在和 GGML 打交道时不知道已经写了几篇文档了,这篇一定是最后一个
这篇文档主要记录我用 GGML 实现一个简单的 LLM Inference Engine 时遇到的问题
C++
Initialization
在 C++ 中, class 中的成员在构造函数体开始之前就被默认构造了,要控制其行为,需要使用初始化列表
class Member {
public:
Member() {
std::cout << "Member 默认构造\n";
}
Member(int x) {
std::cout << "Member 带参构造: " << x << "\n";
}
};
class MyClass {
Member m1; // 成员对象
Member m2;
int value;
public:
// 情况1: 不使用初始化列表
MyClass() {
std::cout << "构造函数体开始\n";
value = 10; // 这是赋值,不是初始化!
}
// 情况2: 使用初始化列表
MyClass(int v) : m1(1), m2(2), value(v) {
std::cout << "构造函数体开始\n";
}
};
情况 1 输出
Member 默认构造 // m1 在构造函数体前被默认构造
Member 默认构造 // m2 在构造函数体前被默认构造
构造函数体开始
情况 2 输出
Member 带参构造: 1 // m1 在构造函数体前初始化
Member 带参构造: 2 // m2 在构造函数体前初始化
构造函数体开始
对于指针来说,初始化就是将其设置为 nullptr, 对于 STL 容器,就是初始化空容器
所以我们可以在 constructor 中使用 new 在堆上创建对象,返回一个指针
// 方式1:栈上分配
MyClass obj; // 直接得到实例(对象本身)
MyClass obj2(10); // 带参数构造
// 方式2:堆上分配
MyClass* ptr = new MyClass(); // 得到指针
MyClass* ptr2 = new MyClass(10); // 带参数构造
- 在 class 中,默认一切都是 private
- 在 struct 中,默认一切都是 public
Reference
引用绑定的是变量本身(变量在内存中的那个存储实体)
如果引用一个指针:
- 可以修改指针指向
- 修改后引用会跟着变
引用相当于是变量别名
比如在 ggml 的 example 中有这么一段:
auto &ctx = this->ctx_w;
// 此时 this->ctx_w 还没有被初始化,可以认为是 NULL
{
ggml_init_params params = {
/*.mem_size =*/ctx_size,
/*.mem_buffer =*/NULL,
/*.no_alloc =*/false,
};
this->ctx_w = ggml_init(params);
}
{
// 此时 this->ctx_w 已经被初始化了,所以引用它的 ctx 也有效
this->ln_f_g = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
this->ln_f_b = ggml_new_tensor_1d(ctx, GGML_TYPE_F32, n_embd);
}
Pointer
区别指针的值和指针本身的地址
struct ggml_context * ctx = NULL; // ctx 是一个指针,它的值是 NULL
struct gguf_init_params params = {
/*.no_alloc = */ true,
/*.ctx = */ &ctx, // ⭐ 这里传递的是 ctx 的地址,不是 ctx 的值!
};
------
// 1. ctx 是一个指针变量
struct ggml_context * ctx = NULL;
// 内存布局:
// 地址: 0x7fff1234 (假设 ctx 变量存储在这个地址)
// 值: NULL (0x0)
// 2. &ctx 是"指向指针的指针"
struct ggml_context ** ptr_to_ctx = &ctx;
// &ctx 的值是 0x7fff1234 (ctx 变量的地址)
// 这个地址本身不是 NULL!
头文件
头文件(.h)应该包含:
- 类/结构体的声明
- 函数声明
- inline函数的完整定义
- 模板的完整定义
- 常量声明
- 类型别名(typedef/using)
实现文件(.cpp)应该包含:
- 函数的具体实现
- 类成员函数的实现
- 静态变量的定义
cpp文件不会随着include头文件而被引入
// main.cpp
#include "person.h" // Only includes declarations from person.h
// Does NOT automatically include person.cpp
int main() {
Person p("Alice", 25); // Linker will find implementation in person.cpp
p.introduce();
return 0;
}
对于 CMake 的影响
| 文件类型 | 需要在 CMakeLists.txt 中添加? |
|---|---|
| 纯头文件 (.h only) | ❌ 不需要 |
| 头文件 + 实现文件 (.h + .cpp) | ✅ 只需添加 .cpp |
| 只有实现文件 (.cpp) | ✅ 需要添加 |
GGML
Cheatsheet
model.a = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_A, rows_A);
model.b = ggml_new_tensor_2d(ctx, GGML_TYPE_F32, cols_B, rows_B);
struct ggml_tensor * ggml_new_tensor_2d(
struct ggml_context * ctx,
enum ggml_type type,
int64_t ne0,
int64_t ne1) {
const int64_t ne[2] = { ne0, ne1 };
return ggml_new_tensor(ctx, type, 2, ne);
}
// ne0 -> col
// ne1 -> row
// nb0 -> 在 ne0 维度中,移动到相邻的元素(a[row][0] -> a[row][1]),需要在内存中前进多少字节
// nb1 -> 在 ne1 维度中,移动到相邻的元素(a[0][col] -> a[1][col]),需要在内存中前进多少字节
ggml_tensor * c = ggml_mul_mat(ctx, a, b)
=> c = b @ a^T
关键代码位置:
ggml_backend_cpu_buffer_type-ggml-backend.cpp:2172
内存布局
“内存连续"的核心含义:
- 数据在内存中按行优先顺序紧密排列,没有间隙
nb[i](stride) 必须等于前面所有维度的乘积,即:nb[i] = nb[i-1] * ne[i-1]
举个例子:
