Extensive Reading
Author Info
Background
- The Accuracy-Speed Trade-off: The effectiveness of SD is limited by a fundamental trade-off: very small draft models are fast but often diverge from the target model’s distribution, leading to low acceptance rates. Conversely, larger draft models have higher acceptance rates but are too slow to provide significant speedups.
- Limitations of Single-Stage Verification: As the performance gap between the draft and target models widens, the output distributions diverge significantly, diminishing the acceleration gains. Even relaxed verification methods like Fuzzy Speculative Decoding struggle to bridge large distributional gaps between a tiny draft model and a massive target model in a single step.
Insights
The authors propose Pyramid Speculative Decoding, which inserts an intermediate “Qualifier Model” between the small Draft and the large Target. This creates a hierarchical pipeline that bridges the “distributional gap” between the small and large models.
作者也提到了 PSD 的理论基础,熵的梯度变化:
- Small Models: High entropy (unsure, flat distributions).
- Large Models: Low entropy (confident, sharp distributions).
Challenges
How to accelerate LLM inference using the qualifier model?
If we use two nested vanilla speculative decoding, the qualifier model will be redundant.
在严格匹配模式下,一个 token 被最终接受必须同时满足:
- 草稿模型 $M_D$ 生成的 token 必须与中间模型 $M_Q$ 的预测完全一致 ($x_D = x_Q$)。
- 中间模型 $M_Q$ 的 token 必须与目标模型 $M_T$ 的预测完全一致 ($x_Q = x_T$)。
- 这就意味着,最终被接受的 token 必须满足 $x_D = x_Q = x_T$。而在标准的 2-Model SD(只有草稿和目标模型)中,接受条件仅仅是 $x_D = x_T$。
- 引入 $M_Q$ 并没有放宽最终的接受标准(目标模型 $M_T$ 该拒绝的还是会拒绝),反而增加了一个中间约束。
只有当 $M_Q$ 允许分布相似而不是完全一致时,它才能充当一个桥梁,把草稿模型较差的分布“修正”得更接近目标模型,从而提升最终的接受率。
Approaches
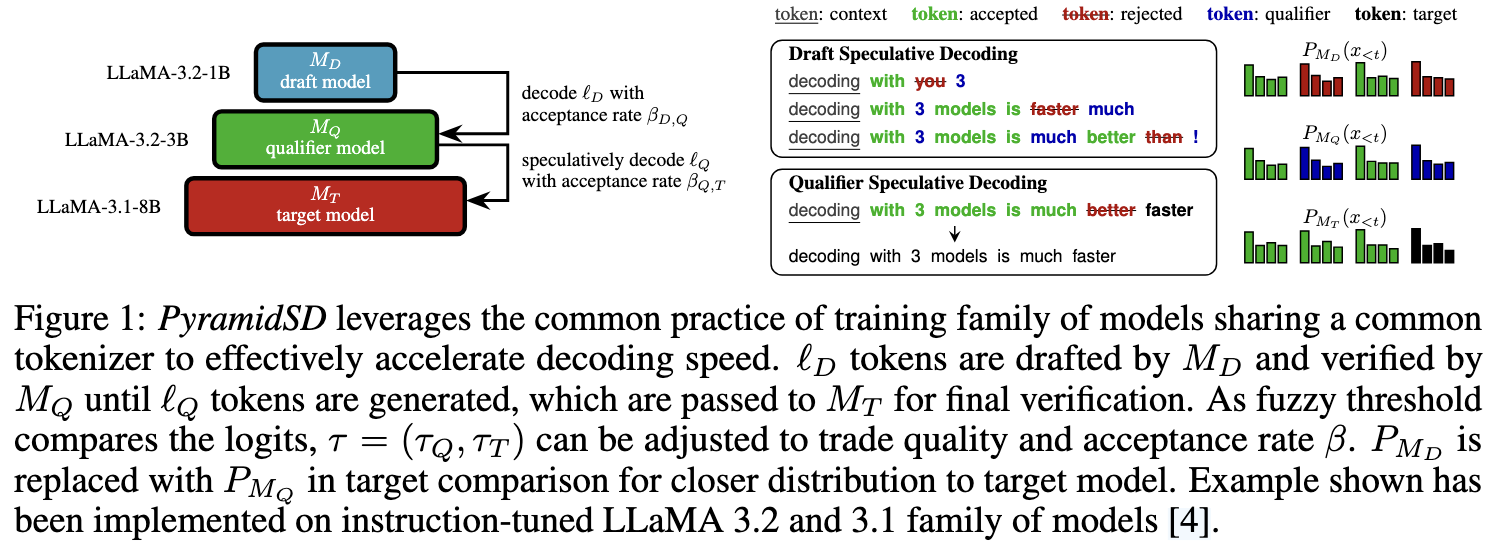
The framework utilizes three models with a shared tokenizer, scaled by parameter size:
- Draft Model ($M_D$): Smallest and fastest (e.g., 1B parameters). High uncertainty (entropy). Generates initial token proposals.
- Qualifier Model ($M_Q$): Intermediate size (e.g., 3B parameters). Acts as a bridge. It filters out low-confidence tokens from the draft before they reach the target.
- Target Model ($M_T$): Largest and most accurate (e.g., 8B parameters). Performs final verification.
PyramidSD uses two nested speculative stages:
- Draft $\rightarrow$ Qualifier: The Draft model proposes a sequence of tokens. The Qualifier verifies these tokens using a “fuzzy” acceptance criterion (checking if the distributions are sufficiently similar).
