FAQ
What is an advisory lock?
An “advisory lock” is simply a tool/API provided by Postgres to create arbitrary locks that can be acquired by applications. These locks, however, are not enforced in any meaningful way by the database – it’s up to application code to give them meaning (the same way any other non-database distributed lock would work).
What is a write-through cache?
A write-through cache is a caching strategy where data is simultaneously written into the cache and the corresponding database or backing store.
When data is written, it is first written to the cache and then immediately written to the main memory (or disk).
The main advantage of a write-through cache is that it offers a high degree of data reliability and consistency, as any change to the data is immediately propagated to the main memory. However, the trade-off is that write operations can be slower compared to other caching strategies (like write-back cache), because every write operation has to be done twice – once to the cache, and once to the main memory.
What is a sequencer?
Sequencer is an opaque byte-string that describes the state of the lock immediately after acquisition. It contains the name of the lock, the mode in which it was acquired (exclusive or shared), and the lock generation number.
Client can get a sequencer from the corresponding handle, the client passes the sequencer to servers (such as file servers) if it expects the operation to be protected by the lock. The recipient server is expected to test whether the sequencer is still valid and has the appropriate mode.
Analyze
Key Features
- provide coarse-grained locking as well as reliable storage for a loosely-coupled distributed system.
- the design emphasis is on availability and reliability, as opposed to high performance
Two Questions
Why a lock service among a client library ?
- Our developers sometimes do not plan for high availability in the way one would wish, a lock server makes it easier to maintain existing program structure and communication patterns.
- Many of our services that elect a primary or that partition data between their components need a mechanism for advertising the results. The lock service itself is well-suited for this task, both because this reduces the number of servers on which a client depends, and because the consistency features of the protocol are shared.
- A lock-based interface is more familiar to our programmers.
- A lock service reduces the number of servers needed for a reliable client system to make progress.
Why coarse-grained locks over fine-grained ones ?
- Coarse-grained locks impose far less load on the lock server.
- It is good for coarsegrained locks to survive lock server failures, there is little concern about the overhead of doing so.
- It is straightforward for clients to implement their own fine-grained locks tailored to their application.
- An application might partition its locks into groups and use Chubby’s coarse-grained locks to allocate these lock groups to application-specific lock servers.
Basic Structures
System View
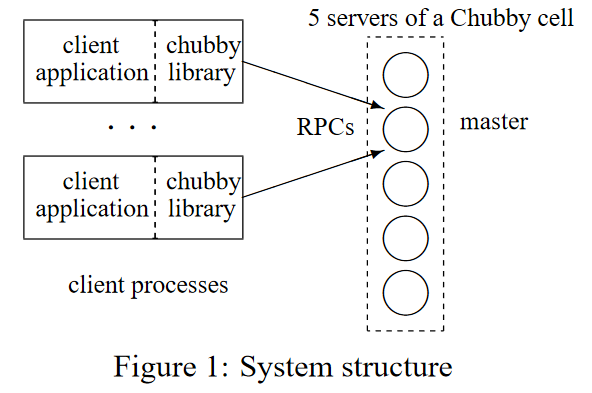
- A Chubby cell consists of a small set of servers (typically five) known as replicas, placed so as to reduce the likelihood of correlated failure.
- Only the master initiates reads and writes of this database.
- Read requests are satisfied by the master alone.
- Clients can find the master by sending master location requests to the replicas listed in the DNS.
- The current master polls the DNS periodically and eventually notices the replica’s change (like failed and then being replaced).
Data View
Chubby exports a file system interface similar to, but simpler than that of UNIX. It consists of a strict tree of files and directories in the usual way, with name components separated by slashes.
The design differs from UNIX in a ways that ease distribution. To allow the files in different directories to be served from different Chubby masters, we do not expose operations that can move files from one directory to another, we do not maintain directory modified times, and we avoid path-dependent permission semantics (that is, access to a file is controlled by the permissions on the file itself rather than on directories on the path leading to the file).
- The name space contains only files and directories, collectively called nodes.
- Nodes may be either permanent or ephemeral.
- Each node has various meta-data, including three names of access control lists (ACLs) used to control reading, writing and changing the ACL names for the node.
- ACLs are themselves files located in an ACL directory, which is a well-known part of the cell’s local name space.
- Clients open nodes to obtain handles that are analogous to UNIX file descriptors.