// 张量:[3, 2] 矩阵
// ne = {3, 2}
// nb = {4, 12} // 4 = sizeof(float), 12 = 4*3
//
// 内存布局:
// [a0, a1, a2, b0, b1, b2]
// ↑________↑ ↑________↑
// row 0 row 1
//
// nb[0] = 4 (每个元素 4 字节)
// nb[1] = 12 (跳过 3 个元素 = 12 字节才到下一行)
ggml_reshape
- 要求输入连续
- 输出也是连续的
- 共享相同的数据指针
- 只改变 shape 和 stride,不改变内存布局,不改变内存中元素的顺序
比如一个
[2, 2]的矩阵 reshape 为[1, 4], 内存连续性没有改变,可以直接放入矩阵乘法中,内部的缓存一致性也没有破坏,矩阵乘法时一直都是线性访问底层的内存
[2, 2]的布局:[a0(R0C0), a1(R0C1), a2(R1C0), a3(R1C1)][1, 4]的布局:[a0(R0C0), a1(R0C1), a2(R0C2), a3(R0C3)]
ggml_view
struct ggml_tensor * ggml_view_2d(
struct ggml_context * ctx,
struct ggml_tensor * a,
int64_t ne0,
int64_t ne1,
size_t nb1, // ← 第二维的 stride
size_t offset) { // ← 起始偏移
const int64_t ne[2] = { ne0, ne1 };
struct ggml_tensor * result = ggml_view_impl(ctx, a, 2, ne, offset);
// 手动设置 stride
result->nb[1] = nb1;
result->nb[2] = result->nb[1]*ne1;
result->nb[3] = result->nb[2];
return result;
}
- 不要求输入内存连续
- 输出通常是不连续的(ggml_view 的主要目的就是为了创建非连续的张量视图而无需复制数据)
- 共享数据指针
- 不修改内存
- view 只是改变如何"解释"和"访问"现有内存
- 原始数据保持不变
- 只创建新的元数据(shape, stride, offset)
当你想对一个大张量的一部分进行操作,而不想支付昂贵的内存复制成本时。ggml_view 本质上是创建了一个“指针”或“引用”。
最经典的例子就是 LLM (大语言模型) 中的 KV Cache。
假设你有一个 KV Cache 张量,形状为 (batch_size, num_heads, seq_len, head_dim)。
写入新 Token (写操作):
- 你刚计算出当前第
t个 token 的 Key 和 Value (K/V)。 - 你需要把这个 K/V 写入 到 KV Cache 的第
t个位置。 - 你不需要复制整个 cache。你只需要一个指向
cache[:, :, t, :]这个“切片”的视图。 ggml_view就会创建这个视图 (view)。这个视图在seq_len维度上是非连续的。- 然后你使用
ggml_cpy(copy) 操作,将新计算的 K/V 复制到这个view指向的内存位置。
- 你刚计算出当前第
执行注意力 (读操作):
- 在计算注意力时,Query (Q) 需要和所有历史的 K (
0到t) 进行计算。 - 你需要一个
cache[:, :, 0:t+1, :]的视图。 ggml_view再次创建这个视图。这个视图在seq_len维度上是连续的(从 0 开始的一个块),但它仍然是一个子集。
- 在计算注意力时,Query (Q) 需要和所有历史的 K (
其他常见例子:
- 获取词向量 (Embedding): 从一个
(vocab_size, hidden_dim)的巨大词表中,通过ggml_view_1d取出第token_id行。这一行本身是连续的,但它是一个view。 - 多头注意力 (MHA) 拆分: 将一个
(seq_len, hidden_dim)的张量,view成(seq_len, num_heads, head_dim),以便分离出不同的头。
- 对于 element-wise 这类轻量级运算,直接在非连续内存上执行
- 对于 matrix multiplication 这类计算,需要先将其转换为连续的
- 调用
ggml_mul_mat(ctx, a, b)时,ggml 内部会调用ggml_is_contiguous(a),如果 a 不是连续的,ggml 会自动在计算图中插入一个ggml_cont(ctx, a)
- 调用
ggml_cont
- 不要求输入是否连续
- 输出一定连续
- 会创建新内存
- 会修改内存布局
ggml_cont 会检查输入张量:
- 如果输入张量已经是连续的,ggml_cont 在图构建时什么也不做,直接返回原张量。
- 如果输入张量不是连续的(例如它是一个 view),ggml_cont 就会创建一个新张量,并分配新的内存,然后将非连续的数据复制到这块新内存中,使其变得连续。
- 根据
ne0, ne1, nb0, nb1等元数据访问这个 view, 复制最内层维度的连续块到新张量中
- 根据
伪代码如下:
// 目标(dst)张量的数据指针,它指向一块连续内存
char * d_data = (char *) dst->data;
// 源(src)张量的数据指针
const char * s_data = (const char *) src->data;
// 遍历所有维度 (以4D为例)
for (int i3 = 0; i3 < src->ne[3]; i3++) {
for (int i2 = 0; i2 < src->ne[2]; i2++) {
for (int i1 = 0; i1 < src->ne[1]; i1++) {
// 1. 计算非连续的源(src)地址
// 它使用 'nb' (步长) 来跳跃
const char * s_ptr = s_data + i3*src->nb[3] + i2*src->nb[2] + i1*src->nb[1];
// 2. 计算连续的目标(dst)地址
// 它只是简单地在 d_data 基础上累加
// 3. 复制最内层维度的连续块
// (src->ne[0] 个元素, 每个元素 src->nb[0] 字节)
memcpy(d_data, s_ptr, src->ne[0] * src->nb[0]);
// 4. 推进连续的目标(dst)指针
d_data += src->ne[0] * src->nb[0];
}
}
}
ggml_permute
- 不要求输入连续
- 输出不连续
- 共享数据指针
- 不修改内存布局
struct ggml_tensor * ggml_permute(
struct ggml_context * ctx,
struct ggml_tensor * a,
int axis0,
int axis1,
int axis2,
int axis3) {
// ...参数检查...
struct ggml_tensor * result = ggml_view_tensor(ctx, a); // ← 创建视图
