AI-Aided
Author Info
Background
The primary challenges identified in optimizing LLM inference in production are the combinatorial explosion of configuration parameters (parallelism strategies, batch sizes, quantization) and the diversity of inference frameworks (TensorRT-LLM, vLLM, SGLang), which makes manual tuning or exhaustive GPU benchmarking prohibitively expensive and slow.
Insights
Instead of modeling an entire neural network as a black box, the system breaks down LLM inference into fundamental, reusable operations called primitives, profile these primitives then combine the statistics to model the LLM inference process.
Challenges
Approaches
Primitive Decomposition and Offline Profiling
Inference is modeled as a sequence of specific kernels:
- Computation: GEMM (General Matrix Multiply) operations parameterized by dimensions and precision (FP16, FP8, INT8).
- Attention: Compute-bound context attention and memory-bound generation attention.
- Communication: Operations like AllReduce, AllGather, and Point-to-Point transfers.
- Memory: Data movement and cache operations.
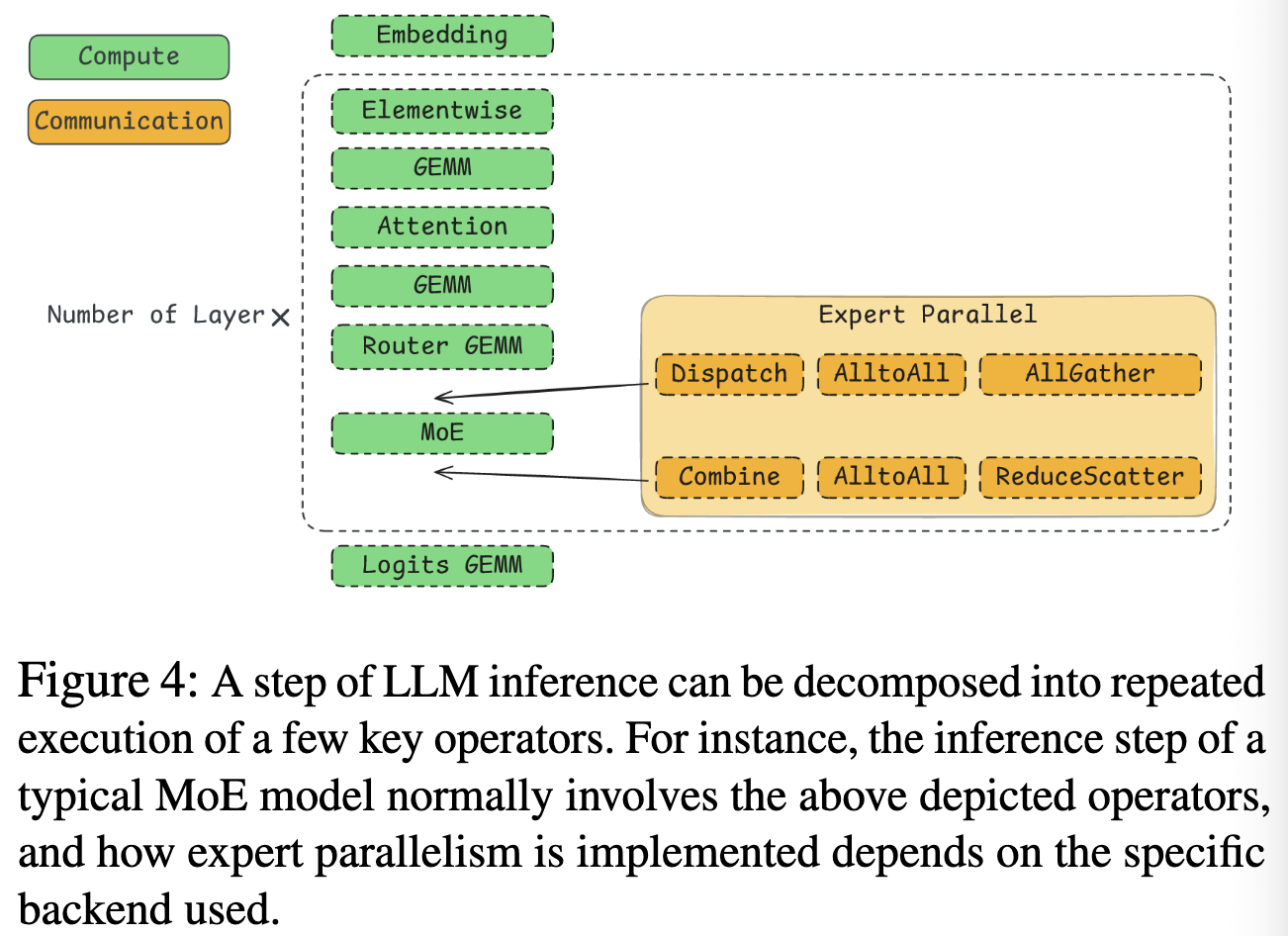
Performance Database (PerfDatabase): The system builds a hardware-specific database by profiling these primitives once on target hardware (e.g., NVIDIA H100).
