Extensive Reading
Author Info
Background
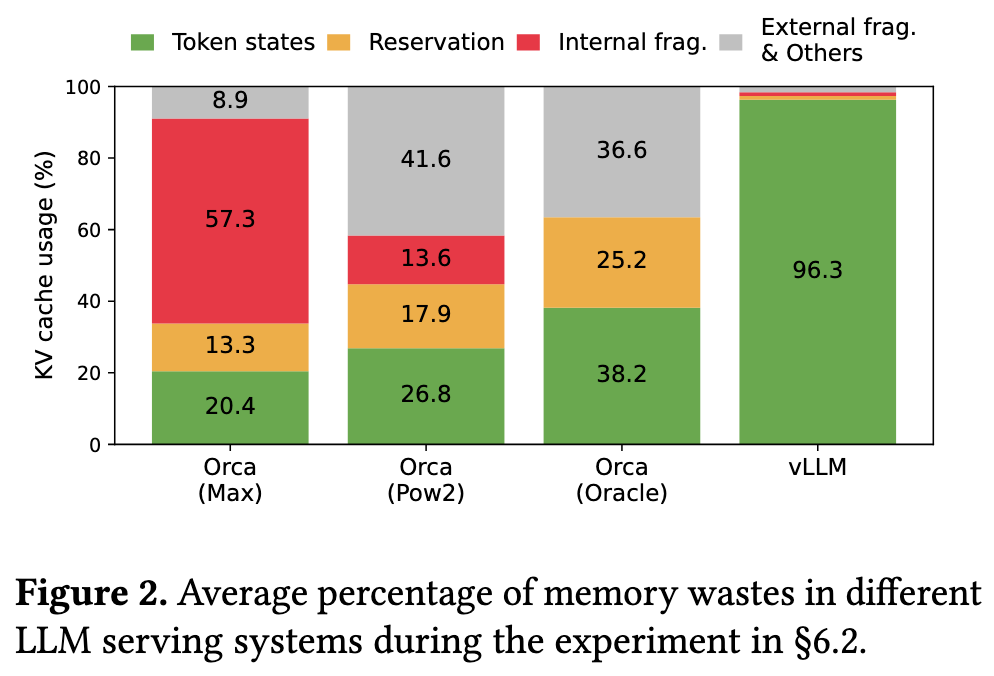
- The existing systems suffer from internal and external memory fragmentation.
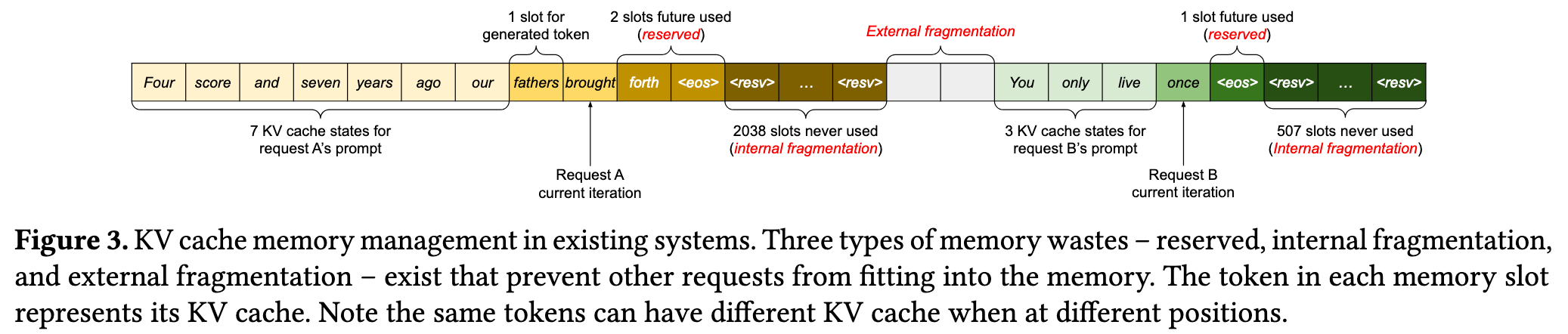
Three primary sources of memory wastes:
7+ Internal fragmentation: Space that will not be used in the future within an allocated memory block.
