数的机器投票选出 Leader,如果否,在进入新一轮投票,直到选出
- 选出 Leader 后,其他节点就变成 Follower 角色,并向 Leader 发送自己服务器的最大 zxid ,Leader 服务器收到后会和自己本地的提议缓存队列进行比较,使用对应的策略进行同步。
- 当同步完成,集群就可以正常的处理请求了,就进入消息广播模式了。
Examples
假设一开始 x 为 30,客户端发送请求:x+1
有几种情况:
- Leader 自己确认了这个(31),而 follower 都没有收到 commit(30),leader 重启后两者不一致
- Leader 自己确认了这个(31),而 follower 都没有收到 commit(30),重新选举后会如何
- Leader 自己确认了这个(31),而部分 follower 没有(30),但部分收到了,重新选举后会如何
在上述情况中,读请求可能拿到不一样的数据,但由于写操作被限制了所以他能保证最终一致性。
我们把 Leader 的工作编号一下:
- 发送 x=31 给所有 follower。
- 确认大多数 follower 已经复制了这个操作。
- 向所有 follower 发送 commit。
这个过程的唯一变数其实出在第二步,所有的 Leader 启动时会加载本地日志,对他来说历史操作只有两种情况:
- 已提交
- 对于已提交的操作自然是无需理会。
- 未提交
- 对于未提交的操作 Leader 会重新确认一下是不是大多数 follower 都复制好了。
所以现在我们来看看,如果 Leader 重启了(或者是新当选了),他会回放本地未提交的日志(比如上述的30+1,只要有节点收到了该操作,zxid 更大的会当选):
- 如果发现此操作是已经被大多数 follower 复制了:他会把 commit 结果直接发给大家。
- 如果发现此操作还没被大多数 follower 复制:他会先广播到大多数都复制了再 commit。
可以总结一下:
- 如果 Leader 广播了一个操作并且成功被任意 Follower 收到,那么这个操作一定会被提交。
- 被大多数 Follower 收到,直接 commit。
- 没有被大多数 Follower 收到,但新的 Leader 一定会有这条记录,所以会先广播再 commit。
- 如果 Leader 只是收到了一个操作,还未来得及广播,就挂掉了,无论是否重连,这个操作都会被忽略。