Extensive Reading
Author Info
Background
Quantization is vital for running LLM on edge devices.
Challenges
- Quantization-aware training (QAT) is not efficient due to the high training cost.
- Post-training quantization (PTQ) suffers from large accuracy degradation under a low-bit setting.
Insights
- Not all weights in an LLM are equally important.
- Protecting only 1% salient weights can greatly reduce quantization error.
- To identify salient weight channels, we should refer to the activation distribution, not weights.
- Mixed-precision format is not hardware-efficient, we can employ activation-aware scaling.
Approaches
Activation-aware Weight Quantization
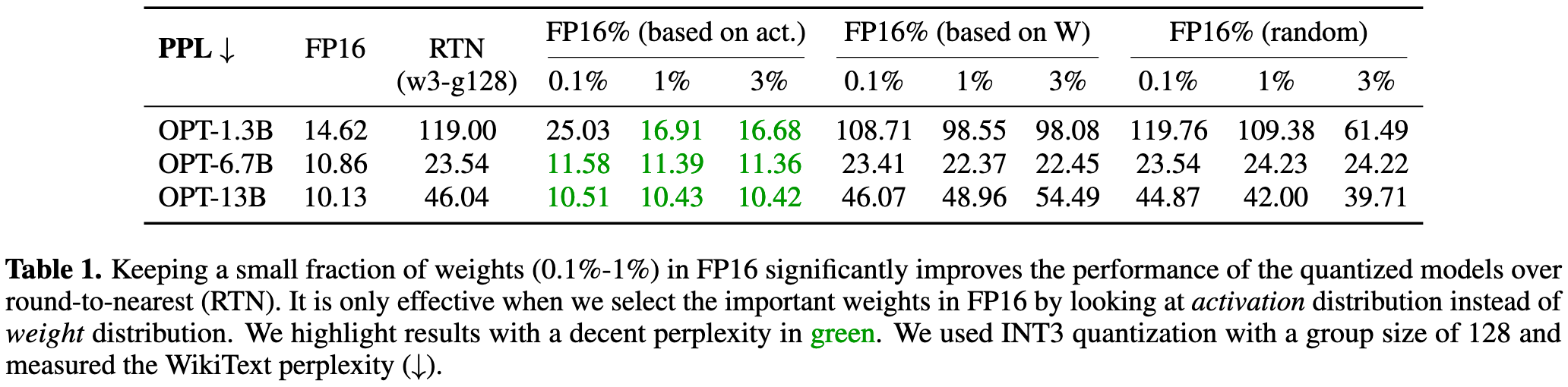
直接使用 round-to-nearest(RTN) 量化方法会导致 PPL 指标增大,作者分别使用三种策略来保留部分权重为 FP16 格式:随机,根据权重矩阵,根据激活值大小。
实验发现根据激活值大小策略效果最好,所以提出了假设:the input features with larger magnitudes are generally more important.
论文中将这种权重称为 salient weights.
直接保留 FP16 格式的 salient weights 无疑是最直接的,但这种精度混合格式对硬件并不友好,所以 AWQ 提出了通过 per-channel scaling 来保护 salient weights.
这部分的核心思想是:通过在量化前“放大”重要的权重,可以有效减小它在量化过程中产生的误差。
论文中进行了简单的公式推导,得到的结论是:将权重 $w$ 放大 $s$ 倍,成功地将其量化误差缩小了约 $s$ 倍。
理解这部分推导最重要的地方是区别 channel 和 group 两个概念
- Channel: 逻辑概念,与模型的网络结构有关。在权重矩阵
W(维度为输入特征数 x 输出特征数)中,一个输入通道就对应矩阵的一整列。 - Group: 这是一个量化实现上的概念,与权重的物理存储顺序有关。分组量化时,系统会将整个2D的权重矩阵“铺平”成一个1D的长条,然后将这个长条切成固定大小的块,每块就是一个“组”(例如,每128个权重一个组)。
与其手动指定一个固定的缩放比例(比如 s=2),不如设计一种方法来自动地、为每一个权重通道(channel)找到一个最优的缩放比例,从而让整个模型的量化误差最小。
AWQ 将这个问题形式化为一个优化的问题:找到一组缩放因子 s(每个输入通道对应一个),使得“权重乘以 s 再量化,然后输入除以 s ”这一系列操作之后得到的结果,与原始的、未经量化的结果之间的差距最小。