ggml_format_name(result, "%s (permuted)", a->name);
int ne[GGML_MAX_DIMS];
int nb[GGML_MAX_DIMS];
// 重新排列 ne(形状)
ne[axis0] = a->ne[0];
ne[axis1] = a->ne[1];
ne[axis2] = a->ne[2];
ne[axis3] = a->ne[3];
// 重新排列 nb(stride)
nb[axis0] = a->nb[0];
nb[axis1] = a->nb[1];
nb[axis2] = a->nb[2];
nb[axis3] = a->nb[3];
// 更新 result 的形状和 stride
result->ne[0] = ne[0];
result->ne[1] = ne[1];
result->ne[2] = ne[2];
result->ne[3] = ne[3];
result->nb[0] = nb[0];
result->nb[1] = nb[1];
result->nb[2] = nb[2];
result->nb[3] = nb[3];
result->op = GGML_OP_PERMUTE;
result->src[0] = a;
return result;
}
例子:
内存地址: [0] [4] [8] [12]
数据: a b c d
原tensor (2, 2):
ne0 = 2 ne1 = 2
nb0 = 4 nb1 = 8
访问 a[i][j] = data[i*nb1 + j*nb0]
a[0][1] = data[4] -> b
ggml_permute(ctx, A, 1, 0, 2, 3)
ne0 = 2 ne1 = 2
nb0 = 8 nb1 = 4
访问 p[i][j] = data[i*nb1 + j*nb0]
p[0][0] = data[0] -> a
p[0][1] = data[8] -> c
p[1][0] = data[4] -> b
p[1][1] = data[12] -> d
overview
GGML 中关键组件:
- ggml_tensor: 一个多维矩阵,也是计算图中的一个节点
- ggml_cgraph:表示整个计算图
- ggml_context:维护 tensor 的元数据
- ggml_backend:代表不同的后端,负责具体的算子计算逻辑
- ggml_backend_buffer:后端分配的内存,比如 CPU 对应的就是内存,GPU 对应的就是显存
GGML 内存分配机制
在 ggml/example/gpt-2 中,给出了非常清晰的内存分配机制,从简单到复杂,依次是:
- main-ctx
- main-alloc
- main-backend
- main-shed
我们可以按照这个顺序来了解 GGML 的内存分配机制
在了解之前,需要知道一些背景知识
- GGML 的内存分配是以 tensor 为单位的
tensor 代表着一个多维矩阵:
struct ggml_tensor {
enum ggml_type type;
struct ggml_backend_buffer * buffer;
int64_t ne[GGML_MAX_DIMS]; // number of elements
size_t nb[GGML_MAX_DIMS]; // stride in bytes:
// nb[0] = ggml_type_size(type)
// nb[1] = nb[0] * (ne[0] / ggml_blck_size(type)) + padding
// nb[i] = nb[i-1] * ne[i-1]
// compute data
enum ggml_op op;
// op params - allocated as int32_t for alignment
int32_t op_params[GGML_MAX_OP_PARAMS / sizeof(int32_t)];
int32_t flags;
struct ggml_tensor * src[GGML_MAX_SRC];
// source tensor and offset for views
struct ggml_tensor * view_src;
size_t view_offs;
void * data;
char name[GGML_MAX_NAME];
void * extra; // extra things e.g. for ggml-cuda.cu
char padding[8];
};
对于单个 tensor 来说,需要区分两种数据:
- 元数据:即整个 tensor 这个结构体,大小是确定的,因为这个结构体中只包含基本数据类型和指针
- 底层数据:存放 tensor 数据内容,这部分大小不确定,而且很可能会被多个不同 tensor 共享
- GGML 需要在计算开始之前构建完整的计算图,并在计算开始之前分配所有需要的内存,实现推理时零分配
- 对于一张计算图,有两种节点:中间节点和叶子节点;叶子节点是权重,中间节点是计算产生的中间值
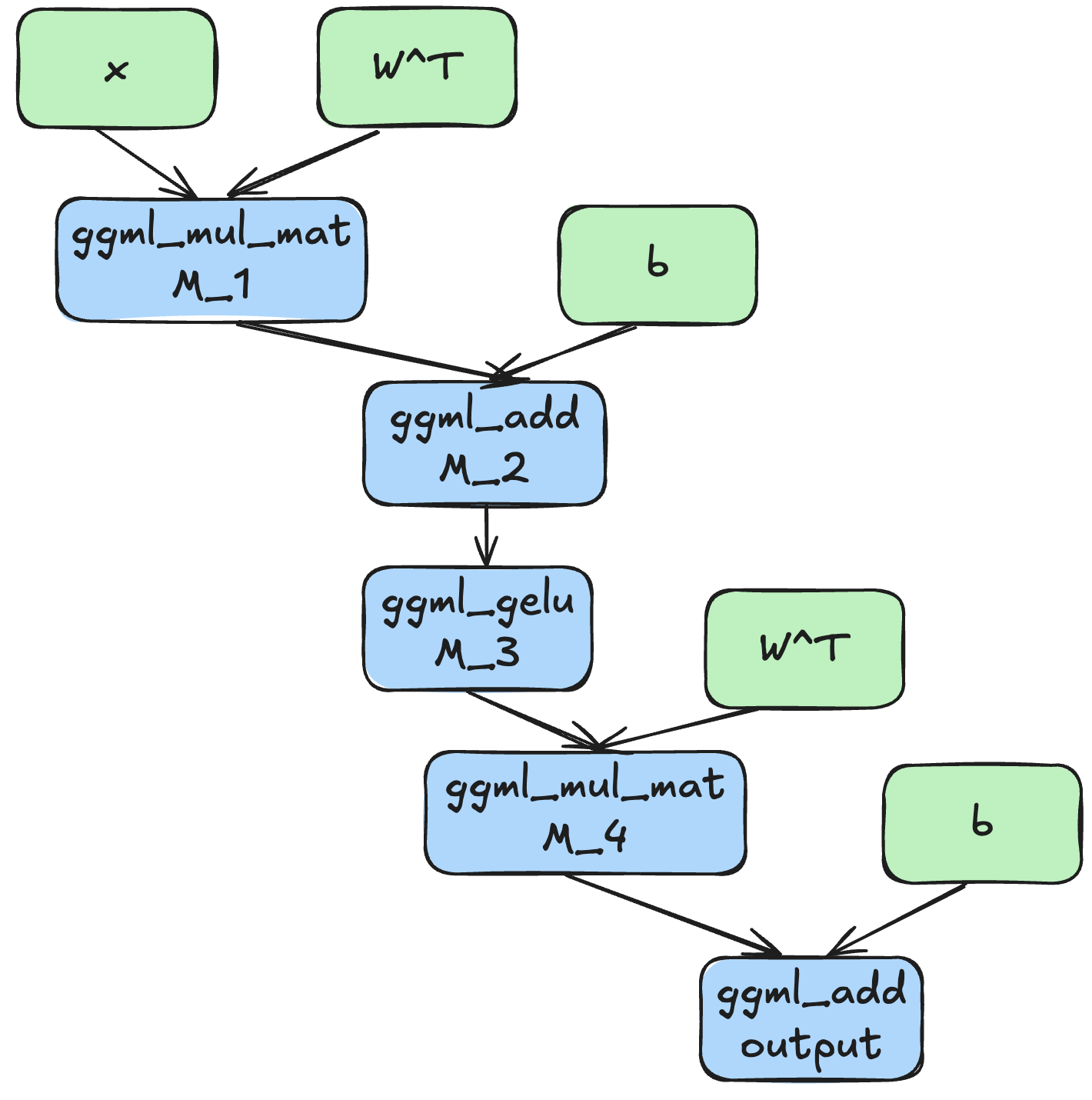
比如上图展示了一个 MLP 的计算图,绿色节点是叶子节点,叶子节点的数据需要我们在计算开始之前加载;蓝色节点是中间节点,中间节点的数据在计算过程中才会产生
在 GGML 中,计算图的表示是 ggml_cgraph:
struct ggml_cgraph {
int size; // maximum number of nodes/leafs/grads/grad_accs
int n_nodes; // number of nodes currently in use
int n_leafs; // number of leafs currently in use
struct ggml_tensor ** nodes; // tensors with data that can change if the graph is evaluated
struct ggml_tensor ** leafs; // tensors with constant data
int32_t * use_counts;// number of uses of each tensor, indexed by hash table slot
struct ggml_hash_set visited_hash_set;
enum ggml_cgraph_eval_order order;
};
tensor 的元数据始终存放在 ggml_context 中,但是其真正底层的数据 void * data 位置不确定,可能是在某个 ggml_backend_buffer 中
ggml_context 维护了一个 memory_pool,这个 memory_pool 的大小需要在初始化 ggml_context 时就确定
在下文中,我们统一称之为权重和中间值两种
在大模型推理过程中,由于是一个自回归的过程,所以相同的一张计算图会被运行很多次,其中:
- 权重:在整个模型推理过程中持续存在,只在模型加载时分配一次,在程序结束时释放
- 中间值:每次推理都会创建和销毁,用完即可释放 (有点误导,但让我们先这么理解?)