The distribute lock
分布式锁的问题其实包含三个部分,分别是
- 一致性协议
- 分布式锁的实现
- 分布式锁的使用
三个部分自下而上完成了在分布式环境中对锁需求,下面将从这三个方面介绍 Chubby 的设计。
Consensus Protocol
一致性协议其实并不是锁需求直接相关的,假设我们有一个永不宕机的节点和永不中断的网络,那么一个单点的存储即可支撑上层的锁的实现及使用。但这种假设在互联网环境中是不现实的,所以才引入了一致性协议,来保证我们可以通过副本的方式来容忍节点或网络的异常,同时又不引起正确性的风险,作为一个整体对上层提供高可用的服务。
Chubby 采用的是一个有强主的 Multi-Paxos,其概要实现如下:
- 多个副本组成一个集群,副本通过一致性协议选出一个 Master,集群在一个确定的租约时间内保证这个 Master 的领导地位;
- Master周期性的向所有副本刷新延长自己的租约时间;
- 每个副本通过一致性协议维护一份数据的备份,而只有Master可以发起读写操作;
- Master挂掉或脱离集群后,其他副本发起选主,得到一个新的Master;
可以近似看做一个不会宕机不会断网的节点,能保证所有成功写入的操作都能被后续成功的读取读到。
The Implement
Interface
Chubby 的对外接口是外部使用者直接面对的使用 Chubby 的方式,是连接分布式锁的实现及使用之间的桥梁:
- Chubby 提供类似 UNIX 文件系统的数据组织方式,包括Files和Directory来存储数据或维护层级关系,统称 Node;提供跟 Client 同生命周期的 Ephemeral 类型 Node 来方便实现节点存活监控;通过类似于 UNIX 文件描述符的 Handle 方便对 Node 的访问;Node 除记录数据内容外还维护如 ACL、版本号及 Checksum 等 metadata。
- 提供众多方便使用的API,包括获取及关闭 Handle 的 Open 及 Close 接口;获取释放锁的 Aquire,Release 接口;读取和修改 Node 内容的 GetContentAndStat,SetContent,Delete 接口;以及其他访问元信息、Sequencer,ACL 的相关接口。
- 提供 Event 的事件通知机制来避免客户端轮训的检查数据或 Lock 的变化。包括 Node 内容变化的事件;子 Node 增删改的事件;Chubby 服务端发生故障恢复的事件;Handle 失效事件。客户端收到事件应该做出对应的响应。
Lock
每一个 File 或者 Directory 都可以作为读写锁使用,接受用户的 Aquire,Release 等请求。锁依赖下层的一致性服务来保证其操作顺序。Chubby 提供的是 Advisory Lock 的实现,相对于 Mandatory Lock,由于可以访问加锁 Node 的数据而方便数据共享及管理调试。分布式锁面对的最大挑战来自于客户端节点和网络的不可靠,Chubby 提供了两种锁实现的方式:
完美实现:
- Aquire Lock 的同时,Master 生成一个包含 Lock 版本号和锁类型的 Sequencer;
- Chubby Server 在 Lock 相关节点的元信息中记录这个版本号,Lock 版本号会在每次被成功 Aquire 时加一;
- 成功 Aquire Lock 的 Handle 中也会记录这个 Sequencer;
- 该 Handle 的后续操作都可以通过比较元信息中的 Lock 版本号和 Sequencer 判断锁是否有效,从而接受或拒绝;
- 用户直接调用 Release 或 Handle 由于所属 Client Session 过期而失效时,锁被释放并修改对应的元信息。
简易实现:
- Handle Aquire Lock 的同时指定一个叫做 lock-delay 的时长;
- 获得 Lock 的 Handle 可以安全的使用锁功能,而不需要获得 Sequencer;
- 获得 Lock 的 Handle 失效后,Server 会在 lock-delay 的时间内拒绝其他加锁操作。
- 而正常的 Release 操作释放的锁可以立刻被再次获取;
- 注意,用户需要保证在指定的 lock-delay 时间后不会再有依赖锁保护的操作;
