Designing a TPS for clouds will meet these challenges:
- Diverse functionality.
- The concept of translytics as “a unified and integrated data platform that supports multi-workloads such as transactional, operational, and analytical simultaneously in realtime, … and ensures full transactional integrity and data consistency”.
- Scale
- Cloud-first data platforms are designed to scale well beyond the limits of a single application.
- Latency
- With the thrust into new interactive domains like social networks, messaging and algorithmic trading,latency becomes essential.
- Multi-tenancy
- Maintaining access rights is therefore an important design consideration for TPSs.
论文的工作集中于以下几点:
- 重新设计了一个 Omid Low Latency (Omid LL) 协议,解决了 Omid2 中的性能瓶颈。
- 对只涉及到单个记录的事务设计了一套新算法,Omid Fast Path (Omid FP),能以原生 HBase 的性能运行单个记录的事务。
- 为 Omid 增加了 SQL 支持。
Omid Low Latency
下表列出来相近的几个分布式事务协议在设计上的不同选择。
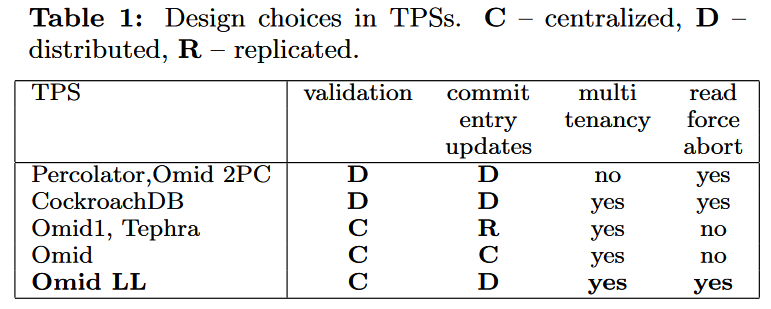
这里解释一下提交条目(Commit Entry):
所有的事务实现本质上都体现了 downscale 的思想,将某个原子操作降级为对更小 scope(或临界区)的原子操作:
- 分布式事务可以利用中心节点,降级为中心节点状态的单机事务。
- 单机事务可以降级为某个mutex的原子操作。
- mutex的原子操作可以降级为一次CAS操作。
执行这个原子操作的时间节点可以称为状态同步点,在此时间节点之前,事务的状态为 Pending,在此时间节点之后,该事务对外界的可见性要么为 Commit 要么为 Abort。
在 Omid 中,提交条目的更新时间点就为这个事务的状态同步点。
“Commit Entry Updates” 这一栏就是在说明提交条目的存在形式。
Omid LL 采用了:
- Centralized validation: 集中式的验证(在TM里集中进行冲突检测)避免了在数据存储中使用悲观锁,并且拥有良好的可扩展性。(在Omid 2017中已经得到验证)
- Distributed commit entry updates with multi-tenancy:
- Omid 2014 将提交条目复制到客户端中,显然在消耗高带宽的同时失去了更好的扩展性;为了降低 TM 写入的性能瓶颈,Omid 2014 以批量写入的方式增加吞吐量,同时也提高了延迟。
- Omid 2017 中,低延时是工作的一个重要目标。工作将写入提交条目的操作均分到了客户端上。
- Write intent resolution: 这涉及到的决策是:在执行事务读操作时,如果读到了一个事务状态不确定的记录,本事务是选择等待还是中止事务。Omid LL 选择了 “reads to force aborts”。
OMid LL 的提交操作也分为两个阶段:
- 客户端向 TM 发送写集和 $ts_r$,等待 TM 进行决策。如果结果为通过,则客户端向 CT(Commit Table) 中写入一条记录(同时检查自己是否被其他事务中止了),写入成功则代表提交操作成功。
- 对于写集中的记录,事务将其 commit 字段修改为自身的 $ts_c$;全部完成后删除 CT 中的记录。
高可用部分,Omid LL 使用了主从两个进程,并使用 epoch 来分块划分时间戳,保证后任 TM 所分配的时间戳一定大于前任 TM,并使用了一个 “locally-checkable lease” 来确保 “no client will be able to commit a transaction in an old epoch after the new TM has started using a new one”。
Omid Fast Path
The goal of our fast path is to forgo the overhead associated with communicating with the TM to begin and commit transactions.
FP的优化策略聚焦于单键值的事务:
brc(key):开启事务,读最新已提交的版本。- 可能会忽略掉正在进行 post-commit 的事务,但论文中说这种行为是符合 FP 语义的。
bwc(key, val):直接写入一个新版本,要求其 $ts_c$ 大于已有版本。br(key):开启事务,读最新已提交的版本。wc(ver, key, val): 验证自返回 ver 的 br 调用以来未对 key 进行写操作,将 val 写入 key 的新版本,并提交。
bwc 和 wc操作需要产生一个新版本,需要保证以下性质
- 新 version 大于所有旧 version,但小于未来 TM 产生的 version。
- 能检测出与普通事务的冲突。
为了在不访问 TM 的情况下产生一个新版本,Omid FP 采用了 HLC(Hybrid Logical Clock)。
What is HLC?
An HLC timestamp typically includes two parts:
- A physical component which is assigned by the TM.
- A logical component that behaves like a locally advancing sequence number.
在 FP 中改变版本时只增加 logical ts 即可(通过 putVersion 函数)。
现在考虑 FP 事务与普通事务写操作的冲突检测:
- 如果普通事务早于 FP 事务写入,FP 事务会 abort。(如果 FP 事务在写入时发现存在一个暂时的版本,就会直接 abort)。
- 如果 FP 事务在某个普通事务的读和提交之间完成了,如下图:

FP 事务并没有记录在 CT 中,旧的检测机制失效了。为了能让T1提交时检测出冲突,Omid FP做了以下改动:
- 每个 key 对应一个 maxVersion,保证 maxVersion 大于等于这个 key 的任何已提交版本。
putVersion会提升 maxVersion。- 普通事务的读会提升 maxVersion 到不小于事务的 $ts_r$。
- 普通事务的写会检查 maxVersion 不大于事务的 $ts_r$,检查未通过说明有 FP 事务与它发生了写冲突。
这个改动增加了普通路径的开销,为每个记录都维护一个 maxVersion 字段开销非常大,所以 OMid 在每个 HBase 的 region server 上维护一个 Local Version Clock (LVC),作为该区域所有记录的 maxVersion,以增加 false abortion 的代价降低了性能开销:“a transactional read modifies the LVC only if its tsr exceeds it”。