For configurations not explicitly profiled, it uses interpolation or theoretical roofline models (Speed-of-Light estimation) to predict latency.
Simulation and Performance Modeling
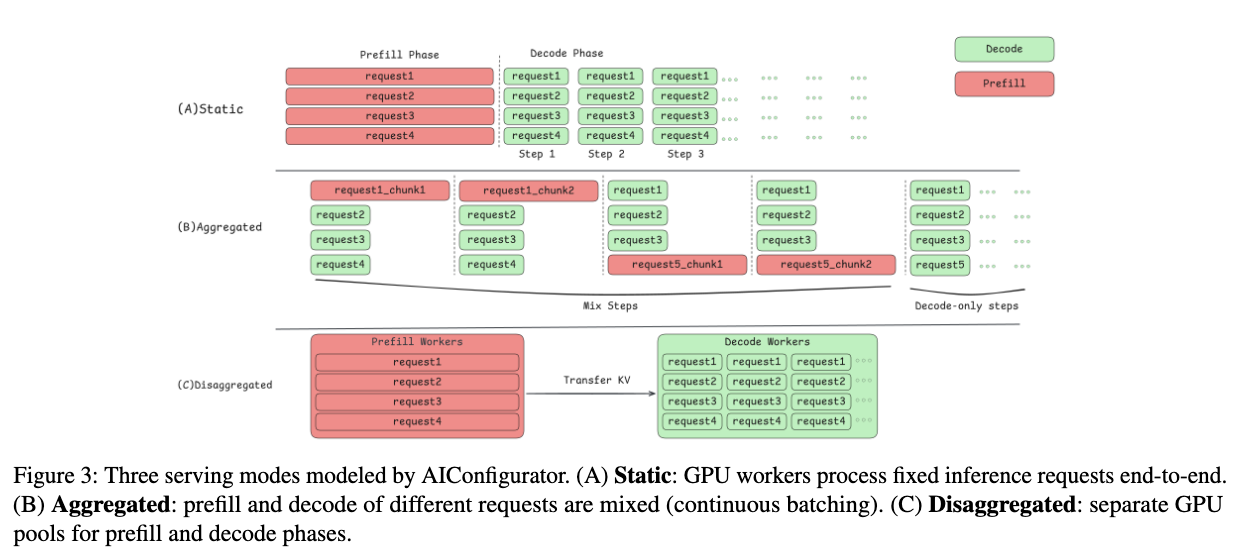
The system uses the database to reconstruct end-to-end performance estimates. It explicitly models three distinct serving modes to capture complex runtime behaviors:
- Static Mode: Models sequential processing with fixed batch sizes. This serves as a baseline where Time-To-First-Token (TTFT) equals prefill latency, and Time-Per-Output-Token (TPOT) is the average decode step latency.
- Aggregated Mode (Continuous Batching): Models modern engines that mix prefill and decode phases within the same iteration. The algorithm accounts for resource contention and uses a rate-matching heuristic to throttle decode requests if the prefill phase dominates, preventing “starvation” of new requests.
- Disaggregated Mode: Models architectures where prefill and decode occur on separate GPU pools. The model calculates the optimal ratio of prefill-to-decode workers and explicitly accounts for the network overhead required to transfer the KV cache between nodes.
