Background
传统的LLM部署方式主要有两种:
- 云端部署:将模型完全部署在云服务器上。这种方式虽然计算能力强,但会带来较高的网络延迟、带宽成本,并可能引发用户数据隐私泄露的风险 。
- 边缘端部署:将模型直接部署在靠近用户的边缘设备上。这种方式可以有效解决延迟和隐私问题,但边缘设备(如手机、物联网网关)的计算和内存资源非常有限,难以承载动辄数十亿参数的LLM 。
现有的解决方案,如模型量化(压缩模型)会造成精度损失 ,而简单的云-边协同(将模型切分两部分)仍然严重依赖与云端的高质量连接 。
论文首次提出了一种名为EdgeShard 的通用LLM推理框架,旨在利用协同边缘计算(Collaborative Edge Computing, CEC)环境 。该环境整合了地理上分布的、异构的多个边缘设备和云服务器的计算资源,形成一个共享资源池 ,共同执行LLM推理任务。
Core Insights
EdgeShard 将一个计算密集的LLM智能地 “分片(Shard)”,并将这些分片部署到一组经过精心挑选的异构计算设备上(包括边缘设备和云服务器)。通过这种方式,它能够:
- 突破内存瓶颈:将一个大到任何单个设备都无法承载的模型,分散到多个设备上,使得部署超大规模模型(如Llama2-70B)成为可能 。
- 优化推理性能:综合考虑各个设备的计算能力、内存大小以及它们之间的网络带宽等因素,智能地决定哪些设备参与计算以及如何切分模型,从而实现最小化推理延迟或最大化系统吞吐量 。
- 保障数据隐私:通过策略强制模型的输入层(第一层)必须部署在用户数据所在的源设备上,避免了原始数据在网络中传输,从而降低了隐私泄露风险 。
主要方法
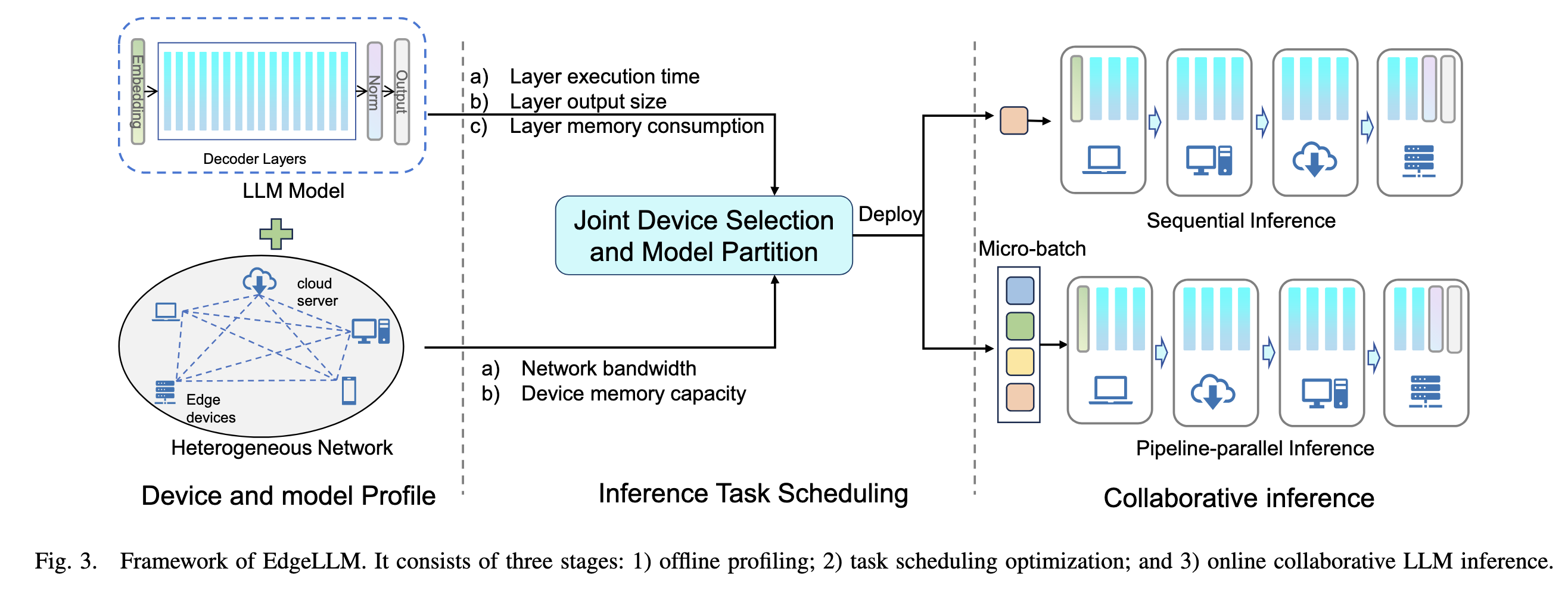
为了实现上述思路,EdgeShard框架的设计包含三个主要阶段:
1. 离线性能剖析 (Offline Profiling) 这是一个一次性的准备步骤 。系统会全面地测量和记录运行LLM所需的关键信息,包括:
- 模型每一层在不同设备上的平均执行时间(同时考虑了预填充和自回归生成两个阶段) 。
- 每一层计算后产生的激活值(即中间结果)的大小和内存消耗 。
- 各个设备的可用内存上限以及设备之间的网络带宽 。
2. 任务调度优化 (Task Scheduling Optimization) 调度器会利用第一阶段收集到的数据,来解决一个“联合设备选择与模型划分”的优化问题。论文针对两种不同的优化目标,设计了两种对应的算法:
提出的两种算法都是简单的动态规划
- 目标一:优化延迟(Latency)
- 场景:主要用于服务单个用户,目标是让用户尽快得到响应(例如智能家居中的语音助手) 。
- 方法:设计了一个动态规划算法。算法通过迭代计算,找出将模型按层切分并依次部署到不同设备上的、总执行时间(计算时间 + 通信时间)最短的方案 。算法复杂度为 $O(N×M^2)$,其中N是模型层数,M是设备数 。
- 目标二:优化吞吐量(Throughput)
- 场景:主要用于服务多个并发用户,目标是提升整个系统的处理效率(每秒能生成多少个Token) 。
- 方法:同样设计了一个动态规划算法。该算法采用流水线并行(Pipeline Parallelism)的方式,目标是最小化流水线中“最慢”那个阶段的耗时,从而让整个系统高效运转 。该算法的复杂度更高,为 $O(N^2×2^M×M^2)$,因为它需要考虑设备的所有可能组合 。
- 流水线优化:论文还提出了一种名为
EdgeShard-No-Bubbles的策略,通过优化流水线中任务的执行顺序,有效减少了因LLM自回归特性导致的设备空闲(称为“气泡”),进一步提升了吞吐量 。
3. 协同推理 (Collaborative Inference) 一旦优化策略生成,被选中的设备就会加载分配给自己的模型分片,并开始协同工作 。推理时,数据(激活值)会按照策略在设备间依次传递,直到最终生成结果。此阶段还特别设计了高效的 KV 缓存管理机制,以应对生成序列变长带来的内存挑战 。
实验
论文在一个由 Jetson 边缘设备和带 RTX 3090 的云服务器组成的真实物理测试平台上,对Llama2系列模型进行了全面的实验 。
- 性能优势:实验结果表明,与传统的单设备部署(Edge-Solo)和云边协同(Cloud-Edge)方案相比,EdgeShard 可将推理延迟降低高达50%,并将吞吐量提升2倍 。
- 可行性:EdgeShard 成功运行了因内存过大(约280GB)而其他方案均无法部署的 Llama2-70B模型 。
- 自适应性:EdgeShard 能够根据网络带宽的变化,智能地调整部署策略。例如,在带宽较低时,它倾向于使用更多的边缘设备;在带宽充足时,它会更多地利用云端强大的算力,其性能表现不会差于优化的云边协同方案 。
结论
思考与评论
质量比较水,参考价值很低,源代码也没放出来,论文大部分篇幅都在介绍两个动态规划算法