Extensive Reading
Author Info
- Rongjie Yi - Google Scholar
- Homepage - Liwei Guo / Assistant Professor: a tenure-track Assistant Professor at University of UESTC.
- Mengwei Xu
Background
Challenges
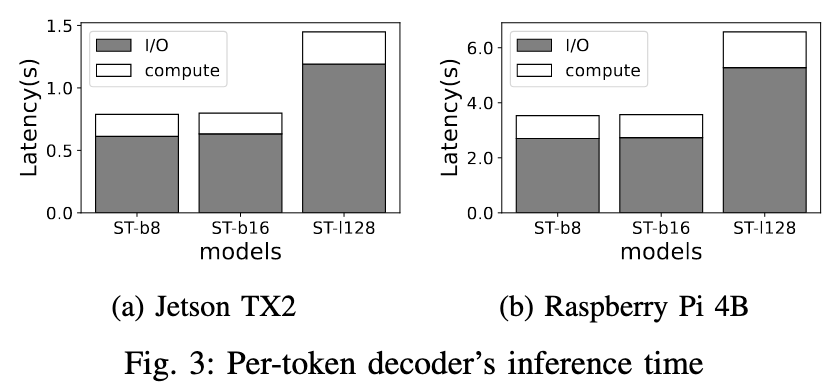
- End-to-end latency is I/O-dominated because expert weights are loaded on demand from slow storage (tail delay inflation).
- Quantization trilemma: compress aggressively, preserve accuracy, and keep dequantization nearly free on low-power CPUs/NPUs.
- Dynamic routing obscures which experts will be needed, making prefetch hard and naive caching ineffective when activations are balanced.
- Tiny RAM budgets (~1.5–3 GB) constrain the expert buffer, demanding careful eviction to avoid thrashing.
- Hardware heterogeneity and variable storage speeds complicate a one-size-fits-all pipeline and bitwidth plan.
Insights
Non-expert weights are held in device memory; while expert weights are held on external storage and fetched to memory only when activated.
- Motivated by a key observation that expert weights are bulky but infrequently used due to sparse activation
Designs:
- Expert-wise bitwidth adaptation: 不同专家对压缩的容忍度不同,容忍度高的专家可以使用更激进的量化
- In-memory expert management: 虽然单层中的专家激活频率接近均衡,但是对于同一个 Token,跨所有层被激活的专家序列呈现幂律分布 – 也就是说根据当前路径中已经被激活的两个专家,可以有很大概率成功预测下一个激活的专家是哪个,所以也能很自然地使用 predict-then-prefetch 的流水线机制
顺便也总结一下论文提到的几个重要观察:
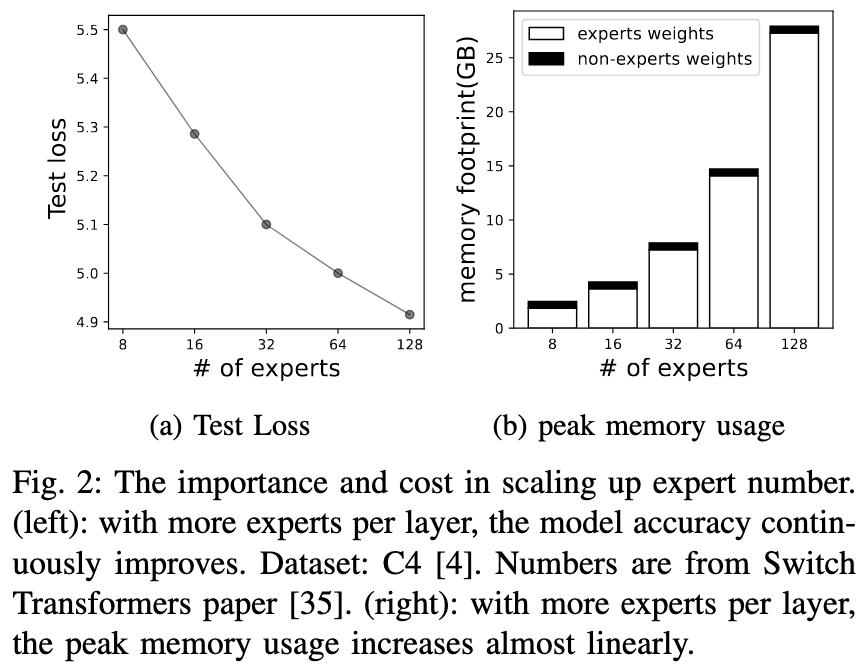
- Expert weights bloat device memory
- Experts weights are bulky but cold
- Expert activation path follows power law distribution
The experts in the same layer have a similar chance to be activated.