Automated Search and Generation
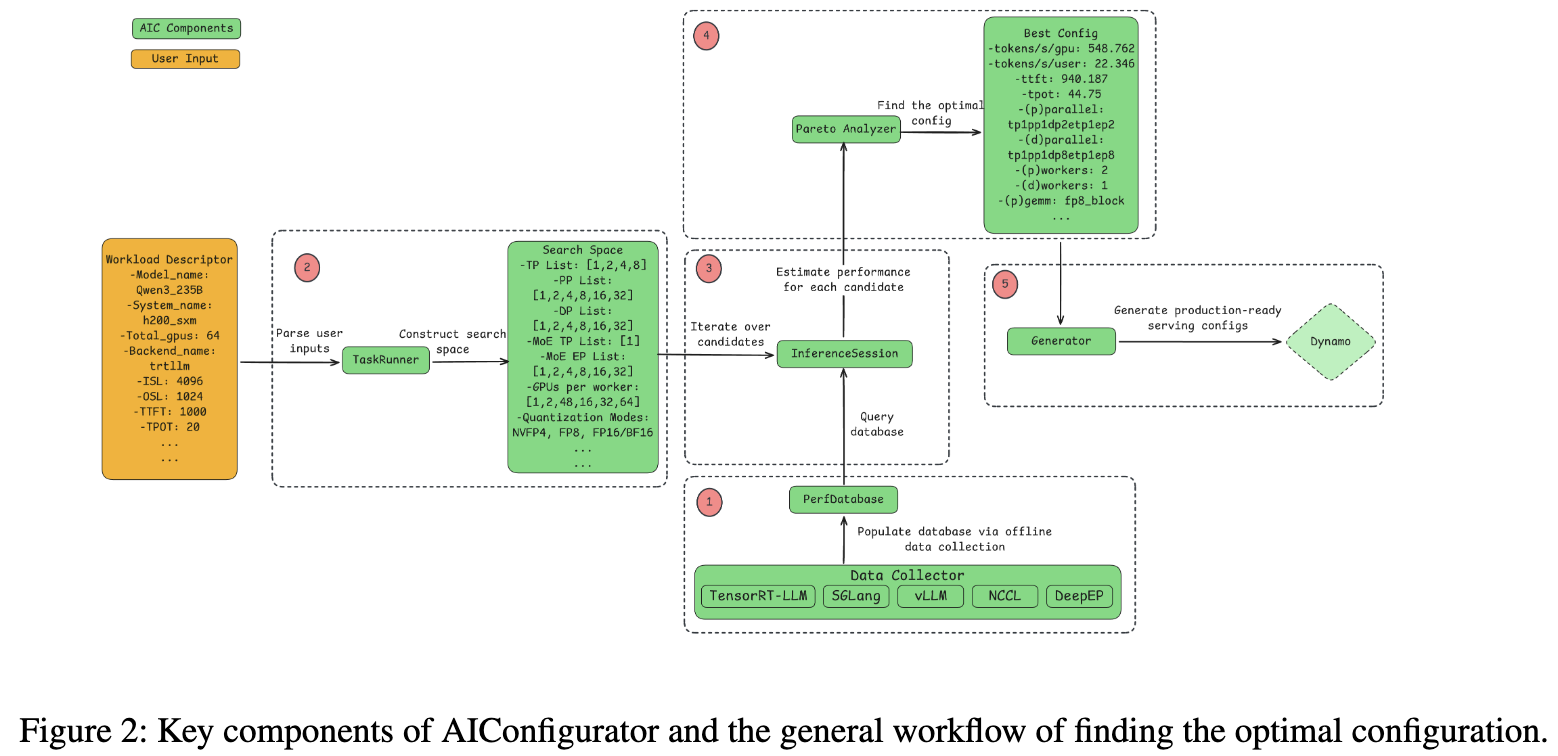
The optimization process follows a multi-step workflow:
- TaskRunner: Constructs a valid search space based on user constraints (e.g., TTFT < 100ms) and hardware availability.
- InferenceSession: Iterates through candidate configurations (varying tensor parallelism, pipeline parallelism, expert parallelism), querying the database to estimate performance for each.
- Pareto Analyzer: Ranks configurations to find the optimal trade-off between system throughput (tokens/second/GPU) and generation speed (tokens/second/user).
- Generator: Automatically translates the theoretical optimal configuration into framework-specific launch flags (e.g., setting
--enable_cuda_graphor specific memory fractions) for the target engine (TRT-LLM, vLLM, etc.).
