Extensive Reading
Author Info
- Le Chen - Google Scholar
- Haibo Chen [IPADS]: Director of Institute of Parallel and Distributed Systems
Background
现有的LLM推理引擎通常只使用其中一种加速器(例如只用GPU或只用NPU),这导致了两个主要问题:
- 资源浪费:无法充分利用芯片上所有计算单元的算力。
- 性能瓶颈:单一加速器有其固有的性能短板,无法在所有场景下都达到最优性能。
Challenges
Insights
设计一个能够同时、高效地利用 GPU 和 NPU 进行协同计算的 LLM 推理引擎,以最大限度地提升移动设备上的 LLM 推理速度
The NPU serves as the primary computing unit, handling the majority of computing tasks, while the GPU acts as a secondary computing unit to enhance the lower bound of NPU performance.
GPU Characteristics
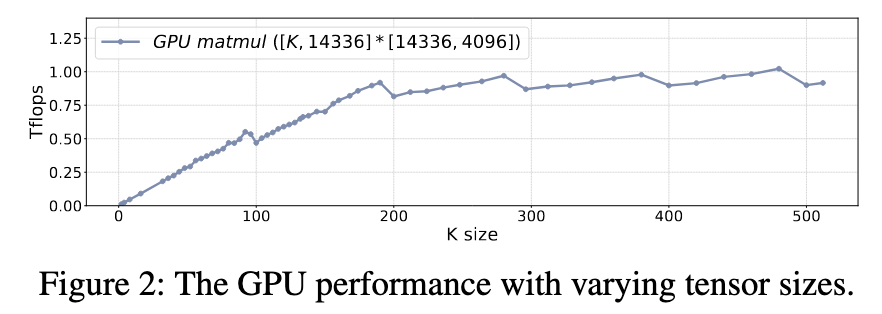
- Linear Performance: The GPU’s performance scales linearly as the tensor size increases. It transitions from being memory-bound on small tensors to compute-bound on large ones, where its performance plateaus.
- High-Cost Synchronization: There are two main types of synchronization overheads.
- Data Copy: API calls to transfer data between CPU and GPU buffers, like
clEnqueueWriteBuffer, incur a fixed latency of about 400 microseconds, irrespective of the data’s size. - Kernel Submission: Submitting a kernel to an active, non-empty GPU queue has a negligible overhead (10-20 microseconds). However, after a synchronization event empties the queue, submitting the next kernel incurs a much higher “startup” latency of 50-100 microseconds.
- Data Copy: API calls to transfer data between CPU and GPU buffers, like
NPU Characteristics
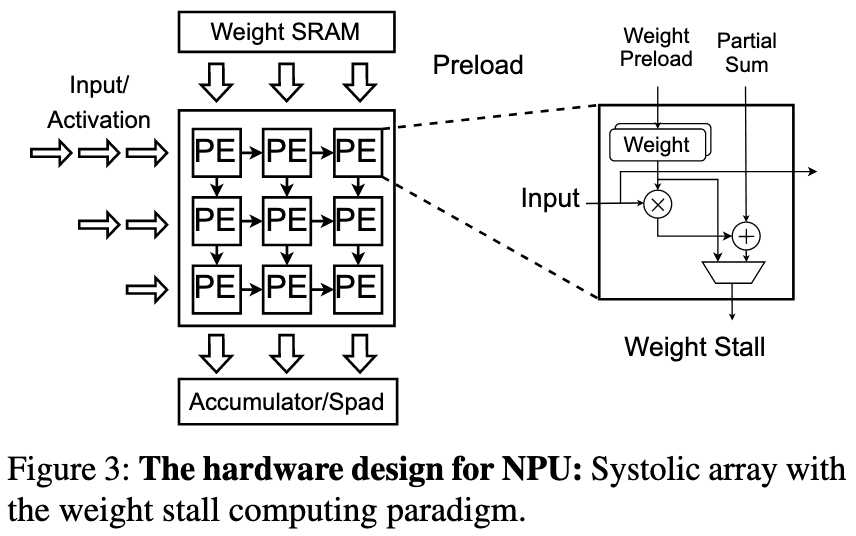
脉动阵列,是一种为特定计算(尤其是大规模的矩阵乘法)而设计的专用并行计算架构。
- 简单的处理单元 (PE): 整个阵列由许多简单、相同的处理单元(Processing Element, PE)构成。每个 PE 通常只能执行一个基础操作,比如“乘加”运算 (Multiply-Accumulate, MAC)。