所以对于这两种 tensor 的内存管理,应该采用两种不同的机制
从机制的直观到复杂,我们可以
- 手动管理所有 tensor 的分配
- 手动管理权重 tensor,自动分配并复用中间值
- 在单后端上自动管理权重 tensor,自动分配并复用中间值
- 在多后端上自动管理权重 tensor,自动分配并复用中间值
这分别对应着:
- main-ctx
- main-alloc
- main-backend
- main-sched
main-ctx
- 手动分配权重
- 手动分配中间值
权重分配
- 手动计算所有 tensor 所需要的总空间,初始化一个对应大小的
ggml_context - 声明 tensor
- 在
ggml_context中直接分配对应的内存空间给 tensor
在 ggml 中,最简单的分配内存的方式就是通过 ggml_context 直接分配
在初始化 ggml_context 时, 我们可以将 no_alloc 参数设置为 false:
ggml_init_params params = {
/*.mem_size =*/ctx_size,
/*.mem_buffer =*/NULL,
/*.no_alloc =*/false,
};
ctx_w = ggml_init(params);
这样在运行类似于 ggml_new_tensor_2d 时,会直接在 context 的 memory_pool 中为 tensor 的底层数据分配空间:
// ggml.c: 1640
static struct ggml_tensor * ggml_new_tensor_impl(...){
size_t obj_alloc_size = 0;
if (view_src == NULL && !ctx->no_alloc) {
// allocate tensor data in the context's memory pool
obj_alloc_size = data_size;
}
struct ggml_object * const obj_new = ggml_new_object(ctx, GGML_OBJECT_TYPE_TENSOR, GGML_TENSOR_SIZE + obj_alloc_size);
*result = (struct ggml_tensor) {
// ...
/*.data =*/ obj_alloc_size > 0 ? (void *)(result + 1) : data,
/*.name =*/ { 0 },
/*.extra =*/ NULL,
/*.padding =*/ { 0 },
};
}
main-ctx 正是采用了这种方式,在加载模型时,需要手动计算模型权重需要的内存空间,然后根据大小初始化 ggml_context:
size_t ctx_size = 0;
//...
ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_g
ctx_size += ggml_row_size(GGML_TYPE_F32, n_embd); // ln_f_b
ctx_size += ggml_row_size(wtype, n_vocab * n_embd); // wte
ctx_size += ggml_row_size(GGML_TYPE_F32, n_ctx * n_embd); // wpe
ctx_size += ggml_row_size(wtype, n_vocab * n_embd); // lm_head
// ...
中间值分配
在每次开始计算之前(eval 函数内部),预估模型中间值有多大,然后也通过 ggml_context 的 memory pool 来分配空间
static size_t buf_size = 256u * 1024 * 1024;
static void *buf = malloc(buf_size);
struct ggml_init_params params = {
/*.mem_size =*/buf_size,
/*.mem_buffer =*/buf,
/*.no_alloc =*/false,
};
struct ggml_context *ctx0 = ggml_init(params);
在每次计算完成之后,释放本次计算的中间值的内存空间 ggml_free(ctx0)
main-alloc
- 手动分配权重
- 自动分配中间值
权重分配
这部分保持不变,如果我们只是考虑在 CPU 上进行推理,这部分优化的空间很少了(因为权重的生命周期非常长,从模型加载直到程序结束),再进一步优化的话,我们可以考虑有没有一种方法可以自动计算需要的空间,不用每次都让程序员在代码中执行计算?
这也非常符合直觉,既然我们需要提前声明每个 tensor 的形状和数据类型,那么这个 tensor 的大小其实已经确定了
在 main-backend 中会对这部分做进一步的优化
中间值分配
思考一下 main-ctx 中的分配方式:在每次计算开始之前分配空间,每次计算完成之后销毁
假设模型要生成 100 个 token,那么这种创建销毁的操作就会进行 100 次!
并且一开始中间值大小的估计也非常难,如果我们不去构建整个模型推理时的计算图的话,我们怎么知道到底需要多少内存,所以也只能往大了估,造成内存浪费
所以在 main-alloc 中引出了 ggml_galloc
在计算开始之前(eval 函数外部),我们先构建一次计算图,提前分配计算图中间值需要的内存空间,然后在每次 eval 是都复用这块内存
ggml_gallocr_t allocr = NULL;
// allocate the compute buffer
{
allocr = ggml_gallocr_new(ggml_backend_cpu_buffer_type());
// create the worst case graph for memory usage estimation
int n_tokens = std::min(model.hparams.n_ctx, params.n_batch);
int n_past = model.hparams.n_ctx - n_tokens;
struct ggml_cgraph * gf = gpt2_graph(model, n_past, n_tokens);
// pre-allocate the compute buffer for the worst case (optional)
ggml_gallocr_reserve(allocr, gf);
size_t mem_size = ggml_gallocr_get_buffer_size(allocr, 0);
fprintf(stderr, "%s: compute buffer size: %.2f MB\n", __func__, mem_size/1024.0/1024.0);
}
由于存在 KV Cache,所以每轮计算中,需要的内存空间是不一样的(参与注意力计算的 K 和 V tensor 会越来越大),所以我们应该估算最坏的情况:
- 序列长度等于
n_ctx - KV Cache 长度等于
n_ctx-1
然后如上面的代码块所示,这两个值并不是这么计算的,为什么?
因为 GGML 的计算图是静态的,我们希望在确定整个计算图大小后,在程序的整个生命周期内都不会变化,避免内存的再分配;如果把序列长度设置为 n-ctx,那么如果我的输入序列只有几个 token,则需要 left padding 非常多位,造成了内存的严重浪费;如果每次都根据序列长度分配,那不又回到了 main-ctx 中低效的内存分配方式了吗?
由于有 KV Cache 的存在,对于一个序列中的所有的 token 的 QKV tensor, 我们都只需要计算一次
所以我们可以人为确定一个批次(比如 32),构建计算图时以这个批次为标准,每次只允许最多 n_batch 个 token 参与运算,如果一个序列长度大于 n_batch,那么拆分这个序列,多次喂给这个计算图即可
所以这个 n_batch 既不能太大(造成内存浪费),也不能太小(虽然不会重复计算,但其中算子 kernel 启动会有开销)
所以 n_batch 指的是单次计算图能够处理的最大 token 数量,不是单次同时能够处理的输入序列
回到 main-alloc 的设计理念:在计算开始之前预分配内存,然后在每轮计算时都复用这块内存
这正好对应了两个关键函数:
- 预分配内存:
ggml_gallocr_reserve(\*ggml_gallocr_t*\ allocr, \*ggml_cgraph*\ gf) - 内存复用:
ggml_gallocr_alloc_graph(\*ggml_gallocr_t*\ allocr, \*ggml_cgraph*\ gf)
reserve() {
1. 分析图结构,确定节点分配给哪个后端
2. 计算每个后端需要的最大内存
3. 为每个后端创建 buffer(但不分配给 tensor)
Example:
GPU buffer: 2GB (预留但未使用)
CPU buffer: 512MB (预留但未使用)
}
alloc_graph(graph) {
1. 遍历当前图的所有节点
2. 从预留的 buffer 中切分内存
3. 设置每个 tensor->data 指向对应位置
Example:
tensor_Q->data = gpu_buffer + offset_0
tensor_K->data = gpu_buffer + offset_1024
...
