最近看了下之前业界关于 Redlock 的争论,发现还是挺有意思的,正好把自己最近学的知识串了起来,这里就简单总结一下。
Martin 的观点
使用分布式锁的目的
Martin 表示,你必须先清楚你在使用分布式锁的目的是什么?
他认为有两个目的。
第一,效率。
使用分布式锁的互斥能力,是避免不必要地做同样的两次工作(例如一些昂贵的计算任务)。如果锁失效,并不会带来「恶性」的后果,例如发了 2 次邮件等,无伤大雅。
第二,正确性。
使用锁用来防止并发进程互相干扰。如果锁失效,会造成多个进程同时操作同一条数据,产生的后果是数据严重错误、永久性不一致、数据丢失等恶性问题,就像给患者服用了重复剂量的药物,后果很严重。
他认为,如果你是为了前者——效率,那么使用单机版 Redis 就可以了,即使偶尔发生锁失效(宕机、主从切换),都不会产生严重的后果。而使用 Redlock 太重了,没必要。
而如果是为了正确性,Martin 认为 Redlock 根本达不到安全性的要求,也依旧存在锁失效的问题。
NPC 问题
这些异常场景主要包括三大块,这也是分布式系统会遇到的三座大山:NPC。
- N:Network Delay,网络延迟
- P:Process Pause,进程暂停(GC)
- C:Clock Drift,时钟漂移
Martin 用一个进程暂停(GC)的例子,指出了 Redlock 安全性问题:
- 客户端 1 请求锁定节点 A、B、C、D、E
- 客户端 1 的拿到锁后,进入 GC(时间比较久)
- 所有 Redis 节点上的锁都过期了
- 客户端 2 获取到了 A、B、C、D、E 上的锁
- 客户端 1 GC 结束,认为成功获取锁
- 客户端 2 也认为获取到了锁,发生「冲突」
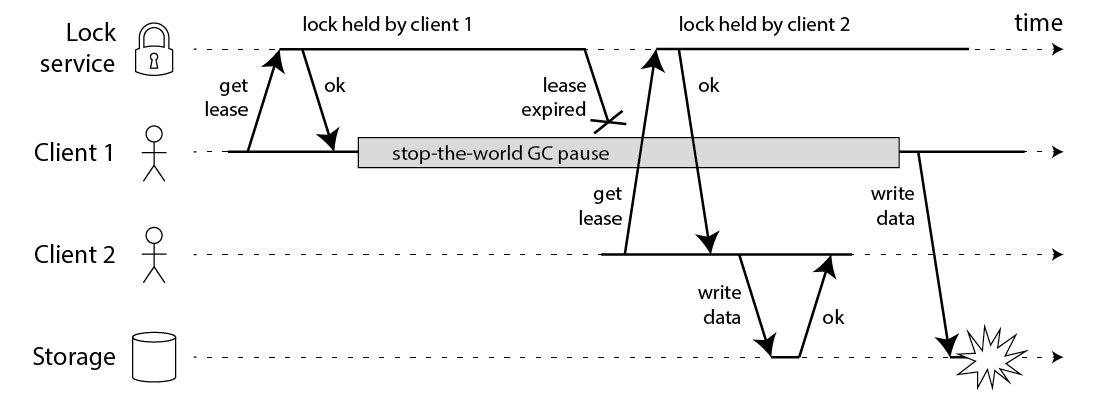
即使是使用没有 GC 的编程语言,在发生网络延迟、时钟漂移时,也都有可能导致 Redlock 出现问题,这里 Martin 只是拿 GC 举例。
因为 Redis 用的时钟不是具有单调性的时钟,所以在发生时间跳跃时,也会导致 Redlock 锁失效
- 客户端 1 获取节点 A、B、C 上的锁,但由于网络问题,无法访问 D 和 E
- 节点 C 上的时钟「向前跳跃」,导致锁到期
- 客户端 2 获取节点 C、D、E 上的锁,由于网络问题,无法访问 A 和 B
- 客户端 1 和 2 现在都相信它们持有了锁(冲突)
Martin 还说明了,如果时钟不失效,网络延迟也有可能带来相同的问题:
- 客户端通过 Redlock 成功获取到锁(通过了大多数节点加锁成功、加锁耗时检查逻辑)
- 客户端开始操作共享资源,此时发生网络延迟、进程 GC 等耗时很长的情况
- 此时,锁过期自动释放
- 客户端开始操作 MySQL(此时的锁可能会被别人拿到,锁失效)
