Extensive Reading
Author Info
- Ying Sheng: She got her Ph.D. in Computer Science at Stanford University (Centaur), where she was advised by Clark Barrett. Before that, she received an M.S. in Computer Science from Columbia University in 2017 and a B.E. in Computer Science and Technology from ACM Honored Class, Shanghai Jiao Tong University in 2016.
- Lianmin Zheng: He is a member of technical staff at xAI. His research interests include machine learning systems, large language models, compilers, and distributed systems. Previously, he completed his Ph.D. at UC Berkeley, where he was advised by Ion Stoica and Joseph E. Gonzalez.
- Binhang Yuan(袁彬航) – Assistant Profossor@CSE HKUST: He is an assistant professor in the Department of Computer Science & Engineering (CSE), also affiliated with World Sustainable Development Institute, at the Hong Kong University of Science and Technology (HKUST). He is leading the Relaxed System Lab.
Background
Prior efforts to lower resource requirements of LLM inference correspond to three directions:
- Model compression to decrease total memory footprint
- Collaborative inference to amortize inference cost via decentralization
- Offloading to utilize memory from CPU and disk
Challenges
Achieving high-throughput generative inference with limited GPU memory is challenging even if we can sacrifice the latency:
- Design an efficient offloading strategy
- The strategy should specify what tensors to offload, where to offload them within the three-level memory hierarchy, and when to offload them during inference.
- Develop effective compression strategies
Insights
- In resource-constrained offloading scenarios, the system bottleneck shifts from GPU computation to I/O bandwidth. Therefore, minimizing data movement is more critical than maximizing compute FLOPs.
- The conventional token-by-token generation schedule (row-by-row) is I/O-inefficient. By reordering the computation to be layer-by-layer across a large block of batches (the “zig-zag” schedule), the high cost of loading weights can be amortized, significantly improving throughput.