}
两个函数都需要传入 gallocr 这个对象,是不是复用的内存也存放在 gallocr 内部呢?
struct ggml_gallocr {
ggml_backend_buffer_type_t * bufts; // [n_buffers]
struct vbuffer ** buffers; // [n_buffers]
struct ggml_dyn_tallocr ** buf_tallocs; // [n_buffers]
int n_buffers;
struct ggml_hash_set hash_set;
struct hash_node * hash_values; // [hash_set.size]
struct node_alloc * node_allocs; // [n_nodes]
int n_nodes;
struct leaf_alloc * leaf_allocs; // [n_leafs]
int n_leafs;
};
// virtual buffer with contiguous memory range, split into multiple backend buffers (chunks)
struct vbuffer {
ggml_backend_buffer_t chunks[GGML_VBUFFER_MAX_CHUNKS];
};
可以看到,确实在 ggml_gallocr 内部管理着 vbuffer
因为一张计算图中可能会涉及到多个 ggml_backend,比如一个 GPU 和一个 CPU
后续是关于这两个函数的详细解析,可以跳过
所以对于 ggml_gallocr_reserve(\*ggml_gallocr_t*\ allocr, \*ggml_cgraph*\ gf) 来说,就是遍历整个计算图,计算中间值内存的大小,并预留内存空间的过程:
bool ggml_gallocr_reserve_n(...){
// initialize ggml hash set
// allocate in hash table
// 这个函数并不会实际分配内存,相当于是 Dry Run
ggml_gallocr_alloc_graph_impl(galloc, graph, node_buffer_ids, leaf_buffer_ids){
for (int i = 0; i < graph->n_leafs; i++) {
struct ggml_tensor * leaf = graph->leafs[i];
ggml_gallocr_allocate_node(galloc, leaf, get_node_buffer_id(leaf_buffer_ids, i));
}
for (int i = 0; i < graph->n_nodes; i++) {
struct ggml_tensor * node = graph->nodes[i];
// allocate nodes
}
};
// 从 Dry Run 中提取 hash table 的信息
for (int i = 0; i < graph->n_nodes; i++) {...}
for (int i = 0; i < graph->n_leafs; i++) {...}
// 分配空间
if (realloc) {
ggml_vbuffer_free(galloc->buffers[i]);
galloc->buffers[i] = ggml_vbuffer_alloc(galloc->bufts[i], galloc->buf_tallocs[i], GGML_BACKEND_BUFFER_USAGE_COMPUTE){
for (int n = 0; n < talloc->n_chunks; n++) {
size_t chunk_size = talloc->chunks[n]->max_size;
buf->chunks[n] = ggml_backend_buft_alloc_buffer(buft, chunk_size);
if (buf->chunks[n] == NULL) {
ggml_vbuffer_free(buf);
return NULL;
}
ggml_backend_buffer_set_usage(buf->chunks[n], usage);
}
return buf;
};
}
}
整个函数逻辑比较复杂的原因是,GGML 会尝试内存复用
举一个例子:
权重 W (leaf) ──┐
├─> matmul (node) ──> add (node) ──> output
输入 X (leaf) ──┘ ↑
bias (leaf)
- 首先分配所有 leafs: W, X, bias
- 按拓扑顺序处理 nodes:
- 分配 matmul 结果
- W 和 X 的 n_children 递减
- 分配 add 结果
- matmul 的 n_children 变为 0,立即释放其内存
- bias 的 n_children 递减
内存复用效果:
- W, X, bias 保持存活(leafs)
- matmul 的内存在 add 分配时可以被复用
- 峰值内存 = leafs + max(matmul, add)
对于 ggml_gallocr_alloc_graph:
bool ggml_gallocr_alloc_graph(ggml_gallocr_t galloc, struct ggml_cgraph * graph) {
// reset buffers
for (int i = 0; i < galloc->n_buffers; i++) {
if (galloc->buffers[i] != NULL) {
ggml_vbuffer_reset(galloc->buffers[i]);
}
}
// allocate the graph tensors from the previous assignments
// leafs
for (int i = 0; i < graph->n_leafs; i++) {
struct ggml_tensor * leaf = graph->leafs[i];
struct leaf_alloc * leaf_alloc = &galloc->leaf_allocs[i];
ggml_gallocr_init_tensor(galloc, leaf, &leaf_alloc->leaf);
}
// nodes
for (int i = 0; i < graph->n_nodes; i++) {
struct ggml_tensor * node = graph->nodes[i];
struct node_alloc * node_alloc = &galloc->node_allocs[i];
for (int j = 0; j < GGML_MAX_SRC; j++) {
struct ggml_tensor * src = node->src[j];
if (src == NULL) {
continue;
}
ggml_gallocr_init_tensor(galloc, src, &node_alloc->src[j]);
}
ggml_gallocr_init_tensor(galloc, node, &node_alloc->dst);
}
return true;
}
main-backend
- 单后端
- 自动分配权重
- 自动分配中间值
在程序开始时,需要指定单个后端,比如 CUDA,METAL 或者 CPU
权重分配
因为后端不确定,所以我们不能在 ggml_context 中分配权重 tensor 的空间了(这样默认在 CPU 上),所以在初始化 ggml_context 时,用的参数是
size_t n_tensors = 2 + 6 + 12*model.hparams.n_layer;
struct ggml_init_params params = {
/*.mem_size =*/ ggml_tensor_overhead() * n_tensors,
/*.mem_buffer =*/ NULL,
/*.no_alloc =*/ true,
};
ctx = ggml_init(params);
在声明完所有 tensor 后,由下面的代码分配空间:
// allocate the model tensors in a backend buffer
model.buffer_w = ggml_backend_alloc_ctx_tensors(ctx, model.backend);
其中 ggml_backend – ggml_backend_buffer_type – ggml_backend_buffer 由对应关系
ggml_backend_buffer_type类似于工厂函数- 给定一个
tensor,负责确定这个 tensor 的实际所占大小(比如需要考虑内存对齐) - 给定
size,负责创建一块大小为size的ggml_backend_buffer
- 给定一个
ggml_backend_buffer是实际分配的内存空间
一般的流程是:
- 统计所有 tensor 需要的空间,得到
cur_buf_size - 通过
ggml_backend_buffer_type创建一个大小为cur_buf_size的ggml_backend_buffer - 新建一个
ggml_tallocr(tensor allocr),在这个ggml_backend_buffer中为每个 tensor 分配空间
在 main-backend 中,虽然只支持单后端,但是在模型加载时,还是把 weights 和 KV Cache 分开初始化,分别使用 ctx_w 和 ctx_kv 维护其元数据
其实是不需要的,但是这样更清晰,为方便过渡到
main-sched
中间值分配
和 main-alloc 相同,都是采用 ggml_galloc 在计算开始之前预分配内存,然后在每轮计算时都复用这块内存
main-sched
- 多后端
- 自动分配权重
- 自动分配中间值
在程序开始后,可以指定把模型后几层放到 GPU 上
权重分配
- 声明 tensor
- 初始化不同后端
- 确定 tensor 的分配(在哪个 backend 上)
- 对于每个 backend,统计 tensor 信息,创建 buffer 和对应的 ggml_tallocr
- 对于 KV,判断一下是 GPU 的层数多还是 CPU 的层数多,统一放在层数多的 backend 中
- 从文件中读取权重,根据权重名字,先创建对应 tensor 内存,再将数据从文件复制到对应的内存中
// allocate the tensor
ggml_backend_t backend = tensor_backends[name];
ggml_tallocr * alloc = &backend_buffers.find(backend)->second;
ggml_tallocr_alloc(alloc, tensor);
TODO: 测试一下效果
TODO:待测试
中间值分配
因为此时涉及到多个 backend,所以只使用 ggml_gallocr 已经不够了,需要引入 ggml_backend_sched, ggml_backend_sched 的作用就是在多个后端之间只能分配和执行计算图
重要的函数就是 ggml_backend_sched_reserve 和 ggml_backend_sched_alloc_graph
不管是用什么来 reserve 和 alloc_graph,其实都遵循下面这个范式:
reserve() {
1. 分析图结构,确定节点分配给哪个后端
2. 计算每个后端需要的最大内存
3. 为每个后端创建 buffer(但不分配给 tensor)
Example:
GPU buffer: 2GB (预留但未使用)
CPU buffer: 512MB (预留但未使用)
}
alloc_graph(graph) {
1. 遍历当前图的所有节点
2. 从预留的 buffer 中切分内存
3. 设置每个 tensor->data 指向对应位置
Example:
tensor_Q->data = gpu_buffer + offset_0
tensor_K->data = gpu_buffer + offset_1024
...