但是 Martin 在博客中举的例子是错误的,被 antirez 怼了回去哈哈
解决方法
相对应的,Martin 提出一种被叫作 fecing token 的方案,保证分布式锁的正确性。
这个模型流程如下:
- 客户端在获取锁时,锁服务可以提供一个「递增」的 token
- 客户端拿着这个 token 去操作共享资源
- 共享资源可以根据 token 拒绝「后来者」的请求
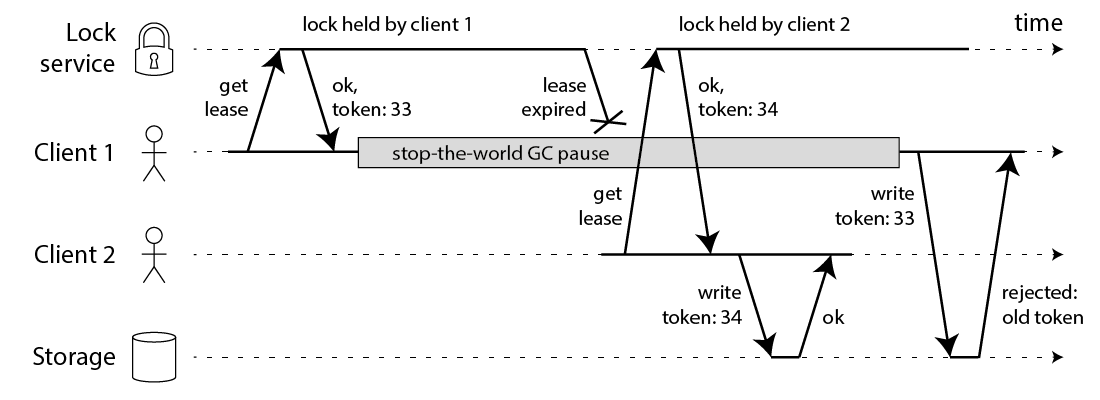
这样一来,无论 NPC 哪种异常情况发生,都可以保证分布式锁的安全性,因为它是建立在「异步模型」上的。
而 Redlock 无法提供类似 fecing token 的方案,所以它无法保证安全性。
他还表示,一个好的分布式锁,无论 NPC 怎么发生,可以不在规定时间内给出结果,但并不会给出一个错误的结果。也就是只会影响到锁的「性能」(或称之为活性),而不会影响它的「正确性」。
结论
1、Redlock 不伦不类(neither fish nor fowl):它对于效率来讲,Redlock 比较重,没必要这么做,而对于正确性来说,Redlock 是不够安全的。
2、时钟假设不合理:该算法对系统时钟做出了危险的假设(假设多个节点机器时钟都是一致的),如果不满足这些假设,锁就会失效。
3、无法保证正确性:Redlock 不能提供类似 fencing token 的方案,所以解决不了正确性的问题。为了正确性,请使用有「共识系统」的软件,例如 Zookeeper。
Antirez 的反驳
时钟问题
对于对方提到的「时钟修改」问题,Antirez 反驳到:
- 手动修改时钟:不要这么做就好了,否则你直接修改 Raft 日志,那 Raft 也会无法工作…
- 时钟跳跃:通过「恰当的运维」,保证机器时钟不会大幅度跳跃(每次通过微小的调整来完成),实际上这是可以做到的
网络延迟,GC 问题
这里先复习一下 Redlock 的流程:
- 客户端先获取「当前时间戳 T1」
- 客户端依次向这 5 个 Redis 实例发起加锁请求(用前面讲到的 SET 命令),且每个请求会设置超时时间(毫秒级,要远小于锁的有效时间),如果某一个实例加锁失败(包括网络超时、锁被其它人持有等各种异常情况),就立即向下一个 Redis 实例申请加锁
- 如果客户端从 3 个(大多数)以上 Redis 实例加锁成功,则再次获取「当前时间戳T2」,如果 T2 - T1 < 锁的过期时间,此时,认为客户端加锁成功,否则认为加锁失败
- 加锁成功,去操作共享资源(例如修改 MySQL 某一行,或发起一个 API 请求)
- 加锁失败,向「全部节点」发起释放锁请求
Antirez 强调:如果在 1-3 发生了网络延迟、进程 GC 等耗时长的异常情况,那在第 3 步 T2 - T1,是可以检测出来的,如果超出了锁设置的过期时间,那这时就认为加锁会失败,之后释放所有节点的锁就好了!
