Extensive Reading
The goal of this survey is to provide an overarching understanding of how current approaches are tackling the resource challenges posed by large foundation models and to potentially inspire future breakthroughs in this field.
Author Info
Foundation Model Overview
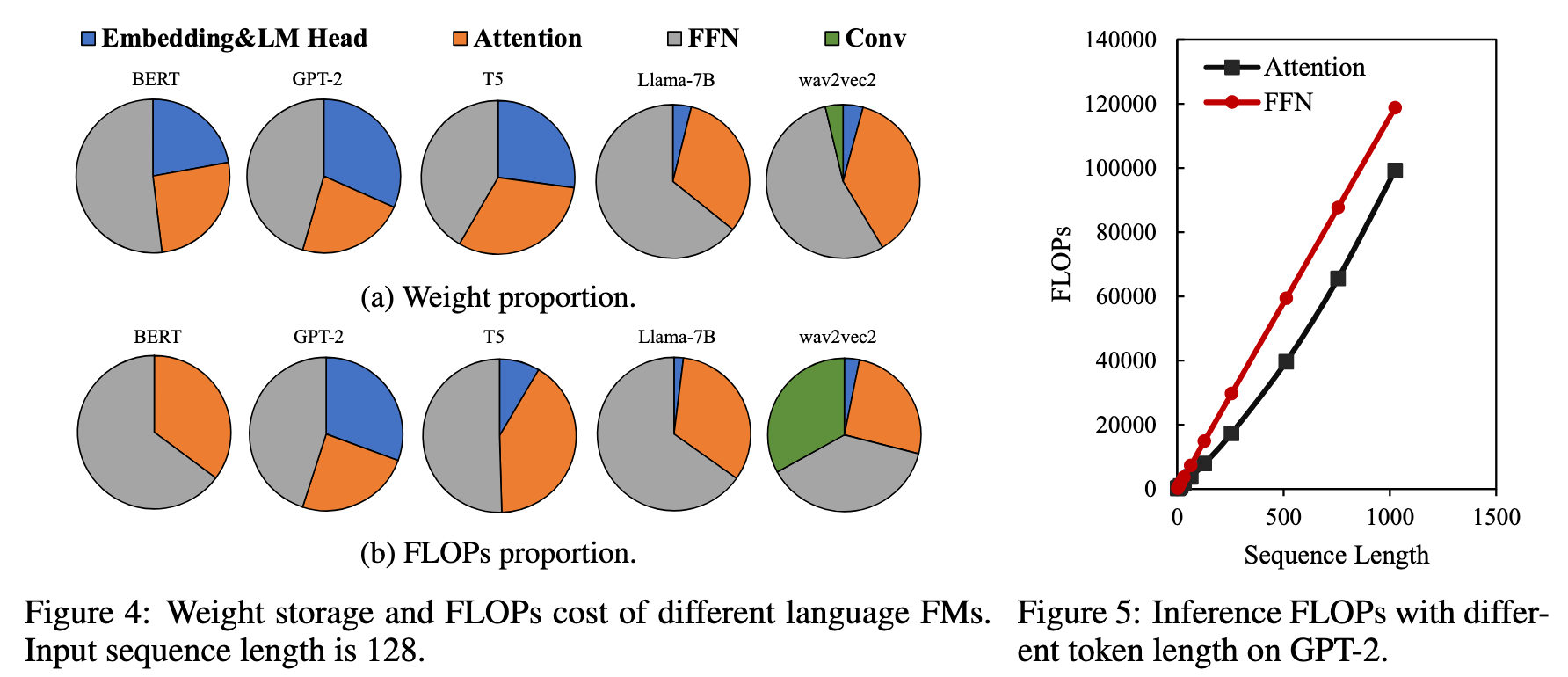
Cost Analysis of LLM
复杂度分析:
- 批处理维度为 B
- 输入序列长度为 T
- 模型隐藏层维度 D
- FFN 中间层维度 4D
Self-Attention 计算复杂度分析:
- 生成 QKV 矩阵:$O(T \times D \times D)$
- 计算注意力分数 $QK^T$: $O(T \times D \times T)$
- 对 V 进行加权求和: $O(T \times T \times D)$
所以主要部分的计算复杂度为 $O(T^2D)$
FFN 计算复杂度分析:
(m, n) @ (n, p) 相乘,计算复杂度为 $O(m \times n \times p)$
FFN 包含 W_up(D, 4D) 和 W_down(4D, D), 所以有两次矩阵乘法
H(T, 4D) = x @ W_up:$O(T \times D \times 4D)$H @ W_down: $O(T \times 4D \times D)$
所以总的时间复杂度为 $O(TD^2)$
KV Cache 的空间要求:
- Transformer 层数为 L
$B \times T \times D \times L \times 2 \times Size$
Resource-Efficient Architecture
Dynamic Neural Network
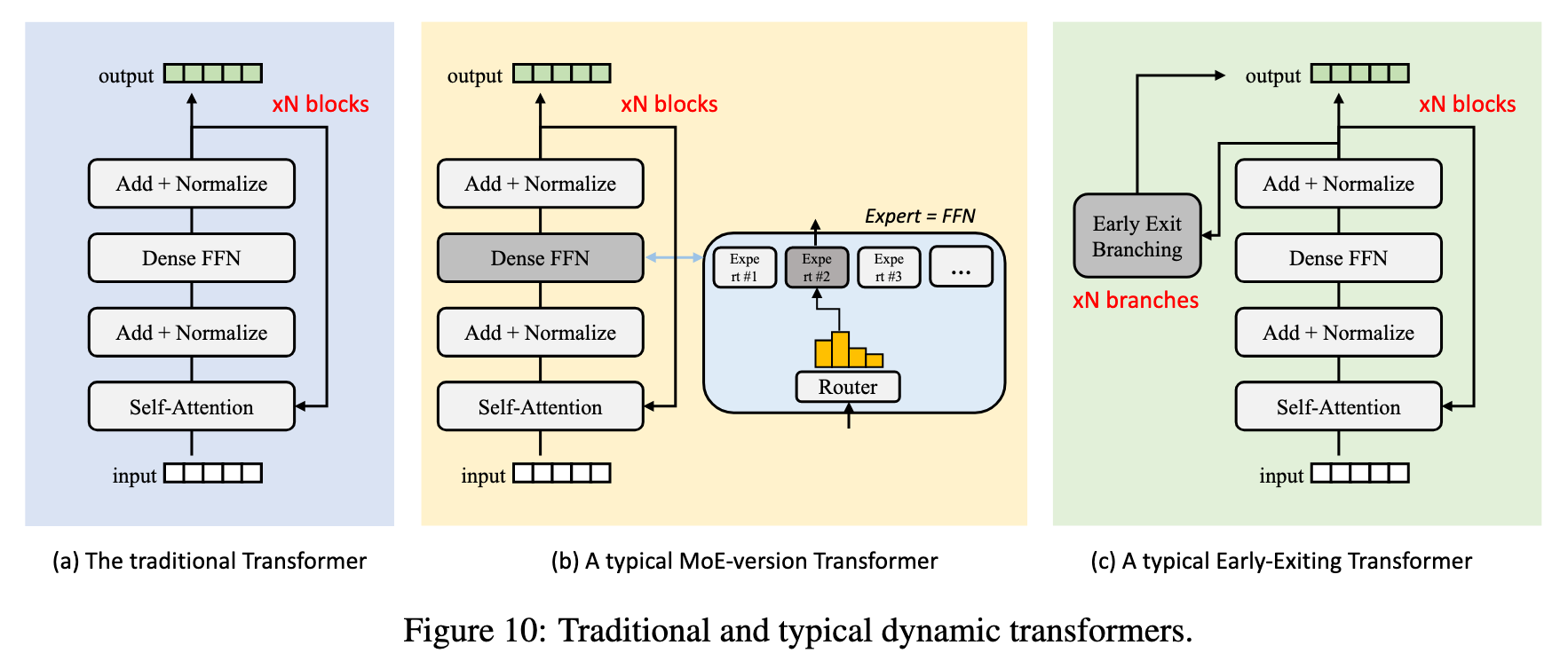
这两者都不是静态的规则,而是需要通过学习来做出智能决策的动态机制。
MoE 的 Router
- 论文中提到,MoE 模型在推理过程中利用 routed sparse parameters。这个“路由”功能由一个通常被称为“门控网络”或“路由器” 的小型神经网络来完成。
- 训练过程:路由器的作用是为每个输入的 token 决定应该由哪个“专家”网络来处理。为了做出最优决策,路由器的参数需要和专家网络的参数一起在模型训练过程中通过反向传播进行学习和优化。它的目标是学会在最小化整体损失的同时,将 token 分配给最合适的专家。
Early Exiting 的判断
- 论文指出,早退机制允许模型在对预测结果有足够信心时提前终止计算过程。
- 训练过程:为了实现这一点,通常会在模型的一些中间层额外添加小型的“内部 分类器” (internal classifiers) 或“退出头” (exiting heads) 。这些分类器需要被专门训练,以便能够基于其所在层的部分信息来尝试预测最终结果。在推理时,系统会评估这些经过训练的分类器的预测置信度,如果置信度超过预设的阈值,就会提前退出 。有些先进的方法甚至会训练一个“自适应阈值估计器”来动态决定退出时机 。
Resource-Efficient Algorithms
Inference Algorithms
