写这篇文章的原因是之前在测试 6.824 Lab2B 时总是会出现几个错误,去提了 issue 后也没有得到令人信服的结果,自己有一点头绪但是没验证,这事就这么放着了。
然后最近有个同样做 6.824 的同学给我发了邮件,说他也遇到了同样的问题,重新分析了一下后,本来想简单回复一下的,结果回复的内容越写越多,就干脆直接整理为一篇文章,供大家参考。
异常情况
我之前在对 Lab2B 进行测试时,总是有几个简单的测试点过不了,仿佛代码即使正确,也总是可能出错。我经过分析后发现,都遵循以下这种错误模式:
- Leader 接收了来自上层的请求,还未提交该日志或者只有他提交了日志(该日志已经被 major 收到)时,就因为收到了其他 peer 的 RequestVote RPC 重新变回了 Follower。
- 重新选举后再次成为 Leader 后,由于旧任期的 Log 不能被新任期的 Leader 提交,所以之前的日志无法提交。
- 没有新的请求进来,导致该日志一致无法提交,然后 2 秒后超时,测试无法通过。
- 错误提示都是
one(xxx) failed to reach agreement。
为什么会出现
在 Lab2B 最开始的几个测试中,测试的编写者为了简化测试,测试代码中提交 command 的操作均为 cfg.one(cmd, servers, false),这个函数的第三个参数名为 retry,控制的是对于一个请求,是否需要在超时后重新提交。
这里 retry 被设置为了 false,也就是说整个执行过程中只会调用 rf.Start() 一次,如果遇见了上文说的异常情况,就会被卡住,最后出现超时报错的情况。
也就是说,所谓的异常情况就是恰好遇见了一个 timing 加上 Lab2B 前面的几个测试有“缺陷”造成的。
no-op 机制
Raft 协议中本身是没有这个问题的,在论文第 13 页中说明了一个节点在当选 Leader 后会发送一个 no-op 的日志,这样新 Leader 就能把 no-op 以及它之前未提交的日志一起提交,就不会卡住了。
而且就如同我在 issue 里面说的,那些 cfg.one() 中 retry=false 的测试才可能出现这样的问题,原因在 cfg.one() 的注释中也说明了:
if retry==false, calls Start() only once, in order to simplify the early Lab 2B tests.
那么它是怎么简化那些测试的呢,其实是假想了最简单的情况(即不考虑 no-op 机制的情况):通过比较 cfg.one() 返回的 index 和理想中的 index 做判断,如果两者相等,那么测试就能通过。
比如我提交了三次 command,那么这三次的 command 对应的 log index 就应该是 1,2,3,三次 cfg.one() 返回的 index 也应该是 1,2,3。实现了 no-op 机制的话,三次 cfg.one() 返回的可能是 1,3,4(index 为 2 的日志是 no-op)。
所以添加了 no-op 机制的话,会导致 log index 不可控地发生变化,进而导致测试失败。
这个问题好像无解了,难道真的是测试的编写人员没有考虑到这种 corner case 吗?
理论分析
我们可以考虑一下什么情况下会出现我之前描述的那种异常情况呢?
一个必要条件是出现 Leader 换届。
那什么情况下会发生 Leader 换届呢?