- The optimal offloading strategy is a complex trade-off involving compute scheduling, tensor placement (for weights, KV cache, and activations) across the entire memory hierarchy, and even computation delegation. This can be formally modeled as a unified optimization problem and solved to find a hardware-specific policy.
Approaches
Zig-zag Block Schedule
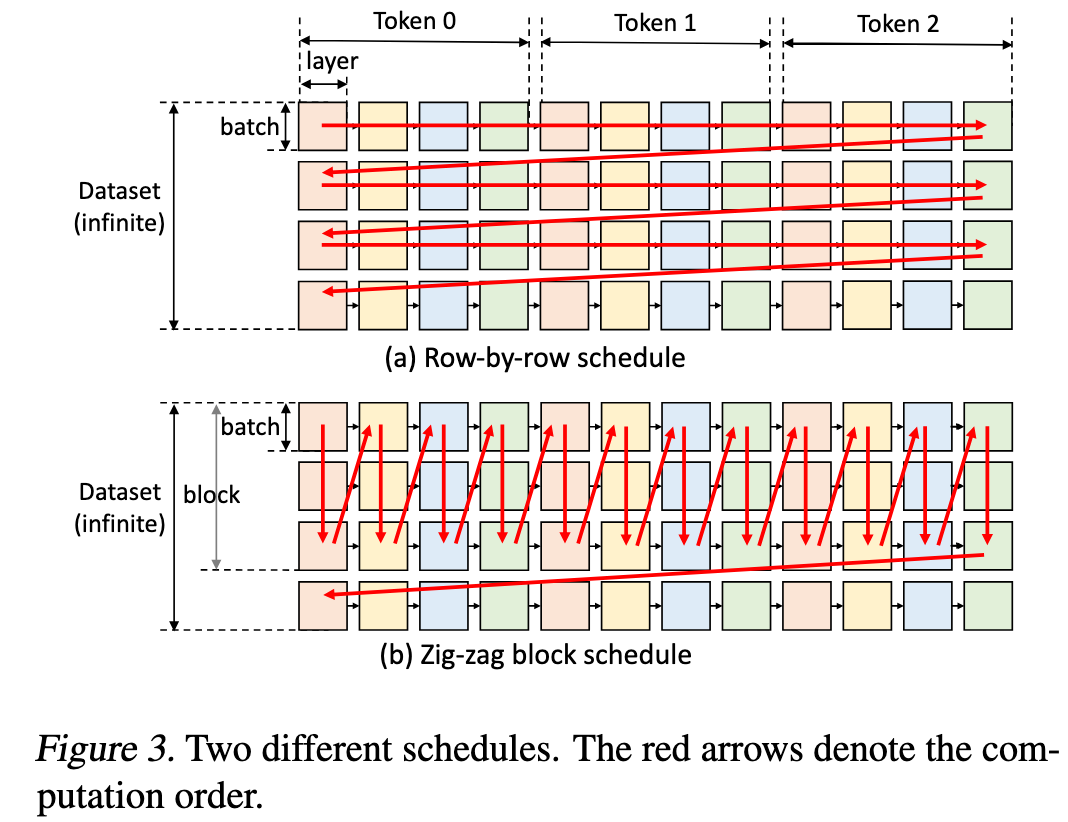
这里利用了 latency-oriented 和 throughput-oriented 的不同特点:
- Latency-oriented: 对于一个batch,尽早地完成整个推理过程,把结果返回给用户
- 由于大模型生成时的自回归特性,需要反复不断地加载不同 layer 的权重,I/O 开销大
- Throughput-oriented: 尽可能地提高吞吐量,延迟不敏感
- 对于一次性加载的权重,尽可能一次性多地处理更多的 batch,整体上降低了切换权重的次数,达到更高的吞吐量
- 将模型的第一层权重加载到GPU上,然后用它处理块内所有批次的计算,完成后再加载第二层权重,以此类推 。这种方式极大地重用了已加载到GPU上的权重,显著减少了I/O次数和总时间。
Policy Search with Linear Programming
为了在不同的硬件上找到最佳配置,FlexGen定义了一个包含计算调度、张量放置和计算委托的复杂搜索空间 。
- 张量放置 (Tensor Placement):决定权重(weights)、激活值(activations)和键值缓存(KV cache)在GPU、CPU和磁盘上的存储比例。
- 计算委托 (Computation Delegation):在某些情况下(例如KV缓存存储在CPU上时),将部分计算任务(如注意力分数计算)从GPU委托给CPU执行,可以避免大规模数据传输,反而更高效。
- 成本模型与优化:FlexGen建立了一个分析性的成本模型来预测延迟和内存使用,并通过求解一个线性规划问题,自动搜索出能最大化吞吐量的最佳策略组合。

Approximation Methods
- 对模型权重和 KV Cache 都进行了 4-bit 量化
- 使用了一个简单的 Top-K 稀疏化策略
- After computing the attention matrices, for each query, we calculate the indices of its Top-K tokens from the K cache. We then simply drop the other tokens and only load a subset of the V cache according to the indices.
- 可以降低 I/O 传输量和计算量
Evaluation
Tricky 的部分比较多(也有可能是我没仔细看, whatever):
- 没有测试 No quantization and sparsification 对系统性能的影响
- “Sometimes a strategy from the policy search can run out of memory. In this case, we manually adjust the policy slightly.",所以测试时手动调整没,是否公平?
- “We turn off the CPU delegation when enabling quantization” 对实验有没有什么影响?
Thoughts
When reading
和 [[papers/llm/Efficient Memory Management for Large Language Model Serving with PagedAttention|PagedAttention]] 的核心思想类似,单个 Batch 越大,吞吐量就越高,特别是在 IO 受限的环境下,因为一个 Batch 中 requests 是一起处理的,只需要加载一次模型的权重就能完成一轮生成,性价比就越高。
感觉对场景的限制有点太大了,在 commodity GPU 上,必须以大批次(比如 256) 进行推理才能达到 0.69 token/s,但在 commodity GPU 上,应该是个人的数据更多吧,latency 才是更看重的指标。
4.1 对问题的建模挺有意思的。
感觉 FlexGen 提出很多方法都是正交的,特别是 Approximate Methods 部分,涉及到一些简单的量化和稀疏化的方法,不能算这个工作的创新点,但是有不可忽略的一部分性能提升来自于量化和稀疏化。
Evaluation 部分,消融实验中没有做 No quantization and sparsification,验证了我的猜想:这两个广泛应用的技术对 FlexGen 的性能有很大影响。