- Qualifier $\rightarrow$ Target: Tokens accepted by the Qualifier are then passed to the Target model for final verification, again using a relaxed divergence threshold.
Qualifier -> Target 都是采用 fuzzy acceptance criterion, 但是 Draft -> Qualifier 其实有两种方式
PyramidSD with Fuzzy Acceptance ($PSD_F$):
- Stage 1: Qualifier checks Draft using divergence threshold $\tau_Q$.
- Stage 2: Target checks Qualifier using divergence threshold $\tau_T$.
- Result: This allows for maximum speed (up to 1.91x) but introduces higher variance because errors can compound across two “fuzzy” checks. PyramidSD with Assisted Decoding ($PSD_A$):
- Stage 1: If the Qualifier rejects a token from the Draft, it does not just fail; instead, it samples a new token from its own distribution (Assisted Decoding). This acts as a “hard” correction rather than a fuzzy check.
- Stage 2: The Target verifies the Qualifier’s output using the standard relaxed divergence threshold $\tau_T$.
- Result: This variant is more stable (lower variance) because the Qualifier acts as a reliable “fallback generator,” ensuring a quality floor before the tokens reach the Target.
PSD_A 的第一阶段就是标准的 Speculative Decoding‘s rejection sampling
无论是 PSDA 还是 PSDF 都是有损的,第二阶段都是用的 Fuzzy Acceptance
Evaluation
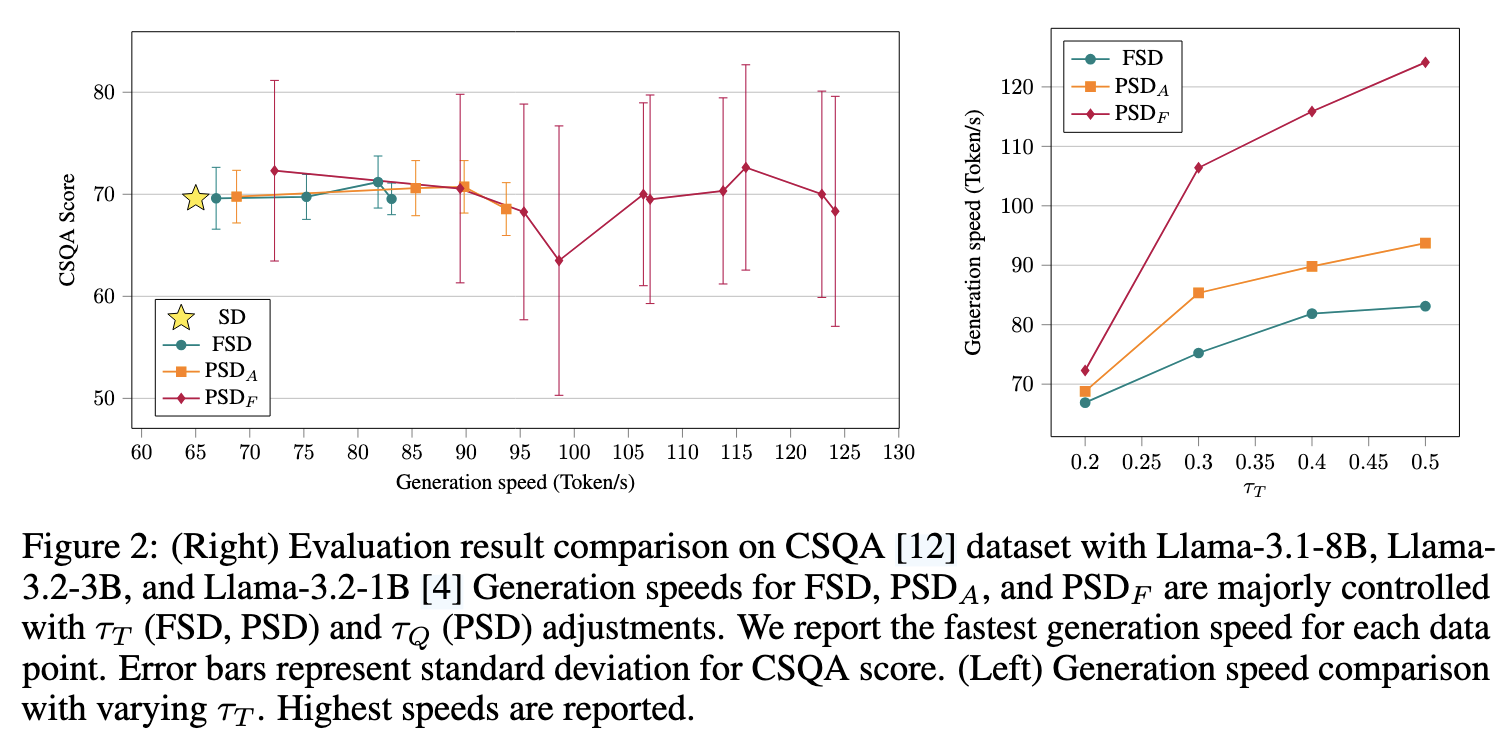
- PSDF 基本没什么实际价值,波动太大了
- PSDA 也就比 FSD(原本的 Fuzzy Speculative Decode) 强 10%
所以这文章是个 Workshop
Thoughts
When Reading
有一个问题还没想清楚,这种级联式的 Speculative Decoding 一定要是有损的吗?
以及引入 M_Q 之后,two nest vanilla speculative decoding 到底有没有效果,为什么?