Contextual Pruning 部分符合我的观察:
- Deja Vu 引入了动态预测稀疏性的机制
- PowerInfer 利用激活值的稀疏性,动态预测下一层热激活神经元并在GPU上计算,而其他冷激活神经元则在CPU上计算
- PowerInfer2 根据神经元激活和神经元簇级流水线技术动态调整计算,通过将激活的神经元分组到簇中,有效优化稀疏计算,有效降低了开销
Quantization
量化的典型流程如下:
$$ \begin{aligned} X^{\mathrm{Int}N} &= \operatorname{quantize}\!\left(N,\, X^{\mathrm{FP32}}\right) \\ &= \operatorname{Round}\!\left( \frac{2^{N}}{\operatorname{absmax}\!\left(X^{\mathrm{FP32}}\right)} \times X^{\mathrm{FP32}} \right) \\ &= \operatorname{Round}\!\left( c^{\mathrm{FP32}} \times X^{\mathrm{FP32}} \right) \\ \\[-2pt] X^{\mathrm{FP32}} &= \operatorname{dequantize}\!\left( c^{\mathrm{FP32}},\, X^{\mathrm{Int}N} \right) = \frac{X^{\mathrm{Int}N}}{c^{\mathrm{FP32}}} \end{aligned} $$这里比较核心的一个点是:为了加速计算,现代的深度学习系统(DNN引擎)在执行量化模型时,会跳过“反量化”这一步,直接用低精度的整数进行核心运算,因为专门的硬件(加速器)做整数运算比做浮点数运算快得多。
具体理论推导可以参考这里 Q-1
llama.cpp 使用的是 分块量化,即不是对整个巨大的权重矩阵使用一套统一的量化参数(即一个缩放因子 S 和一个零点 Z),而是:
- 分割矩阵:首先将一个大的权重矩阵(例如,一个 4096x4096 的矩阵)在逻辑上分割成许多个固定大小的小块 (blocks) 。
- 块的尺寸:每个小块的尺寸是 16 行 x 8 列 。这意味着每个块包含 128 个权重值。
- 独立量化:接着,它会为每一个小块独立地计算其专属的量化参数(缩放因子 S 和零点 Z),并对这个小块内的 128 个值进行量化 。
Resource-Efficient Systems
Federated Learning
联邦学习是一种在多个数据源上训练模型,同时确保数据隐私的主流方法。
简单介绍如下:
目标与动机:大型基础模型(FMs)的训练离不开海量数据。然而,在很多场景下,数据分布在不同的设备或服务器上(例如,用户的手机),并且出于隐私考虑,这些数据不能被直接上传到中央服务器进行集中训练。联邦学习的核心目标就是解决这一问题,即在不移动原始数据的情况下,协同多-方数据共同训练一个模型。
基本流程:
- 分发模型:中央服务器将一个初始模型(或模型更新指令)分发给多个客户端(如手机、边缘设备)。
- 本地训练:每个客户端利用其本地独有的数据对模型进行训练或微调。由于数据保留在本地,隐私得到了保护。
- 上传更新:客户端不上传原始数据,而是将训练产生的模型更新(如权重梯度或使用 PEFT 方法产生的少量参数)发送回中央服务器。
- 聚合更新:中央服务器聚合所有客户端上传的更新,用以改进全局模型。
- 重复迭代:重复以上步骤,直到模型收敛。