- 规则且本地化的连接: PE 之间以非常规整的网格状(如二维阵列)连接起来 。关键是,数据只在相邻的 PE 之间传递,避免了长距离的数据传输延迟和功耗。
- 数据脉动流 (Data Flow): 数据从阵列的一侧或多侧输入,然后像波浪一样,以固定的时钟节拍(脉动)流过整个 PE 阵列。在流动过程中,数据与存储在每个 PE 中的权重进行计算,并生成 partial sum,这些部分和也随着数据流一起传递和累加。
- 高并行度和数据重用: 在任何一个时钟周期,阵列中的许多 PE 都在同时进行计算。更重要的是,输入的数据在流经阵列时会被多个 PE 重复使用,这极大地减少了从内存中读取数据的次数,显著提高了计算效率和能效。
NPUs are designed around matrix computation units like systolic arrays that employ a “weight stall” computing paradigm. This leads to several unique performance traits:
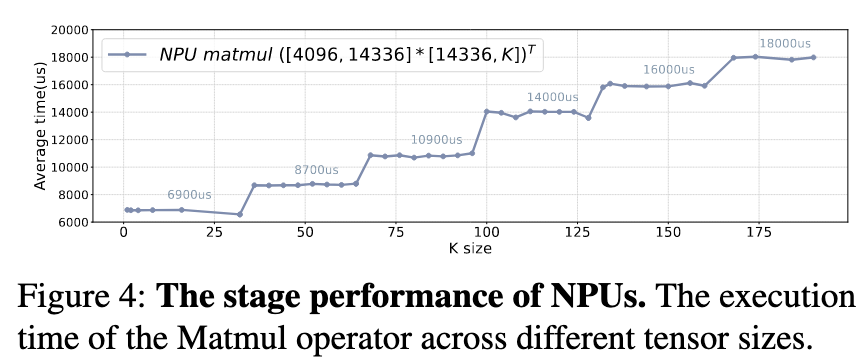
- Stage Performance: NPU performance doesn’t increase smoothly with tensor size but in discrete “stages”. If a tensor’s dimensions do not align with the NPU’s fixed hardware compute unit size, it leads to inefficient resource utilization.
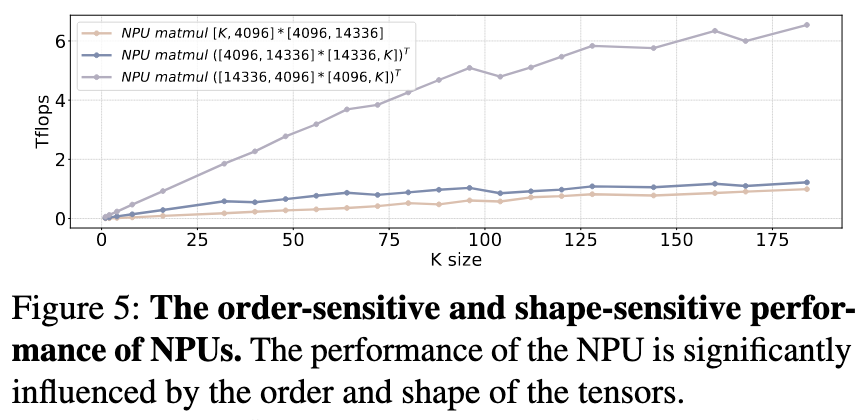
- Order-Sensitive Performance: The order of matrices in a multiplication operation dramatically affects performance, even when the number of computations is identical. For example, multiplying
[14336, 4096] x [4096, K]is up to 6 times faster than multiplying[K, 4096] x [4096, 14336]. This is because the “weight stall” method is most effective when the stationary weight tensor is smaller. - Shape-Sensitive Performance: Beyond the order, the efficiency of NPU computation is also influenced by the specific shape of the tensors, such as the ratio between row and column sizes.
SoC Memory Bandwidth
- Underutilized by Single Processor: No single processor (CPU, GPU, or NPU) can fully saturate the total memory bandwidth of the mobile SoC by itself. While the theoretical limit of the tested SoC is 68 GB/s, a single processor can only achieve about 40-45 GB/s.