}
下面是比较详细的分析,可以跳过
bool ggml_backend_sched_reserve(ggml_backend_sched_t sched, struct ggml_cgraph * measure_graph) {
GGML_ASSERT(sched);
GGML_ASSERT((int)sched->hash_set.size >= measure_graph->n_nodes + measure_graph->n_leafs);
ggml_backend_sched_synchronize(sched);
ggml_backend_sched_split_graph(sched, measure_graph);
if (!ggml_gallocr_reserve_n(sched->galloc, &sched->graph, sched->node_backend_ids, sched->leaf_backend_ids)) {
return false;
}
ggml_backend_sched_reset(sched);
return true;
}
其中 ggml_backend_sched_split_graph() 可以详细分析一下:
// assigns backends to ops and splits the graph into subgraphs that can be computed on the same backend
void ggml_backend_sched_split_graph(ggml_backend_sched_t sched, struct ggml_cgraph * graph) {}
其中主要有 5 个 pass:
- Pass 1: 基于预分配张量的后端分配
核心逻辑:
如果节点的输入是权重,优先使用权重所在的后端
如果是用户输入(GGML_TENSOR_FLAG_INPUT),分配到 CPU
Pass 2: 扩展 GPU Backend
逻辑:
从已分配的 GPU 节点开始,向下/向上扩展
遇到 CPU 节点就重置(停止扩展)
Pass 3: 升级到兼容的高优先级后端
如果节点可以在更高优先级的后端上运行,且不需要额外数据传输,就升级
Pass 4: 分配剩余源张量
Pass 5: 图分割和标记需要复制的张量
将图分割成多个子图,每个子图在一个后端上运行
llama.cpp Cheatsheet
关键变量定义:
llama_model– llama-model.h:379llama_model::imp– llama-model.cpp:397
关键模型定义:
build_graph– llama-model.cpp:18146
llama.cpp
Overview
llama_model- 模型架构信息
arch,type,hparams - 权重 tensor
- 基础层
std::vector<llama_layer> layers
- 模型架构信息
llama_layer- 单个 Transformer 的权重
llama_graph_context- 调度器
- 计算图
- 计算图中间值的 ggml_context
所有模型都采用同一个 llama_model, 但不同的模型有不同的 llama_graph_context 子类
struct llm_graph_context { // ← 基类
virtual ~llm_graph_context() = default;
// 通用的构建方法
ggml_tensor * build_norm(...);
ggml_tensor * build_ffn(...);
ggml_tensor * build_attn(...);
ggml_context * ctx0;
ggml_cgraph * gf;
};
// 每个模型架构有自己的图构建器
struct llm_build_qwen3 : public llm_graph_context { // ← 子类
llm_build_qwen3(const llama_model & model, const llm_graph_params & params);
// 构造函数中构建 Qwen3 特定的计算图
};
struct llm_build_llama : public llm_graph_context { // ← 子类
llm_build_llama(const llama_model & model, const llm_graph_params & params);
// 构造函数中构建 Llama 特定的计算图
};
加载模型时没有多态
// 1. 创建统一的 llama_model 对象
llama_model * model = new llama_model(params);
// 2. 从 GGUF 读取架构类型
model->arch = LLM_ARCH_QWEN3; // 或 LLM_ARCH_LLAMA 等
// 3. 所有模型共享相同的权重存储结构
model->layers.resize(32);
model->layers[0].wq = ml.create_tensor(...); // Qwen3 用这个
model->layers[0].wk = ml.create_tensor(...); // Llama 也用这个
构建计算图时使用了多态
ggml_cgraph * llama_model::build_graph(const llm_graph_params & params) const {
std::unique_ptr<llm_graph_context> llm; // ← 多态指针
// 根据架构类型创建不同的图构建器
switch (arch) {
case LLM_ARCH_QWEN3:
llm = std::make_unique<llm_build_qwen3>(*this, params);
// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
// 构造函数中会构建 Qwen3 特定的计算图
break;
case LLM_ARCH_LLAMA:
llm = std::make_unique<llm_build_llama>(*this, params);
// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
// 构造函数中会构建 Llama 特定的计算图
break;
// ... 其他架构
}
return llm->gf; // 返回构建好的计算图
}
llama_model 还有一个 pimpl 用于隐藏设计细节:
比如权重加载时的一些数据,在模型真正推理时,你不会使用到这部分数据的
struct llama_model::impl {
impl() {}
~impl() {}
uint64_t n_elements = 0;
size_t n_bytes = 0;
std::string desc_str;
// model memory mapped files
llama_mmaps mappings;
// objects representing data potentially being locked in memory
llama_mlocks mlock_bufs;
llama_mlocks mlock_mmaps;
// contexts where the model tensors metadata is stored
std::vector<ggml_context_ptr> ctxs;
// the model memory buffers for the tensor data
std::vector<ggml_backend_buffer_ptr> bufs;
buft_list_t cpu_buft_list;
std::map<ggml_backend_dev_t, buft_list_t> gpu_buft_list;
struct layer_dev {
ggml_backend_dev_t dev;
buft_list_t * buft_list;
};
layer_dev dev_input = {};
layer_dev dev_output = {};
std::vector<layer_dev> dev_layer;
bool has_tensor_overrides;
};
Overall Workflow
How to analyze?