只有当某个节点发生 election timeout 之后才会出现。
这里我们可以考虑分布式系统中的 NPC 问题:
- Network Delay
- Process Pause
- Clock Drift
由于 Raft 没有对各个服务器之间的时钟有着同步的限制,并且 golang 底层测量时间都用的是单调时钟,正常情况下(特别是在能稳定复现的情况下)Clock Drift 的问题不用考虑。
Network Delay
测试中都模拟的是 Network Delay 的情况,比如:
- 消息会丢失
- 消息会延迟到达
消息会丢失/消息会延迟到达意味着网络是不可靠的,这种情况下可能会发生 Leader 换届,也就有可能发生那种异常情况。
但是在我提到的那三个测试中(TestBasicAgree2B,TestFollowerFailure2B,TestLeaderFailure2B),网络都是可靠的,因为这些测试的环境配置都是 cfg := make_config(t, servers, false, false),其中的 unreliable 被设置成了 false。
我们可以查看一下网络环境的源代码:
// func (rn *Network) processReq(req reqMsg)
if reliable == false {
// short delay
ms := (rand.Int() % 27)
time.Sleep(time.Duration(ms) * time.Millisecond)
}
if reliable == false && (rand.Int()%1000) < 100 {
// drop the request, return as if timeout
req.replyCh <- replyMsg{false, nil}
return
}
这段代码说明,只要网络被配置为了 reliable ,就不会出现消息丢失或者消息延迟到达的情况,说明实验模拟的网络环境是一个理想环境,节点不会因为网络环境而出现 election timeout。
所以问题不出在 Network Delay 上。
Process Pause
问题有可能是出在了 Process Pause 上,可能有几种原因:
- GC (垃圾回收)
- 负载过重导致线程调度时某些线程迟迟得不到运行(我猜想的,到底会不会出现这种情况没有考证过)
两种情况都可能会导致异常情况的发生,我们可以假设下面的这个情景:
一个 Leader 进程由于 GC 被暂停了 1s(负载过重同理),期间无法发送 heartbeat,而 Follower 的进程正常运行,导致在 election timeout 这段时间中没有收到来自 Leader 的 AppendEntries RPC,所以发起新一轮选举,Term 改变,异常情况随之发生。
实验模拟
进行完了理论分析,我们可以动手进行实验来验证一下。
根据我们在上文中提到的假设:负载过重导致超时,我们可以从负载和超时两方面进行验证:
- 如果负载增加的情况,异常情况增多
- 或者 election timeout 设置的越短,异常情况越多,
- 把
cfg.one()中的retry参数设置为 true,理论上异常情况应该不会发生。
我们就可以认为该假设是成立的。
负载增加
设置六次实验,每次实验跑 Lab2B 中的 TestRPCBytes2B 10000 次:
- 并发数为 200
- 并发数为 150
- 并发数为 100
- 并发数为 50
- 并发数为 32
- 并发数为 16
并发数为 200
dstest -p 200 -n 10000 -o pause_test_200 TestRPCBytes2B
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 590 | 10000 | $17.76 \pm 7.28$ |
并发数为 150
dstest -p 150 -n 10000 -o pause_test_150 TestRPCBytes2B
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 68 | 10000 | $8.24 \pm 1.76$ |
并发数为 125
dstest -p 125 -n 10000 -o pause_test_125 TestRPCBytes2B
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 32 | 10000 | $6.61 \pm 1.16$ |
并发数为 100
dstest -p 100 -n 10000 -o pause_test_100 TestRPCBytes2B
执行情况
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 9 | 10000 | $5.21 \pm 1.00$ |