- Parallelism Increases Utilization: When the NPU and GPU run tasks concurrently, their combined memory bandwidth usage increases to approximately 60 GB/s, which is much closer to the theoretical maximum. This presents an opportunity for performance improvement, especially in memory-intensive phases like decoding.

Approaches
- NPU serves as the primary computing unit, handling the majority of computing tasks
- GPU acts as a secondary computing unit to enhance the lower bound of NPU performance
- CPU serves as a control plane for synchronization, GPU kernel scheduling, and handling non-compute-intensive tasks such as dequantization
HeteroLLM employs two methods for GPU-NPU parallelism:
- Layer-level heterogeneous execution
- different operators are assigned to the most suitable backends
- Matmul operators are directed to the NPU backend
- RMSNorm/SwiGLU operators are more efficiently handled by the GPU backend
- since typical LLM models feature larger size of weight tensors compared to user’s input tensors, the input and weight tensors are permuted to meet NPU characteristics
- different operators are assigned to the most suitable backends
- Tensor-level heterogeneous execution
Tensor Partition Strategies
主要策略有三个
TODO: 添加论文里提到的具体例子
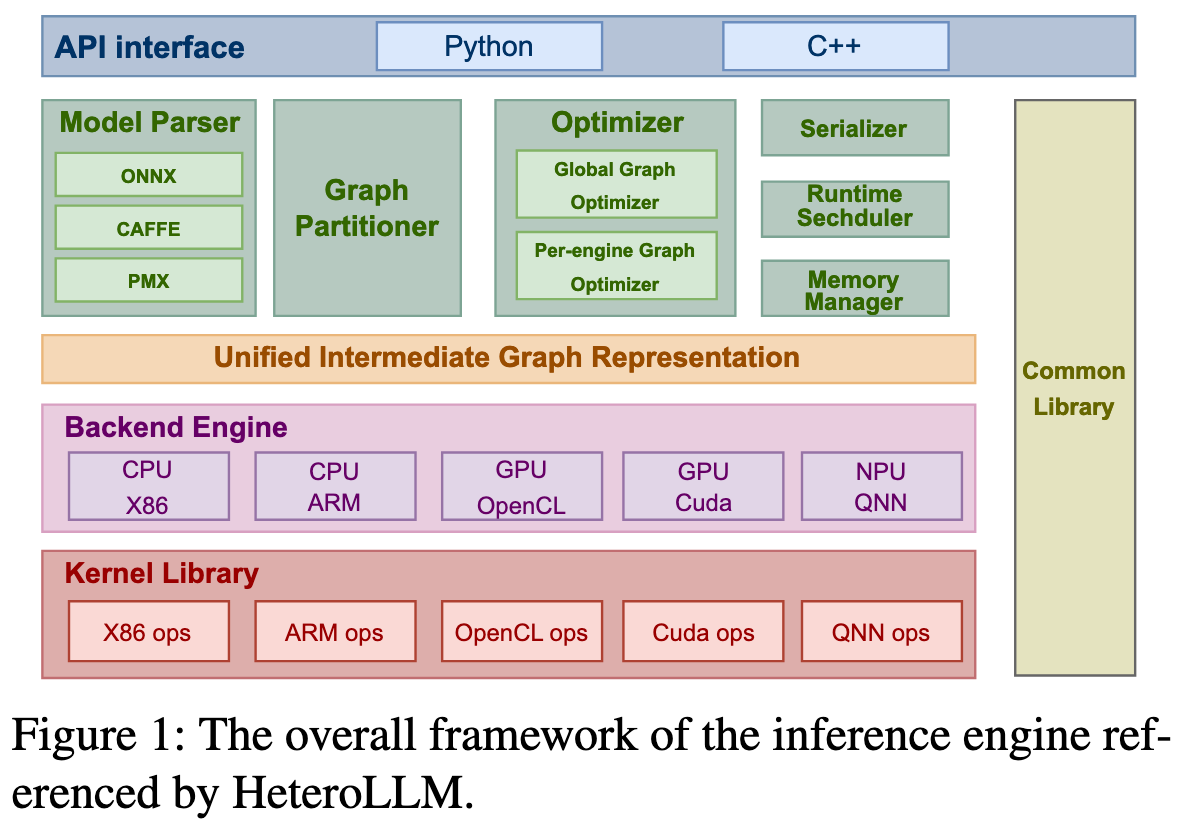
- Row-cutting
- 当遇到某些让NPU性能下降的张量形状时(如FFN-down层或输入序列较短时),将权重张量按“行”切分,一部分交给NPU计算,另一部分交给GPU同时计算