借鉴一下 main-sched 是如何构造的
- 模型权重定义
- 模型权重加载
- 读 Hyper Parameters
- 读 Tokenizer
- 读模型权重
- 计算图构建
- 预留计算图需要的内存
- 对输入进行 Tokenization
- 调用计算图
从内存管理入手:
- 模型权重
- 在哪里定义
- 在哪里加载
- 中间值
- 计算图在哪里定义
- 在哪里进行计算图的预留和分配
simple.cpp 流程分析
llma_context_from_model() -- simple.cpp:116
│
├─ new llama_context(): 进行 graph_reserve
│
▼
llama_decode(ctx, batch)
│
▼
llama-context.cpp:2857
ctx->decode(batch)
│
▼
llama-context.cpp:946
llama_context::decode(batch_inp)
│
├─ 准备 ubatch
│
▼
llama-context.cpp:1076
process_ubatch(ubatch, LLM_GRAPH_TYPE_DECODER, ...)
│
├─ 步骤4: 定义计算图
│ ├─ get_graph_result() // 尝试复用
│ └─ model.build_graph() // 新建图
│ └─ new llm_build_qwen3(model, params)
│ └─ 构造函数中构建计算图
│
│
├─ 步骤5: 分配空间
│ └─ ggml_backend_sched_alloc_graph -- llama-context.cpp:750
│
└─ 步骤6: 执行计算
└─ ggml_backend_sched_graph_compute_async(sched, gf)
TODO: 下面是一些零散的分析
为什么在 new llama_context 中,需要调用三次 graph reserve, 而且三次参数都不同?
而且为什么后一次 graph_reserve 的
目的是找出最坏情况下需要的内存大小,而不是真的要用这些图
No.1 Prompt Procesing Graph
auto * gf = graph_reserve(n_tokens, n_seqs, n_tokens, mctx.get());
// ^^^^^^^^ ^^^^^^ ^^^^^^^^
// 批次大小 序列数 输出数
No.2 Token Generation Graph
auto * gf = graph_reserve(n_seqs, n_seqs, n_seqs, mctx.get());
// ^^^^^^ ^^^^^^ ^^^^^^
// 每序列1个token
No.3 Worst Case?
auto * gf = graph_reserve(n_tokens, n_seqs, n_tokens, mctx.get());
ggml_bakcend_sched_reserve 中调用了 ggml_gallocr_reserve_n
ggml_gallocr_reserve_n 本身就允许多次调用,如果后一次需要的内存空间更大,就重新分配空间
内存分配
按照上面的内存分配机制来分析一下 llama.cpp
模型推理全流程(代码流):
- 声明模型权重
- 为模型权重分配空间
- 把文件中的数据复制到权重中
- 定义计算图
- 根据计算图预留空间
- 执行计算
内存分配也应该分为两类:
- 模型权重分配
- 模型计算图中间值分配
模型权重分配
TODO: 分析一下,如果所有信息都需要从 gguf 文件中读取,这个文件应该是什么样子,以及整个读取逻辑是什么,这部分不用看代码我们都知道
- 不使用 mmap
// 1. 声明模型权重(在持久 context 中)
ggml_context * ctx = ggml_init({.mem_size = size, .no_alloc = true});
ggml_tensor * wq = ml.create_tensor(ctx, "blk.0.attn_q.weight", {n_embd, n_embd});
// 2. 为权重分配 backend buffer
ggml_backend_buffer_t buf = ggml_backend_alloc_ctx_tensors_from_buft(ctx, buft);
// 这会:
// a. 计算所有 tensor 的总大小
// b. 分配一个大的 backend buffer
// c. 为每个 tensor 设置 tensor->buffer 和 tensor->data
// 3. 从文件复制数据到 buffer
for (tensor : ctx) {
file.read(tensor->data, tensor_size); // 直接写入 GPU/CPU 内存
}
使用 mmap
// 1. 声明模型权重(同样在持久 context 中)
ggml_context * ctx = ggml_init({.mem_size = size, .no_alloc = true});
ggml_tensor * wq = ml.create_tensor(ctx, "blk.0.attn_q.weight", {n_embd, n_embd});
// 2a. mmap 文件到内存
llama_mmap mapping(file, prefetch);
void * mmap_addr = mapping.addr(); // 文件内容映射到这里
// 2b. 创建 buffer_from_host_ptr(关键!)
ggml_backend_buffer_t buf = ggml_backend_dev_buffer_from_host_ptr(
dev,
(char*)mmap_addr + first_offset,
last_offset - first_offset,
max_tensor_size
);
// 这会:
// a. 创建一个 backend buffer,但它只是**包装** mmap 地址
// b. 不分配新内存!
// c. Metal/CUDA 可能会 pin 住这块内存用于 DMA
// 2c. 为每个 tensor 关联 mmap 内存
for (tensor : ctx) {
tensor->data = mmap_addr + tensor_offset; // 直接指向 mmap 内存
tensor->buffer = buf;
}
// 3. 不需要复制数据!(跳过)
// 数据已经通过 mmap 在内存中了
思考一个问题:
在不使用 mmap 时,我们可以分配一整块 buffer 空间, 然后通过在 ggml_context 中存储的顺序, 通过 ggml_tallocr 顺序分配, 但是使用 mmap 时,每个 tensor 的位置在文件中是确定的, 那么这是通过什么分配的呢?
- 非 mmap 模式:
- 分配一整块连续 buffer
- tensor 按顺序紧密排列
- 由 ggml_tallocr 顺序分配偏移量
- mmap 模式:
- tensor 位置由 GGUF 文件格式决定
- 每个 tensor 的偏移量(offset)已经固定在文件中
- 不需要重新计算偏移,直接使用文件中的布局
所以在 mmap 模式下,使用的关键函数是 ggml_backend_tensor_alloc
enum ggml_status ggml_backend_tensor_alloc(
ggml_backend_buffer_t buffer,
struct ggml_tensor * tensor,
void * addr // ← 关键:手动指定地址!
) {
GGML_ASSERT(tensor->buffer == NULL);
GGML_ASSERT(tensor->data == NULL);
GGML_ASSERT(tensor->view_src == NULL);
// 验证地址在 buffer 范围内
GGML_ASSERT(addr >= ggml_backend_buffer_get_base(buffer));
GGML_ASSERT((char *)addr + ggml_backend_buffer_get_alloc_size(buffer, tensor) <=
(char *)ggml_backend_buffer_get_base(buffer) + ggml_backend_buffer_get_size(buffer));
// 直接设置 tensor 的数据指针
tensor->buffer = buffer;
tensor->data = addr; // ← 使用传入的地址,不重新分配!
return ggml_backend_buffer_init_tensor(buffer, tensor);
}
下面是一个完整的分配流程(比较细节,可以跳过)
完整的 mmap 分配流程
Step 1: 从 GGUF 文件读取 tensor 偏移量
struct llama_tensor_weight {
uint16_t idx; // 文件索引
size_t offs; // ← tensor 在文件中的偏移量(字节)
ggml_tensor * tensor;
llama_tensor_weight(const llama_file * file, uint16_t idx,
const struct gguf_context * gguf_ctx,
ggml_tensor * tensor) : idx(idx), tensor(tensor) {
const int tensor_idx = gguf_find_tensor(gguf_ctx, ggml_get_name(tensor));
// 从 GGUF 文件头读取偏移量
offs = gguf_get_data_offset(gguf_ctx) + // 数据区起始位置
gguf_get_tensor_offset(gguf_ctx, tensor_idx); // + tensor 相对偏移
// ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
// 这个偏移量是在转换模型为 GGUF 时就确定的!