并发数为 75
dstest -p 75 -n 10000 -o pause_test_75 TestRPCBytes2B
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 2 | 10000 | $3.95 \pm 0.84$ |
并发数为 50
dstest -p 50 -n 10000 -o pause_test_50 TestRPCBytes2B
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 1 | 10000 | $2.78 \pm 0.59$ |
并发数为 25
dstest -p 25 -n 10000 -o pause_test_25 TestRPCBytes2B
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 2 | 10000 | $1.42 \pm 0.59$ |
Summary
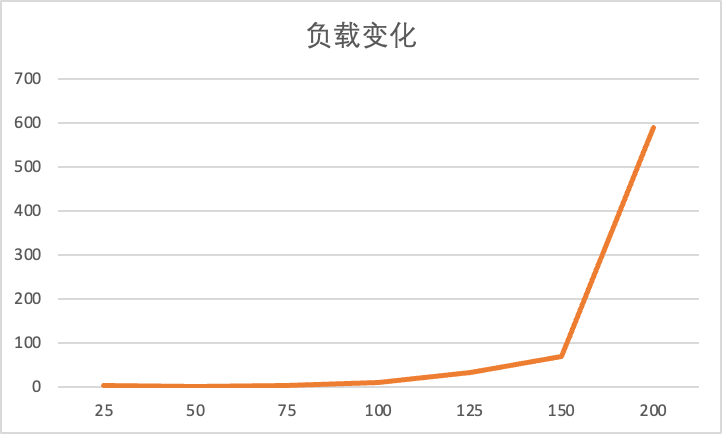
把数据统计为图表后可以看到,负载越高出现异常情况的概率就越大。
改变 Timeout
这里统一选取并发数为 150 的情况作为基准。
Election Timeout: $200 \sim 300ms$
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 172 | 10000 | $8.04 \pm 1.47$ |
Election Timeout: $300 \sim 400ms$
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 68 | 10000 | $8.24 \pm 1.76$ |
Election Timeout: $400 \sim 500ms$
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 16 | 10000 | $10.31 \pm 2.73$ |
Election Timeout: $500 \sim 600ms$
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 16 | 10000 | $7.92 \pm 1.46$ |
Election Timeout: $600 \sim 700ms$
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 14 | 10000 | $7.87 \pm 1.40$ |
Election Timeout: $700 \sim 800ms$
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 12 | 10000 | $8.14 \pm 2.40$ |
Election Timeout: $800 \sim 900ms$
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 9 | 10000 | $8.01 \pm 2.09$ |
Summary
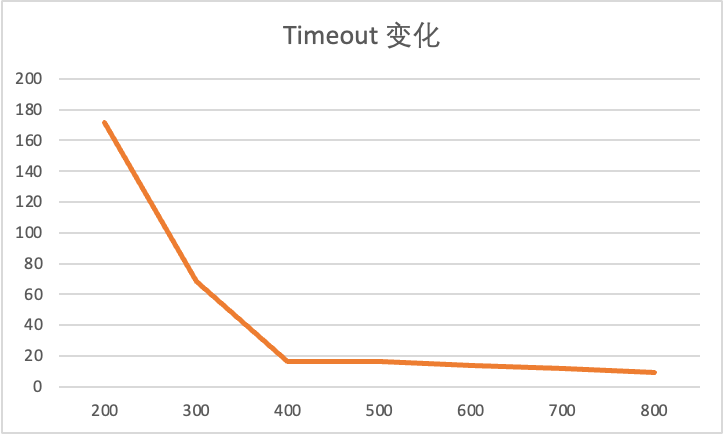
把数据统计为图表后可以看到,election timeout 设置的越长,出现异常情况的概率就越低。
更改参数
将 TestRPCBytes2B 中的 cfg.one() 参数改为 true,重新跑一次下面的命令:
dstest -p 150 -n 10000 -o pause_test_150_retry TestRPCBytes2B
得到的结果是:
| Test | Failed | Total | Time |
|---|---|---|---|
| TestRPCBytes2B | 2 | 10000 | 8.38 +/- 1.73 |
其中的两次失败都是因为重试次数超过 2 次导致 RPC Byte 数量过大。
实际分析
我选取了实验模拟中的一次记录,分析了它的日志和 trace 文件
日志分析
如果假设成立,那么我们在日志中应该观察到 Leader 并没有按照固定的 HeartbeatInterval 发送心跳检测。
以下是日志截取:
...
0103294 TIMR S1 Leader, checking heartbeats in T1
...
0107883 TIMR S1 Leader, checking heartbeats in T1
...
0112964 TIMR S1 Leader, checking heartbeats in T1
...
0129159 TIMR S1 Leader, checking heartbeats in T1
...
