Extensive Reading
Author Info
Background
- Existing “Self-Speculative Decoding” (SSD) methods are easy to use (training-free) but often slower than methods that rely on training specialized draft models.
- “Cascade Speculative Decoding” (using a hierarchy of draft models) offers high speed but is impractical because it requires training and maintaining multiple draft models.
Insights
The paper proposes Cascade Adaptive Self-Speculative Decoding (CAS-Spec).
This framework constructs a “virtual” hierarchy of draft models directly from the target model itself, without needing extra training. It effectively combines
- the convenience of self-speculation
- the high performance of cascade decoding.
Challenges
- Can existing training-free self-speculative decoding methods be used to construct an effective cascade of draft models above retrieval-based methods for on-the-fly speculative decoding?
- Can we achieve further speedup by adaptively routing the draft models and assigning the draft lengths, with regards to the characteristics of different DSIA strategies?
Approaches
EWIF
The basic formula for EWIF (denoted as $T$) typically looks like this:
$$EWIF = \frac{\text{Expected Number of Generated Tokens}}{\text{Total Cost of Drafting and Verification}}$$In the paper, it is formalized as:
$$T = \frac{1 - \alpha^{K+1}}{(1 - \alpha)(c \cdot K + 1)}$$Where:
- $\alpha$ (Alpha): The Acceptance Rate. It represents the probability that the Target Model accepts a token generated by the Draft Model.
- High $\alpha$ $\rightarrow$ High EWIF (Good).
- $c$ (Cost Coefficient): The relative cost of the Draft Model compared to the Target Model.
- $c \approx \frac{\text{Time for Draft Model}}{\text{Time for Target Model}}$
- Low $c$ $\rightarrow$ High EWIF (Good).
- $K$: The number of draft tokens generated in one step.
分子是等比数列求和:
$$E = \frac{1 \cdot (1 - \alpha^{K+1})}{1 - \alpha} = \frac{1 - \alpha^{K+1}}{1 - \alpha}$$分母是本次操作消耗的归一化时间:$c \cdot K + 1$
DSIA
Dynamically Switchable Inference Acceleration (DSIA): These are techniques that can be toggled during inference to trade accuracy for speed. By applying different DSIA configurations, the system creates a hierarchy of draft models ($\mathcal{M}_{d_{1}}, \mathcal{M}_{d_{2}}, \dots$).
- Layer Sparsity: Skipping a subset of transformer layers or blocks to generate tokens faster.
- Activation Quantization: Using lower precision (e.g., INT4) for activations and KV caches during draft generation.
- Early-Exiting: Using predictions from intermediate layers.
- Bottom Draft Model: The hierarchy typically ends with a “base” draft model that is extremely fast and computationally negligible, such as Prompt Lookup Decoding (PLD).
- Intuition: In several LLM use cases where you’re doing input grounded generation (summarization, document QA, multi-turn chat, code editing), there is high n-gram overlap between LLM input (prompt) and LLM output. This could be entity names, phrases, or code chunks that the LLM directly copies from the input while generating the output. Prompt lookup exploits this pattern to speed up autoregressive decoding in LLMs.
- Methods: Replace the draft model with simple string matching in the prompt to generate candidate token sequences.
Cascade Strategies: The paper outlines three ways to combine these strategies into a hierarchy:
- Mixing-DSIA: Combining orthogonal strategies (e.g., Layer Sparsity + Activation Sparsity).
- Replacing-DSIA: Switching between conflicting strategies (e.g., different attention mechanisms).
- Scaling-DSIA: Using the same strategy with different intensities (e.g., different degrees of sparsity).
- Vertical Cascade: 小模型给中模型打草稿,中模型给大模型打草稿
- Horizontal Cascade: 在生成同一个草稿序列的过程中,混合使用不同质量的模型
- 在投机采样中,前面的token比后面的token更重要(因为一旦前面的错了,后面的全都要作废)。因此,水平级联策略是前几个 token 用质量较好的模型,后几个 token 用质量较差的模型
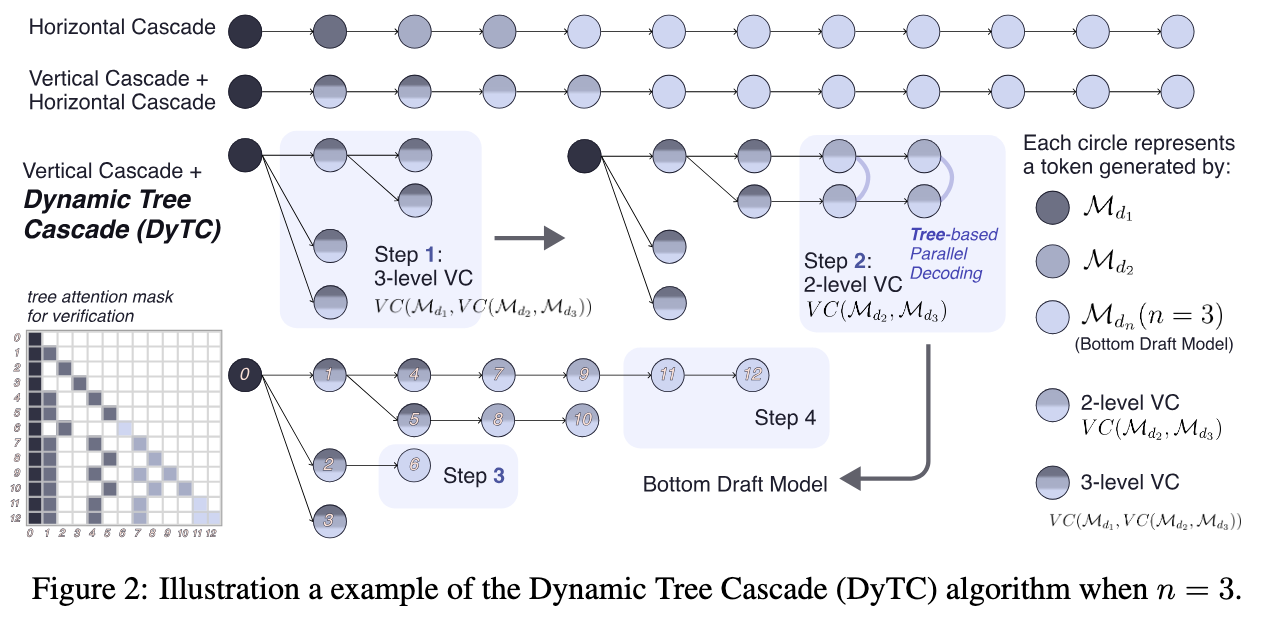
Dynamic Tree Cascade (DyTC) Algorithm
Since there are multiple “virtual” draft models available, the system needs a smart way to decide which model to use and how many tokens to generate at any given step. The DyTC algorithm handles this scheduling.