- External fragmentation: Unused space between memory blocks.
- The existing systems cannot exploit the opportunities for memory sharing.
Parallel sampling, beam search, and shared prefix have the potential to leverage the shared KV cache to reduce memory footprint.
Challenges
The nature of LLM serving presents several core memory management challenges:
Large KV Cache Size: The KV cache for a single request is enormous (up to 1.6 GB for a 13B model), which severely limits the number of requests that can be processed concurrently.
Complex Decoding Algorithms: Methods like beam search and parallel sampling require complex and dynamic memory sharing patterns that traditional systems cannot handle efficiently.
Unknown and Variable Sequence Lengths: The output length of a request is unpredictable and grows dynamically, making static memory pre-allocation highly inefficient and forcing complex scheduling decisions when memory runs out.
Insights
The core innovation lies in applying the classic memory management ideas of operating systems to LLM services.
The paper established an analogy:
- Token <—> Byte
- KV Block <—> Page
- Request <—> Process
The core idea is:
Remove the restriction that KV Cache must be stored physically contiguously.
Without the restriction, the LLM serving system can apply bigger batch size to increase the system throughput.
Approaches
PagedAttention
A new attention algorithm capable of handling KV Cache stored in non-contiguous physical memory blocks. vLLM splits the KV Cache of each sequence into fixed-size “blocks”. When calculating attention, the PagedAttention algorithm looks up and retrieves these scattered blocks through a “Block Table”.
vLLM
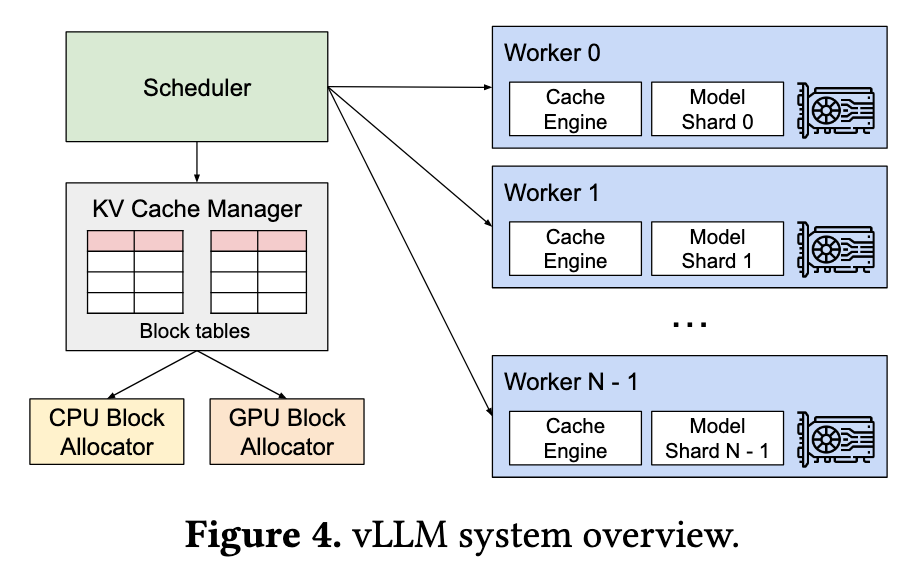
Logical Blocks and Physical Blocks: vLLM treats a request’s KV Cache as a series of “logical blocks,” while GPU memory is divided into many “physical blocks.” The manager maintains the mapping from logical blocks to physical blocks for each request through a “block table.”
Copy-on-Write: When a shared physical block needs to be written with new data by one of the sequences, vLLM triggers “Copy-on-Write”. It allocates a new physical block for that sequence, copies the content of the old block, and then updates its block table mapping, thus ensuring operational independence while avoiding large-scale memory copying.
Preemption and Restoration: When GPU memory is insufficient, vLLM can preempt (pause) certain requests. It supports two restoration mechanisms:
- Swapping: Transferring the KV blocks of preempted requests from GPU memory to CPU memory, and swapping them back when resources become available.
- Recomputation: Directly discarding the KV Cache of preempted requests and recomputing it when they are restored.