Extensive Reading
在 axriv 或者其他论文中的引用经常是另一个名字:LLMCad
Author Info
- Daliang Xu (徐大亮) - Daliang Xu’s Website
- Wangsong Yin - Google Scholar
- Xin Jin
- Mengwei Xu
- Professor Xuanzhe Liu @ Peking University
Background
The Scaling Law vs. The Memory Wall: The machine learning community has shown that increasing an LLM’s parameter size consistently improves its accuracy and can lead to new, emergent abilities. However, this “scaling law” is challenged on mobile devices by a “memory wall”. When an LLM is too large to fit into a device’s memory, inference latency increases dramatically, by as much as 59-224x.
The I/O Bottleneck: This latency explosion occurs because current mobile deep learning engines must repeatedly load model weights from disk into memory when memory capacity is exceeded. A performance breakdown reveals that for large models, this disk I/O can account for over 95% of the total inference time. Traditional optimizations like pipelining are rendered ineffective by this I/O bottleneck.
Speculative Decoding: The paper’s approach is built upon speculative decoding, a technique that uses two models to accelerate inference.
- A smaller, memory-resident draft LLM acts as a token generator.
- A larger, more accurate target LLM acts as a verifier, inspecting the tokens generated by the draft model.
Principles of Speculative Decoding: This method is effective for two main reasons:
- Draft Model Accuracy: Smaller draft models can often generate the correct token, with experiments showing correctness rates between 80% and 91% when compared to the target model’s output.
- Non-Autoregressive Verification (NAV): The target LLM can verify an entire sequence of tokens in parallel during a single inference pass. This NAV process is significantly faster—up to 8.5-9.9x—than having the target LLM generate the tokens one by one, as it requires only a single instance of loading the model’s weights from disk.
Challenges
Applying speculative decoding for on-device LLM introduces three distinctive challenges:
- 更宽的 token tree 有更大的几率包含更多的正确 token,但是这也会加重 draft LLM 的计算负担
- 什么时候去触发对资源消耗比较大的 verification 很关键,早了没必要,晚了会延迟 correct token 的生成