Antirez 继续论述,如果对方认为,发生网络延迟、进程 GC 是在步骤 3 之后,也就是客户端确认拿到了锁,去操作共享资源的途中发生了问题,导致锁失效,那这不止是 Redlock 的问题,任何其它锁服务例如 Zookeeper,都有类似的问题,这不在讨论范畴内。
质疑 fencing token 机制
这一部分对我的启发是最大的。
Antirez 提出了两个问题:
Fencing token 必须要求共享资源服务器有拒绝旧 Token 的能力
例如,要操作 MySQL,从锁服务拿到一个递增数字的 token,然后客户端要带着这个 token 去改 MySQL 的某一行,这就需要利用 MySQL 的「事物隔离性」来做。
// 两个客户端必须利用事物和隔离性达到目的
// 注意 token 的判断条件
UPDATE table T SET val = $new_val WHERE id = $id AND current_token < $token
但如果操作的不是 MySQL 呢?例如向磁盘上写一个文件,或发起一个 HTTP 请求,那这个方案就无能为力了,这对要操作的资源服务器,提出了更高的要求。
一般的,这里要求共享资源服务器能实现原子性的 CAS 操作(即 compare-and-set 操作),如果该系统能实现 CAS,某种程度上就相当于该系统能够实现 linearizable,那么还用分布式锁做什么呢,直接访问就好了。
在使用分布式锁的大部分情境下,我们对共享资源服务器是没有额外控制的。
Antirez posted:
From Martin post: “However, the storage server remembers that it has already processed a write with a higher token number (34), and so it rejects the request with token 33.” This is not eventual consistency, this is refusing any new write with ID < past_ID, which requires linearizability.
“You don’t need a token service if you are going to set the token on the locked resource, perform work and then unset the token. your lock is completely superfluous in that scenario.”
“Most of the times when you need a distributed lock system that can guarantee mutual exclusivity, when this property is violated you already lost. Distributed locks are very useful exactly when we have no other control in the shared resource.”