0132759 CLNT S1 accepted Client's request Lqog
0132783 TIMR S1 Leader, checking heartbeats in T1
0132783 LOG1 S1 -> S0 Sending (with heartbeat) in T1 {T:1 preLogIdx:9 preLogT:1 len:1 lCommit:9}
0132784 LOG1 S1 -> S2 Sending (with heartbeat) in T1 {T:1 preLogIdx:9 preLogT:1 len:1 lCommit:9}
0199527 LEAD S2 timeout, starts a new election for T2
0199569 LEAD S0 timeout, starts a new election for T2
0199707 TIMR S1 Leader, checking heartbeats in T1
0199709 LOG1 S1 -> S0 Sending (with heartbeat) in T1 {T:1 preLogIdx:9 preLogT:1 len:1 lCommit:9}
0199710 LOG1 S1 -> S2 Sending (with heartbeat) in T1 {T:1 preLogIdx:9 preLogT:1 len:1 lCommit:9}
0199713 VOTE S1 stepping down from leader in T2
0199714 VOTE S1 votes for S2 in T2
0199714 PERS S1 persisting state in T2: {T:2 VF:2 LogLength:11}, rf.getFirstLogIndex:0
0212364 VOTE S2 received vote from S1 (for T2) in T2
0212366 LEAD S2 achieved Majority for T2 (2), converting to leader
0212368 LEAD S2 heartbeat reset triggered manually
...
// repeat pattern
0212369 TIMR S2 Leader, checking heartbeats in T2
0212370 LOG1 S2 -> S0 Sending heartbeat in T2 {T:2 preLogIdx:10 preLogT:1 len:0 lCommit:9}
0212371 LOG1 S2 -> S1 Sending heartbeat in T2 {T:2 preLogIdx:10 preLogT:1 len:0 lCommit:9}
...
分析一下这段日志:
- 一开始 S1 确实在按照 50ms 的间隔发送心跳检测:
0103294 TIMR S1 Leader, checking heartbeats in T10107883 TIMR S1 Leader, checking heartbeats in T10112964 TIMR S1 Leader, checking heartbeats in T1
- S1 收到了来自上层的请求:
0132759 CLNT S1 accepted Client's request Lqog
- 时隔 670ms,S1 才发送了下一轮的心跳检测:
0132783 TIMR S1 Leader, checking heartbeats in T10199707 TIMR S1 Leader, checking heartbeats in T1
- 在这 670ms 中,S0 和 S2 由于没有收到来自于 Leader S1 的心跳检测超时了并开始了下一轮选举:
0199527 LEAD S2 timeout, starts a new election for T20199569 LEAD S0 timeout, starts a new election for T2
- S2 被选举为新的 Leader,开始发送心跳检测
- 由于旧任期的 Log 不能被新任期的 Leader 提交,所以
Lqog无法被提交,卡住了
时隔 670ms 后 S1 才发送了下一轮的心跳检测,可以推断这段时间内发生了 GC 或者在 670ms 内这个进程都未得到调度并执行,符合我们的推断。
但到底是什么原因呢?
我们可以记录并查看 trace 文件来寻找:
// func TestRPCBytes2B(t *testing.T)
traceName := "trace-" + randstring(5)
traceFile, _ := os.Create(traceName)
defer traceFile.Close()
t.Logf("trace file: %s", traceName)
trace.Start(traceFile)
defer trace.Stop()
// using go tool
go tool trace trace-xxx
Trace 文件分析
打开上述日志对应的 trace 文件后,我们可以查看所有 goroutine 的执行情况和垃圾回收的情况。

查看之后可以发现,确实是发生了长达 620ms 的垃圾回收!
在 stop-the-wold(STW) 期间,所有的线程都会被暂停执行,等待垃圾回收完成。
为什么会有长达 620ms 的垃圾回收呢?
个人推测与 CPU 负载过高有关。
结论
异常情况是由 GC 引起的,GC 导致 Leader 不能以正常频率发送心跳检测,导致 Follower 重新开始选举。
测试的编写人员假设了网络环境是理想的,却猜不到有同学在本地跑的时候负载过大发生长时间GC而导致测试失败的情况。