DyTC dynamically selects the optimal draft model and draft length based on real-time heuristics rather than fixed schedules. It aims to maximize the “Expected Walltime Improvement Factor” (EWIF).
Key heuristics:
Acceptance Rate Estimation: It tracks the acceptance rate ($\alpha$) of each draft configuration using an Exponential Moving Average (EMA) to adapt to changing generation contexts
Hardware-Aware Latency Prediction: It estimates the cost (latency) of each DSIA strategy using a regression model based on the hardware’s roofline performance.
统计学中处理时间序列数据的方法,核心逻辑是 “越新的数据,权重越大;越旧的数据,影响越小”
Instead of a single sequence, DyTC constructs a draft token tree:
- It expands the tree by selecting the “leaf” node with the highest accumulated acceptance probability (using acceptance rate)
- It uses Tree Attention to verify multiple branches in parallel, increasing the chance of accepting a longer sequence of tokens
在构建 Attention Tree 时
- 使用 Acceptance Rate Estimation 来寻找扩展点和计算 EWIF 的分子部分
- 使用 Hardware-Aware Latency Prediction 计算 EWIF 的分母部分
- Vertical Cascade 可以用于构建树的不同分支
- Horizontal Cascade 可以用于构建同一个分支的不同 token
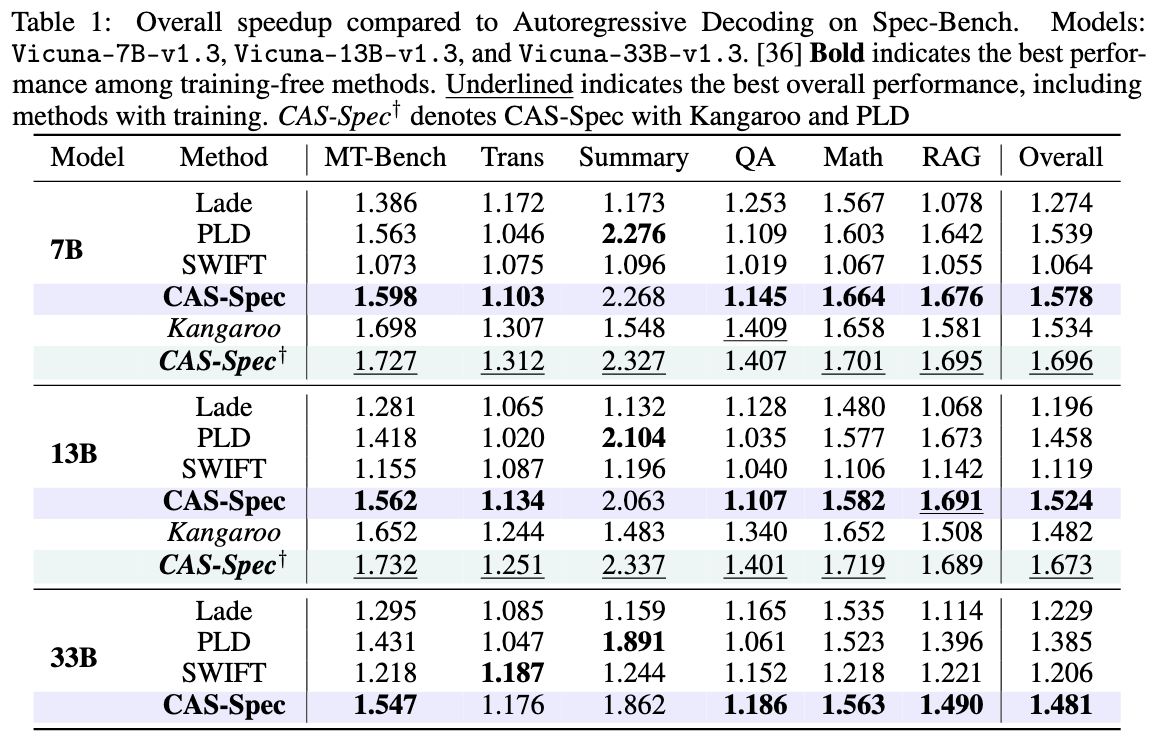
Evaluation