- target LLM 进行 verification 时,I/O becomes bottleneck while processors stay idle, which causes severe hardware resources waste
Insights
针对上述各个问题,EdgeLLM 提出了对应的 insights:
- Token tree 可以是动态的,具有更高置信度的 branch 应该被探索地更深
- 可以综合整个 token tree 的全局不确定性,更准确地 assess the risk of generation errors
- 阈值也可以动态调整:如果 draft model 近期表现良好,就应该更信任它;如果错误较多,就应该更频繁地进行验证
- 在 target model 进行验证时(I/O 加载的过程中),draft model can use the idle computation sources to provisionally generate next tokens
Approaches
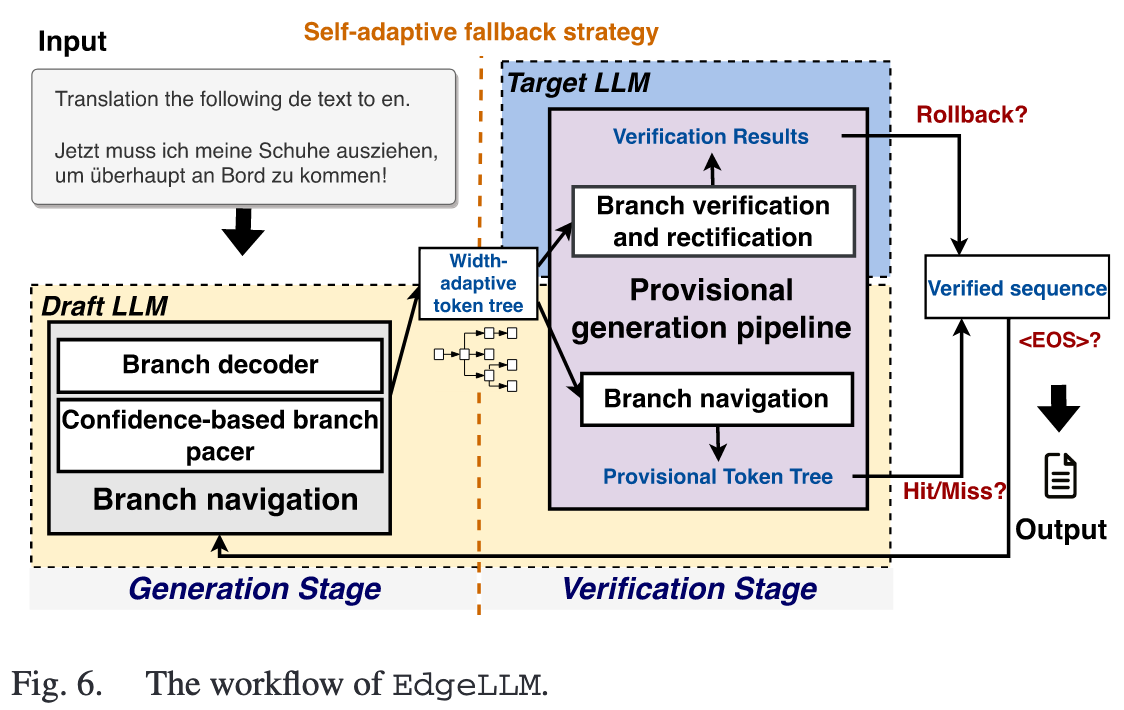
Compute-Efficient Branch Navigation and Verification
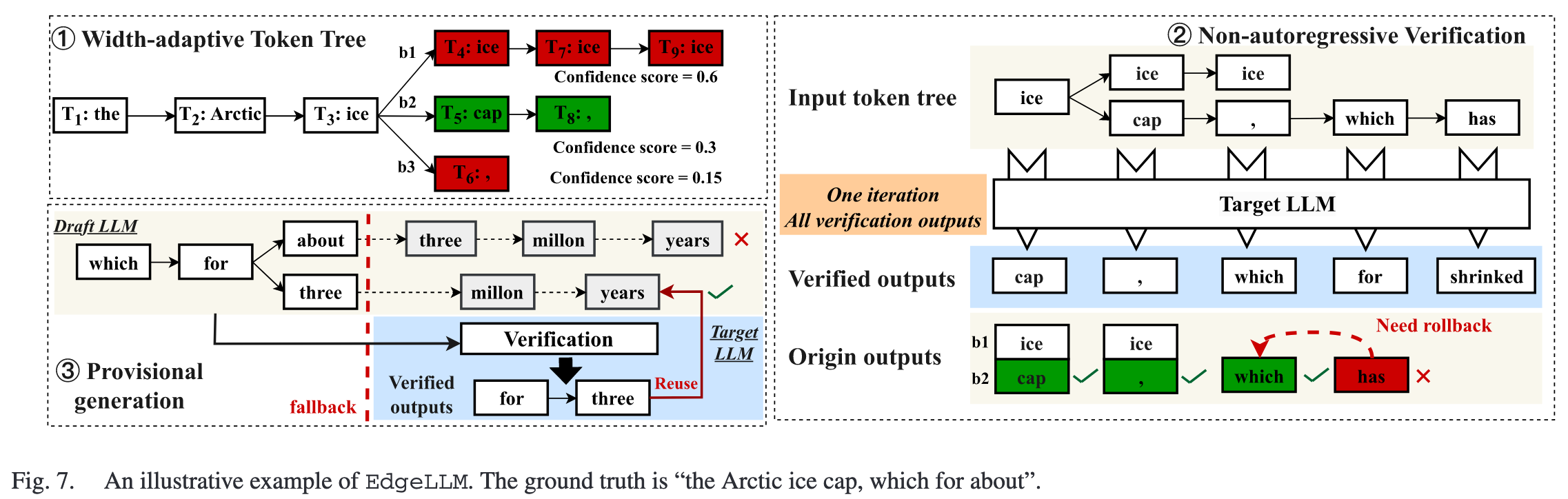
Width-adaptive Token Tree: EdgeLLM 会根据每个分支(即候选序列)的置信度得分,动态地调整其深度和宽度 。置信度高的分支会被探索得更深,从而将有限的计算资源优先分配给最有可能正确的生成路径 。
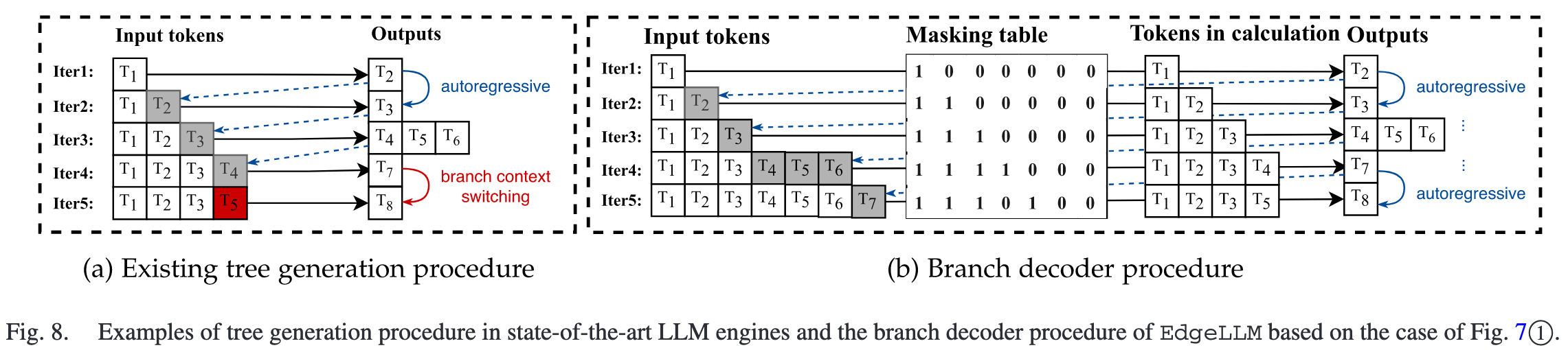
Branch Decoder: 在生成不同分支时,传统方法需要频繁地切换上下文,这部分的额外开销不可忽略,EdgeLLM 通过掩码技术来模拟上下文切换,在一次前向传播中为不同分支计算结果。
比如在 Fig.8 的 iter4 -> iter5 过程中,需要切换 KV Cache 的状态,开销较大
EdgeLLM 利用了 self-attention 计算过程中的 causal mask,将不属于该 branch 的 token 遮蔽,达到切换上下文的效果
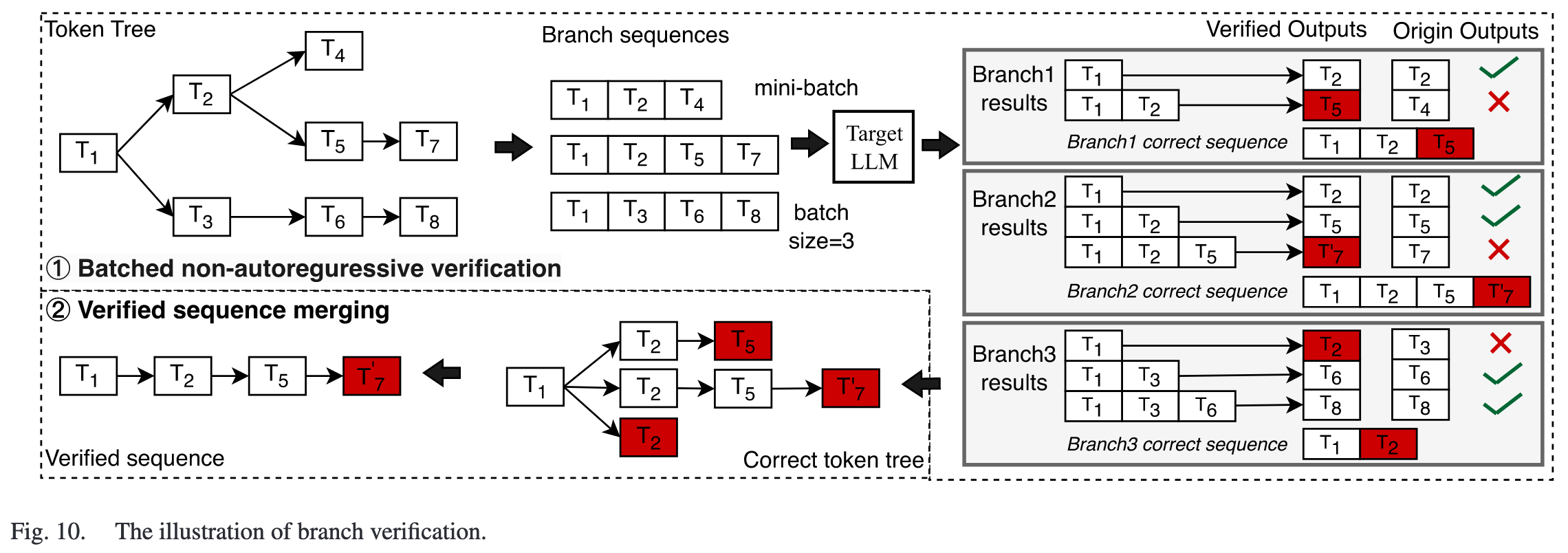
- Batched Non-autoregressive Verification: 将 token tree 分解为多个 sequence,打包为一个 mini-batch 传入 target model 中进行验证。