对比两种实现方式,简易版本可以使用在无法检查 Sequencer 的场景从而更一般化,但也因为 lock-delay 的设置牺牲了一定的可用性,同时需要用户在业务层面保证 lock-delay 之后不会再有依赖锁保护的操作。
Cache
Chubby 对自己的定位是需要支持大量的 Client,并且读请求远大于写请求的场景,因此引入一个对读请求友好的 Client 端 Cache,来减少大量读请求对 Chubby Master 的压力便十分自然,客户端可以完全不感知这个 Cache 的存在。Cache 对读请求的极度友好体现在它牺牲写性能实现了一个一致语义的 Cache:
- Cache 可以缓存几乎所有的信息,包括数据,数据元信息,Handle 信息及 Lock;
- Master 收到写请求时,会先阻塞写请求,通过返回所有客户端的 KeepAlive 来通知客户端 Invalid 自己的 Cache;
- Client 直接将自己的 Cache 清空并标记为 Invalid,并发送 KeepAlive 向 Master 确认;
- Master 收到所有 Client 确认或等到超时后再执行写请求。
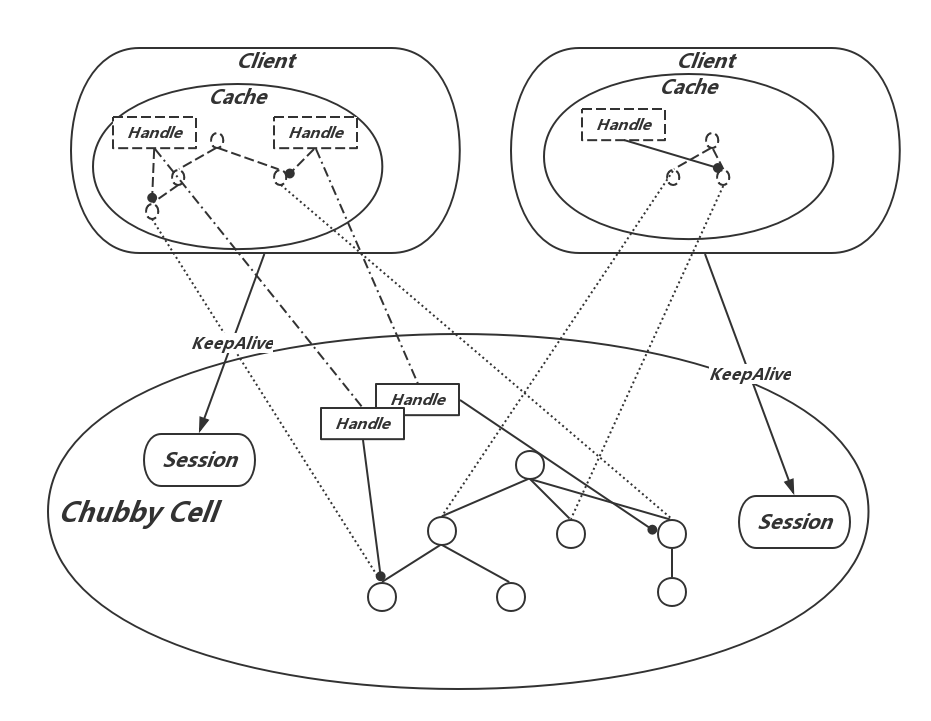
Session and KeepAlive
Session 可以看做是 Client 在 Master 上的一个投影,Master 通过 Session 来掌握并维护 Client:
- 每个 Session 包括一个租约时间,在租约时间内 Client 是有效的,Session 的租约时间在 Master 视角和 Client 视角由于网络传输时延及两端的时钟差异可能略有不同;
- Master 和 Client 之间通过 KeepAlive 进行通信,Client 发起 KeepAlive,会被 Master 阻塞在本地,直到 Session 租约临近过期,此时 Master 会延长租约时间,并返回阻塞的 KeepAlive 通知 Client。除此之外,Master 还可能在 Cache 失效或 Event 发生时返回 KeepAlive;
- Master 除了正常的在创建连接及租约临近过期时延长租约时间外,故障恢复也会延长 Session 的租约;
- Client 的租约过期会先阻塞本地的所有请求,进入 jeopardy 状态,等待额外的45s,以期待与 Master 的通信恢复。如果事与愿违,则返回用户失败。
Session 及 KeepAlive 给了 Chubby Server 感知和掌握 Client 存活的能力,这对锁的实现也是非常重要的,因为这给了 Master 一个判断是否要释放失效 Lock 的时机。最后总结下,这些机制之间的关系,如下图:
The Usage
锁的使用跟上面提到的锁的实现是紧密相关的,由于客户端节点及网络的不可靠,即使 Chubby 提供了直观如 Aquire,Realease 这样的锁操作,使用者仍然需要做出更多的努力来配合完成锁的语义,Chubby 论文中以一个选主场景对如何使用锁给出了详细的说明,以完美方案为例:
- 所有 Primary 的竞争者,Open 同一个 Node,之后用得到的 Handle 调用 Aquire 来获取锁;
- 只有一个成功获得锁,成为 Primary,其他竞争者称为 Replicas;
- Primary 将自己的标识通过 SetContent 写入 Node;
- Replicas 调用 GetContentsAndStat 获得当前的 Primary 标识,并注册该 Node 的内容修改 Event,以便发现锁的 Release 或 Primary 的改变;
- Primary 调用 GetSequencer 从当前的 Handle 中获得 sequencer,并将其传递给所有需要锁保护的操作的 Server;
- Server 通过 CheckSequencer 检查其 sequencer 的合法性,拒绝旧的 Primary 的请求。
如果是简单方案,则不需要 Sequencer,但需要在 Aquire 操作时指定 lock-delay,并保证所有需要锁保护的操作会在最后一次 Session 刷新后的 lock-delay 时间内完成。