在大型模型中的应用:论文提到,联邦学习正越来越多地被用于大型模型的微调(fine-tuning)。为了解决客户端设备计算和通信资源有限的挑战,联邦学习常常与参数高效微调(PEFT)、模型分解(将大模型拆分为小模块) 等技术结合,以减少训练时间和通信成本。
PC-MoE 利用了专家激活的时间局部性:如果一个专家现在被访问了,那么它在不久的将来很可能被再次访问,提出了一个 Parameter Committee, 不去时刻准备好所有的专家,而是动态地维护一个由当前最关键、最可能被用到的专家组成的小集合。
和 PowerInfer 的思想比较类似。
Thoughts
When Reading
Skeleton-of-Thoughts: CPU 的并行能力有多少?
Update: 在我的 Mac 上测试,基本为 0 (使用的是自己实现的 gpt2-torch,后续换 llama.cpp 再试试)
Related Works
Reading List
- {5 相关} mllm: fast and lightweight multimodal LLM inference engine for mobile and edge devices
- {2 LLM 硬件加速综述} Full stack optimization of transformer inference: a survey
- {2 LLM 硬件加速综述} Hardware acceleration of llms: A comprehensive survey and comparison
- {4 Speculative Decoding} Draft & verify: Lossless large language model acceleration via self-speculative decoding
- {4 Speculative Decoding} Medusa: Simple framework for accelerating llm generation with multiple decoding heads
- {4 具体实现看一看} Skeleton-of-thought: Large language models can do parallel decoding
- {5 内存管理} vattention: Dynamic memory management for serving llms without pagedattention
- {5 PD 分离} Mooncake: A kvcache-centric disaggregated architecture for llm serving
- {3 稀疏性相关} A simple and effective pruning approach for large language models
- {4 KV 管理} Efficiently programming large language models using sglang
- {4 综述} On-device language models: A comprehensive review
- {5 边缘侧推理 IO 优化} Sti: Turbocharge nlp inference at the edge via elastic pipelining
- {5 相关} Empowering 1000 tokens/second on-device llm prefilling with mllm-npu