Redlock 提供的随机值也能达到 Fencing Token 的作用
- 客户端使用 Redlock 拿到锁
- 客户端在操作共享资源之前,先把这个锁的 VALUE,在要操作的共享资源上做标记
- 客户端处理业务逻辑,最后,在修改共享资源时,判断这个标记是否与之前一样,一样才修改(类似 CAS 的思路)
还是以 MySQL 为例,举个例子就是这样的:
- 客户端使用 Redlock 拿到锁
- 客户端要修改 MySQL 表中的某一行数据之前,先把锁的 VALUE 更新到这一行的某个字段中(这里假设为 current_token 字段)
- 客户端处理业务逻辑
- 客户端修改 MySQL 的这一行数据,把 VALUE 当做 WHERE 条件,再修改
UPDATE table T SET val = $new_val WHERE id = $id AND current_token = $redlock_value
但这里还有个小问题:两个客户端通过这种方案,先「标记」再「检查+修改」共享资源,那这两个客户端的操作顺序无法保证
而用 Martin 提到的 fecing token,因为这个 token 是单调递增的数字,资源服务器可以拒绝小的 token 请求,保证了操作的「顺序性」。
Antirez 的解释是:分布式锁的本质,是为了「互斥」,只要能保证两个客户端在并发时,一个成功,一个失败就好了,不需要关心「顺序性」。
结论
1、作者同意对方关于「时钟跳跃」对 Redlock 的影响,但认为时钟跳跃是可以避免的,取决于基础设施和运维。 2、Redlock 在设计时,充分考虑了 NPC 问题,在 Redlock 步骤 3 之前出现 NPC,可以保证锁的正确性,但在步骤 3 之后发生 NPC,不止是 Redlock 有问题,其它分布式锁服务同样也有问题,所以不在讨论范畴内。
总结
一个分布式锁,在极端情况下,不一定是安全的。
Redlock 只有建立在「时钟正确」的前提下,才能正常工作,如果你可以保证这个前提,那么可以拿来使用。
如何正确的使用分布式锁?
1、使用分布式锁,在上层完成「互斥」目的,虽然极端情况下锁会失效,但它可以最大程度把并发请求阻挡在最上层,减轻操作资源层的压力。
2、但对于要求数据绝对正确的业务,在资源层一定要做好「兜底」,设计思路可以借鉴 fecing token 的方案来做。
Other’s Option
Flavio Junqueira
However, this is not entirely true if acquiring the lock also implies that the shared resource protected by the lock needs to be involved.
Say that every time a client acquires a lock to exclusively access a resource, it goes to the resource and before anything else it marks the resource in such a way that clients that acquired the lock previously cannot access the resource. In the scenario above, client C1 thinks that it still holds the lock, but when it tries to access the shared resource, it fails because it has an earlier mark from C2.
That is:
- Get the lock
- Mark the resource (like an epoch number)
- Do something
Flavio 还提到,如果共享资源是分布式的呢?
这个问题就又回到了 Antirez 反驳时说的观点:如果资源是分布式的,那么如果要让标记成功,即后续所有的读都要看到之前最近的写,也就是要支持 Linearizable,那么还有什么必要用锁呢?
How to obtain an epoch number
A simple way to obtain an epoch number to use with the scheme described above is through cversion in ZooKeeper. For example, if the lock znode is /lock, then the cversion of / strictly increases with the number of children. Consequently, every time the /lock znode is created, the version is incremented. Incrementing a value and conditionally updating a znode with that value is also a valid option.
Summary
The idea is general idea is to make sure the shared resource is consistent by preventing old writers from coming back and messing with the state. It might not always be possible to introduce such epochs with legacy systems, but we do have examples of systems that make use of this scheme.
Etcd
The basic idea of the lease mechanism is: a server grants a token, which is called a lease, to a requesting client. When the server grants a lease, it associates a TTL with the lease. When the server detects the passage of time longer than the TTL, it revokes the lease. While the client holds a non revoked lease it can claim that it owns access to a resource associated with the lease.
The most important aspect of the lease mechanism is that TTL is defined as a physical time interval. Both of the server and client measures passing of time with their own clocks. It allows a situation that the server revokes the lease but the client still claims it owns the lease.
Actually, the lease mechanism itself doesn’t guarantee mutual exclusion. Owning a lease cannot guarantee the owner holds a lock of the resource.
version number validation
In the case of controlling mutual accesses to keys of etcd itself with etcd lock, mutual exclusion is implemented based on the mechanism of version number validation (it is sometimes called compare and swap in other systems like Consul).
In etcd’s RPCs like Put or Txn, we can specify required conditions about revision number and lease ID for the operations. If the conditions are not satisfied, the operation can fail. With this mechanism, etcd provides distributed locking for clients. It means that a client knows that it is acquiring a lock of a key when its requests are completed by etcd cluster successfully.