Evaluation
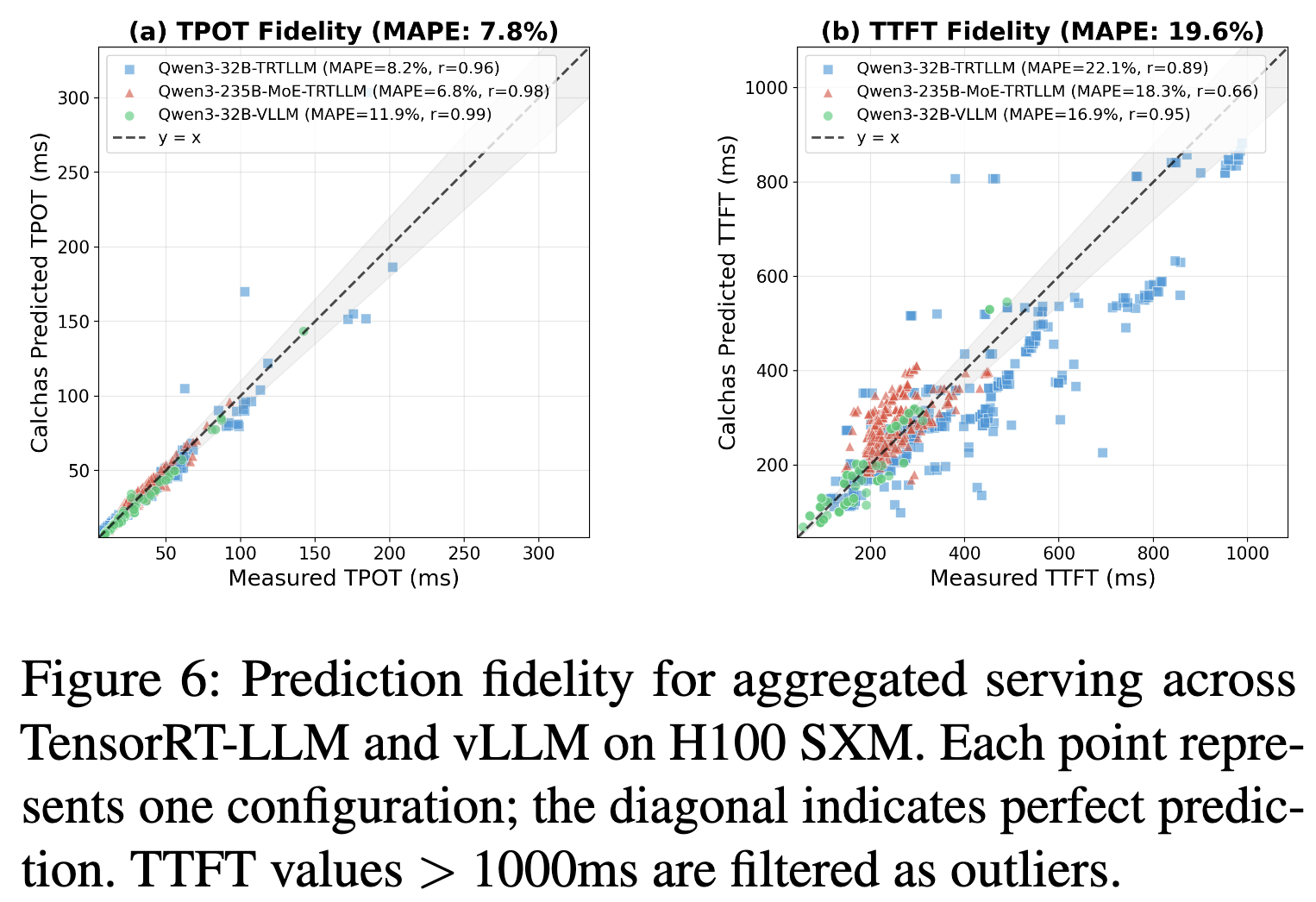
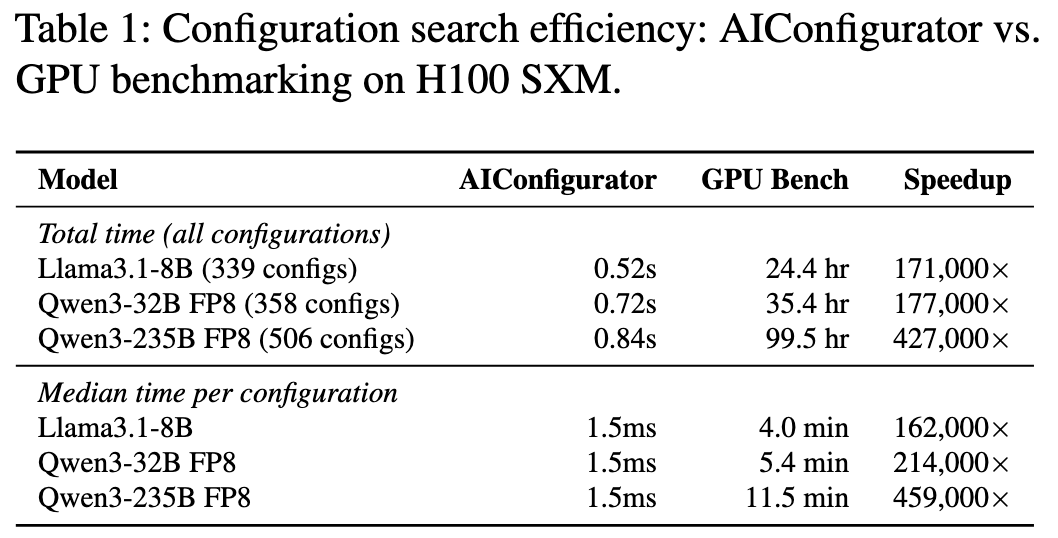
- Accuracy: The approach achieves high fidelity (low error rates compared to ground truth) by accounting for complex behaviors like expert load imbalance and network overhead in disaggregated setups.
- Speed: The simulation-based search is significantly faster.