The 20% most frequently activated paths contribute to more than 99% of the activation cases of all tokens.
我还是有点迷惑这两者的区别是什么
Approaches
It permanently hosts all hot weights in memory since they are used per-token inference; while the rest of the memory budget is used as an expert buffer for the cold expert weights.
Expert-wise Quantization
使用的是比较基础的 Channel-wise linear quantization
- 先逐个把专家压到低比特(如INT2),测整体精度下降作为该专家重要性的反向指标,形成专家敏感度排序
- 把所有 Expert 应用一个基础量化水平
- 然后从最不重要的 K 个专家开始下调压缩比特,并反复验证精度,直到达到用户可容忍的精度损失 P
- 离线阶段需要迭代枚举各种位宽配置并动态调整专家分配,直到模型的精度下降满足阈值
- 在线推理阶段直接使用调整好的配置即可
In-memory Expert Management
Given the prior knowledge of expert activations of 0..n − 1 layers, we can estimate the activation probability of each expert at n−th layer with good confidence.
- 根据离线 Profiling 结果形成一个字典:Key 为前面两层激活的专家,Value 为预测下一层会激活的专家
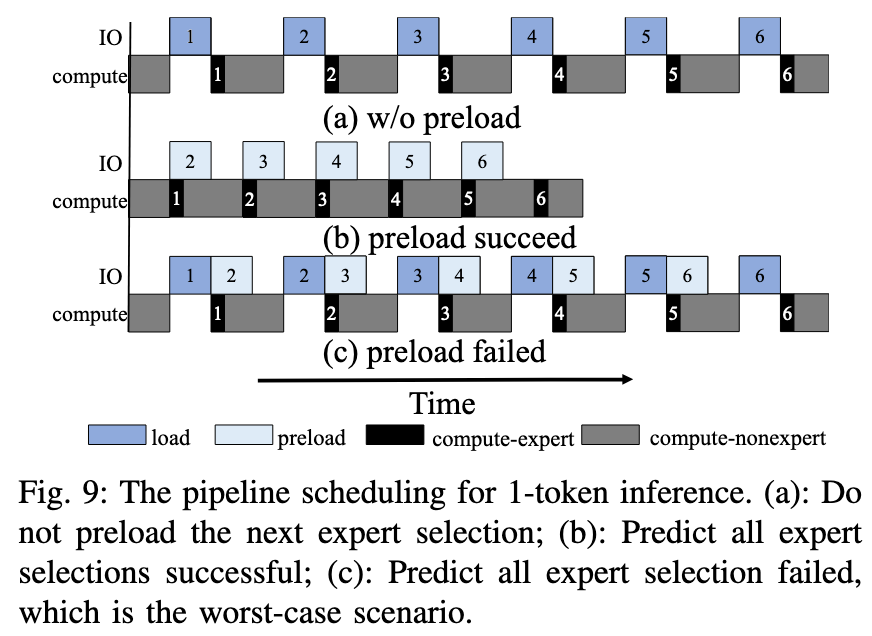
- 推理时采用在线预测与预取的 pipeline: 按概率从高到低预取1–3个最可能专家到缓存,与当前层计算并行;若预测命中,I/O得到隐藏;若失误,回退按需加载
- 在内存中维护一个专家缓存,利用两类信号联合打分:
- 历史激活频率
- 层位置距离(离当前执行近的优先保留)
Evaluation
Thoughts
When Reading
提出"暴论": 所有需要离线 Profiling 的工作都应该由 LLM 厂家在训练时实现。
和 LLM as a System Service on Mobile Devices 有点类似,都是利用了某个组件的 Compression-Tolerance 的不同,把容忍度高的进行更激进的量化,把容忍度低的部分进行更保守的量化:
- MoE 中的不同 Expert
- KV Cache 中的不同 KV Chunk
但是相比于 LLMS 根据注意力分数去压缩 KV Chunk,EdgeMoE 的操作就太直白(暴力)了