直接求解很困难,但是我们可以简化 $s$ 的范围:
$$s = {s_X}^{\alpha}$$- $s_X$:每个通道激活值的平均大小。这个值可以从一小部分校准数据中提前统计出来。
- $\alpha$ :一个介于 0 和 1 之间的超参数。
至此,寻找 $s$ 的问题可以简化为寻找一个全局的超参数 $\alpha$。
TinyChat
4.1 小节的实验结论也很有参考性。
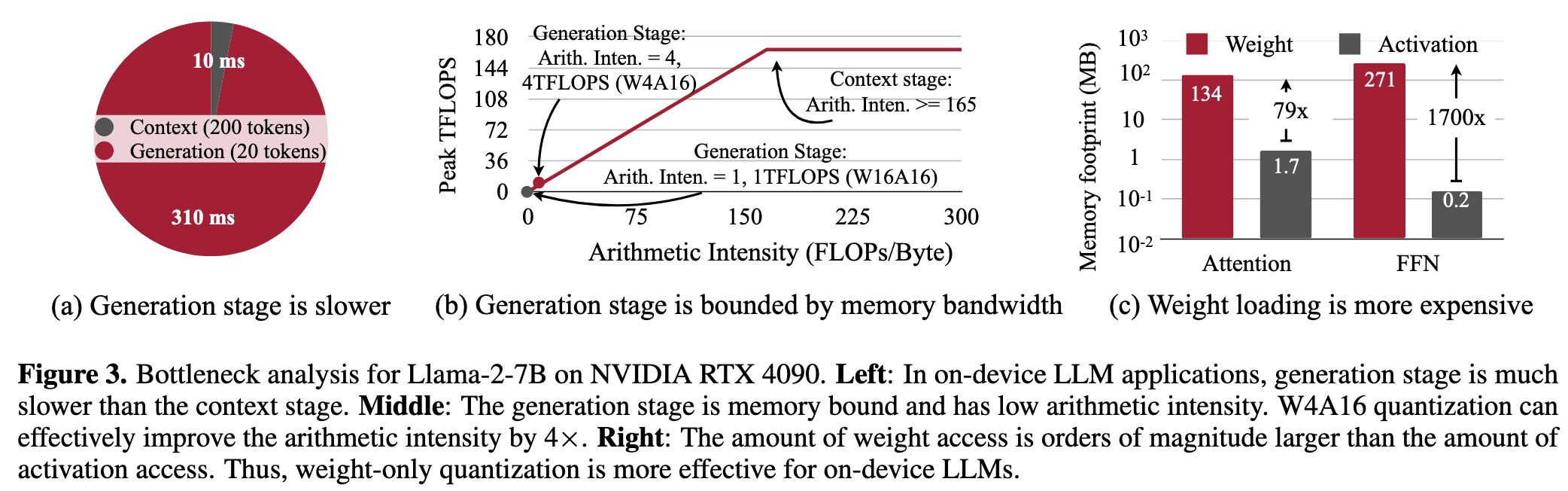
- The generation phase is substantially slower than the context stage.
- The generation phase is memory-bounded (pretty small arithmetic intensity)
- Weight access dominates the memory traffic for on-device LLMs.
- Quantizing the model weights to 4 bit integers will approximately increase the arithmetic intensity to 4 FLOPs/Byte.
论文还开发了一个名为 TinyChat 的高效推理框架,通过以下关键技术实现了显著加速:
- On-the-fly dequantization:在计算过程中,将 4 位权重实时地恢复到 16 位浮点数,并与矩阵乘法等计算操作融合,避免了将反量化后的权重写回内存,减少了访存开销。
- Kernel fusion:将多个独立的操作(如注意力计算中的 QKV 投影、层归一化等)融合成一个单一的计算核心,大大减少了 GPU 核心的启动开销,这对于延迟极低的操作尤为重要。
- SIMD-aware weight packing:针对 CPU 等具有 SIMD 架构的设备,设计了特定的权重打包和重排方式,使得在运行时可以利用 SIMD 指令高效地解包权重,进一步提升反量化速度。
Evaluation
效果好,通用性强!
Thoughts
When Reading
第三章整体的逻辑很清晰:
- Selecting weights based on activation magnitude can significantly improve the performance despite keeping only 0.1%-1% of the channels in FP16.(&3.1)
- But mixed-precision format is not hardware-efficient.
- Instead of preserving the salient weights in FP16, we can employ activation-aware scaling. (&3.2)
- Instead of manually specifying a fixed scaling factor (e.g., s=2), a method should be designed to automatically find an optimal scaling factor for each weight channel, thereby minimizing the overall model’s quantization error. (&3.3)
看完之后的感受:Simple but effective!