}
};
GGUF 文件结构:
┌────────────────────────────────────────────────┐
│ GGUF Header │
│ - Magic number │
│ - Version │
│ - Tensor count │
│ - KV metadata count │
├────────────────────────────────────────────────┤
│ KV Metadata │
│ - Model hyperparameters │
│ - Tokenizer info │
├────────────────────────────────────────────────┤
│ Tensor Info (每个 tensor 的元数据) │
│ - name: "token_embd.weight" │
│ offset: 0 │ ← 相对偏移
│ shape: [4096, 32000] │
│ type: F16 │
│ - name: "blk.0.attn_q.weight" │
│ offset: 262144000 │ ← 相对偏移
│ shape: [4096, 4096] │
│ - ... │
├────────────────────────────────────────────────┤ ← data_offset
│ Tensor Data (实际权重数据) │
│ [token_embd.weight data] │ ← offset 0
│ [padding if needed] │
│ [blk.0.attn_q.weight data] │ ← offset 262144000
│ ... │
└────────────────────────────────────────────────┘
Step 2: mmap 映射整个文件到内存
void llama_model_loader::init_mappings(bool prefetch, llama_mlocks * mlock_mmaps) {
if (use_mmap) {
mappings.reserve(files.size());
mmaps_used.reserve(files.size());
for (size_t idx = 0; idx < files.size(); idx++) {
const auto & file = files.at(idx);
// 创建 mmap 对象,映射整个文件
std::unique_ptr<llama_mmap> mapping =
std::make_unique<llama_mmap>(file.get(), prefetch ? -1 : 0, is_numa);
// ^^^^^^^^^^
// 整个文件被映射到虚拟地址空间
mmaps_used.emplace_back(mapping->size(), 0);
mappings.emplace_back(std::move(mapping));
}
}
}
mmap 后的内存布局:
文件: mmap 后的虚拟内存:
┌─────────────────┐ ┌─────────────────┐
│ GGUF Header │ ────▶ │ 0x7f8000000000 │ (只读映射)
│ Metadata │ │ │
│ Tensor Info │ │ │
├─────────────────┤ ├─────────────────┤
│ data_offset │ │ mmap_base │ ← mapping->addr()
│ token_embd │ │ token_embd │
│ (offset=0) │ │ (addr = base) │
├─────────────────┤ ├─────────────────┤
│ attn_q │ │ attn_q │
│ (offset=262M) │ │ (addr = base+262M) │
├─────────────────┤ ├─────────────────┤
│ ... │ │ ... │
└─────────────────┘ └─────────────────┘
Step 3: 创建 buffer_from_host_ptr
if (ml.use_mmap && use_mmap_buffer && buffer_from_host_ptr_supported) {
for (uint32_t idx = 0; idx < ml.files.size(); idx++) {
void * addr = nullptr;
size_t first, last;
// 获取这个文件中实际使用的 tensor 范围
ml.get_mapping_range(&first, &last, &addr, idx, ctx);
// ^^^^^ ^^^^ ^^^^
// 最小 最大 mmap基址
if (first >= last) continue;
// 创建包装 mmap 内存的 buffer
const size_t max_size = ggml_get_max_tensor_size(ctx);
ggml_backend_buffer_t buf = ggml_backend_dev_buffer_from_host_ptr(
dev,
(char *)addr + first, // ← buffer 起始地址
last - first, // ← buffer 大小(不是整个文件)
max_size
);
buf_map.emplace(idx, buf);
}
}
get_mapping_range 的实现:
void llama_model_loader::get_mapping_range(
size_t * first, size_t * last, void ** addr, int idx, ggml_context * ctx
) const {
const auto & mapping = mappings.at(idx);
*first = mapping->size(); // 初始化为最大值
*last = 0; // 初始化为最小值
*addr = mapping->addr(); // mmap 基址
// 遍历所有 tensor,找到实际使用的范围
for (ggml_tensor * tensor = ggml_get_first_tensor(ctx);
tensor;
tensor = ggml_get_next_tensor(ctx, tensor)) {
const auto * weight = get_weight(ggml_get_name(tensor));
if (!weight || weight->idx != idx) continue;
// 更新使用范围
*first = std::min(*first, weight->offs);
// ^^^^^^^^^^^^
// 从 GGUF 读取的偏移量
*last = std::max(*last, weight->offs + ggml_nbytes(tensor));
}
}
Step 4: 为每个 tensor 分配内存(使用预定地址)
if (use_mmap) {
const auto & mapping = mappings.at(weight->idx);
ggml_backend_buffer_t buf_mmap = bufs.at(weight->idx);
// 计算 tensor 在 mmap 内存中的实际地址
uint8_t * data = (uint8_t *)mapping->addr() + weight->offs;
// ^^^^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^^^
// mmap 基址 文件中的偏移量
if (buf_mmap && cur->data == nullptr) {
// 使用预先计算好的地址分配 tensor
ggml_backend_tensor_alloc(buf_mmap, cur, data);
// ^^^^
// 直接传入地址!
// 记录实际使用的内存范围(用于后续 unmap 未使用部分)
auto & mmap_used = mmaps_used[weight->idx];
mmap_used.first = std::min(mmap_used.first, weight->offs);
mmap_used.second = std::max(mmap_used.second, weight->offs + n_size);
}
}
gguf 加载流程
simple-qwen3 from scratch
只考虑在 cpu 上,所以使用的模型是 Qwen3-1.7B-Q6_K.gguf
meta_kv 不用读,我们可以直接指定,只用读 tensor 就可以了
只考虑单后端
加载 tokenizer,加载权重
从工作量和相关性上考虑,连 tokenizer 其实都不用加载,我们直接从现有的 simple.cpp 中获取 std::vector<llama_token> 即可
便于 ai 辅助,应该在 llama.cpp 的仓库中测试
可以采用渐进式?gguf.c 那几个相关文件完全可以复用
流程整理:
- 加载 gguf 文件到内存中
- 解析 gguf 文件,读 tensor_info
cb 有什么用?
如果 qwen3 比较困难,可以考虑直接用 llama.cpp 里的 GPT2, 这样所有东西都是完整的
memory_v 的 shape 错了
不行不行,这样写太难了
我建议从 main-backend 开始改,先改为 mmap + 加载实际的 gguf 文件