相当于,token tree 的不同 branch 可以并行验证,每个 branch 的不同 generated token 也能并行验证
后者的并行验证涉及到 speculative decoding 的基本机制:
- 将 draft model 生成的整个分支序列
D = [d_1, d_2, ..., d_n]输入给 target model - 在经历一次前向传播之后,会输出一个形状为
[1, n, vocab_size]的Logits张量,系统会利用这个 logits 张量,在每个位置上都进行一次贪心解码来得到一个正确答案序列G = [g_2, g_3, ..., g_n]- 在位置1,系统查看
logits[0, 1, :],并取概率最高的词元,作为给定d_1后的正确下一词g_2 - 在位置2,系统查看
logits[0, 2, :],并取概率最高的词元,作为给定d_1, d_2后的正确下一词g_3
- 在位置1,系统查看
- 将草稿序列
D和正确答案序列G进行比较,直到找到第一个不匹配的位置
Self-Adaptive Fallback Strategy
决策指标采用 Tree-cumulative confidence, 综合了整个 token tree 的全局不确定性,更准确地 assess the risk of generation errors.
以及一个自适应的阈值:如果 draft model 近期表现良好(错误少),系统会降低阈值(更信任它);反之,如果错误较多,则提高阈值,进行更频繁的验证。
Provisional Generation Pipeline
When target model is validating,cpu resources stay idle most of the time(I/O bound).
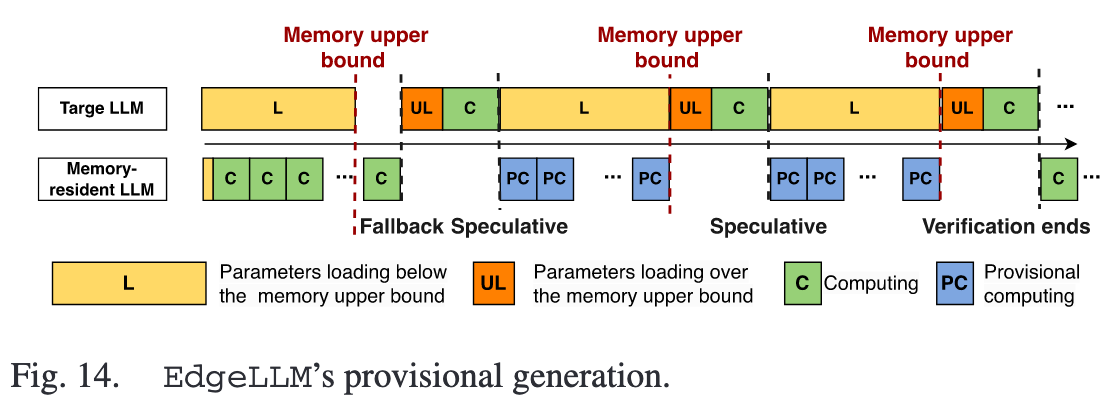
target model 和 draft model 在 inference 时用的资源不同,所以在 target model 验证时,可以假设当前的序列有效,基于当前令牌树中最可信的那个分支,见缝插针地进行 provisional generation
- 如果验证通过,那么 provisional generation 得到序列可以直接加入新的 token tree 中
- 如果验证不通过,则直接丢弃这部分中间结果就行