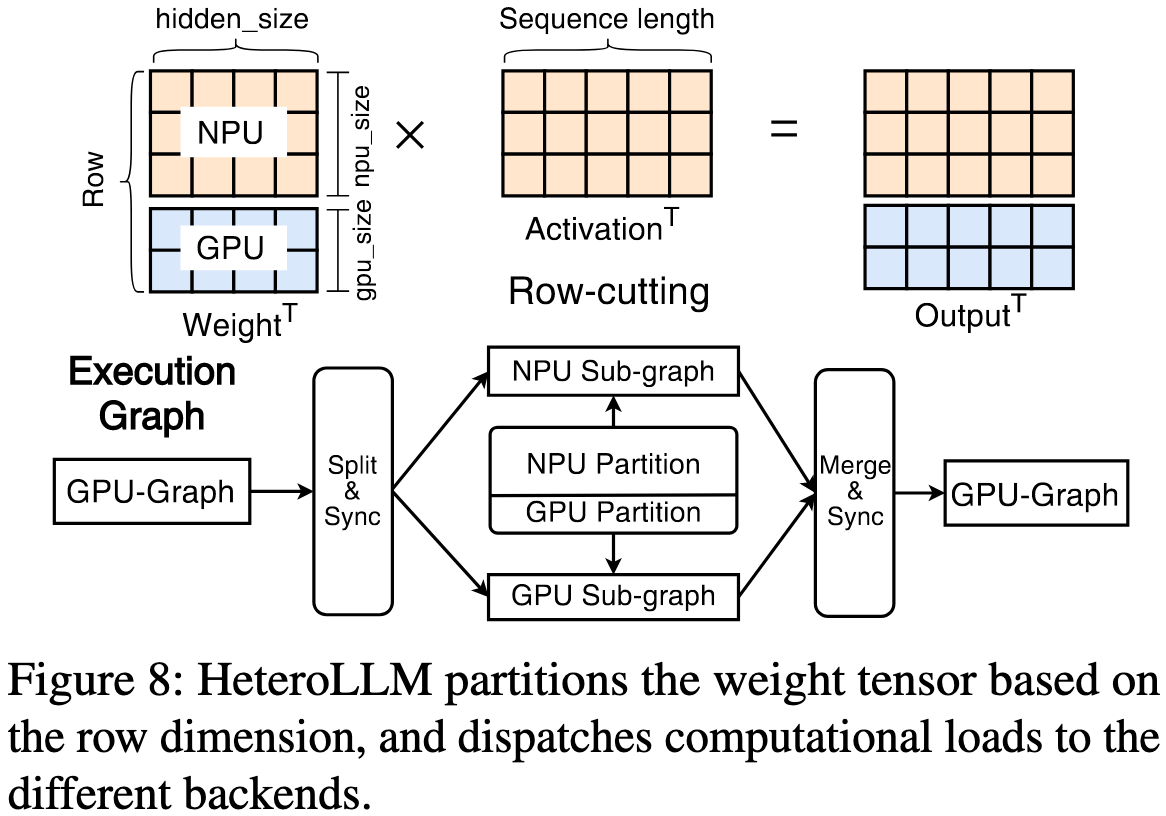
- 当遇到某些让NPU性能下降的张量形状时(如FFN-down层或输入序列较短时),将权重张量按“行”切分,一部分交给NPU计算,另一部分交给GPU同时计算
- Sequence-length cutting
- 为了解决 NPU 静态图无法处理动态输入的问题。将一个动态长度的输入序列切分成两部分:一个符合 NPU 预定义尺寸的部分交给NPU,剩下“零头”部分交给能处理动态尺寸的 GPU 。这样既避免了为 NPU 重新生成图的巨大开销,也避免了传统 Padding 方法带来的无效计算
- Hybrid cutting
- 结合 Row-cutting 和 Sequence-length cutting
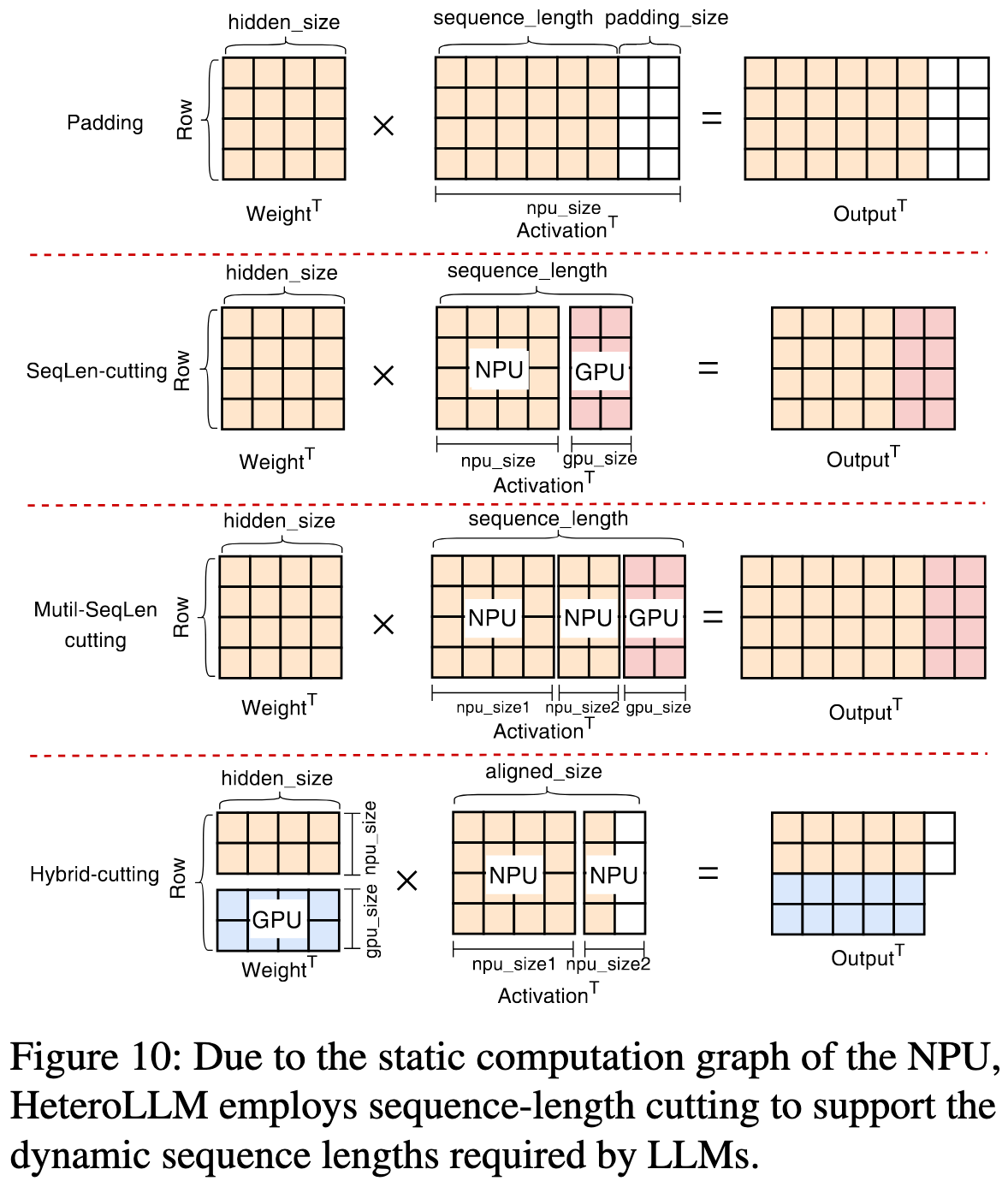
- 结合 Row-cutting 和 Sequence-length cutting
Prefill 阶段采用 Hybrid-cutting, Decoding 阶段采用 Row-cutting
Fast Synchronization
异构计算会引入处理器间的同步开销,这在每一步操作都很快的Decoding阶段尤其致命
HeteroLLM 采用了:
- 统一内存:CPU、GPU、NPU 共享物理内存,通过内存映射避免了耗时的数据拷贝
- 预测性等待与轮询:由于 LLM 每层的计算是重复的,因此 GPU/NPU 的执行时间是可预测的。同步线程可以先“睡眠”一段预测的时间,然后再通过CPU核心高频“轮询”一个标志位,实现精确且低开销的同步
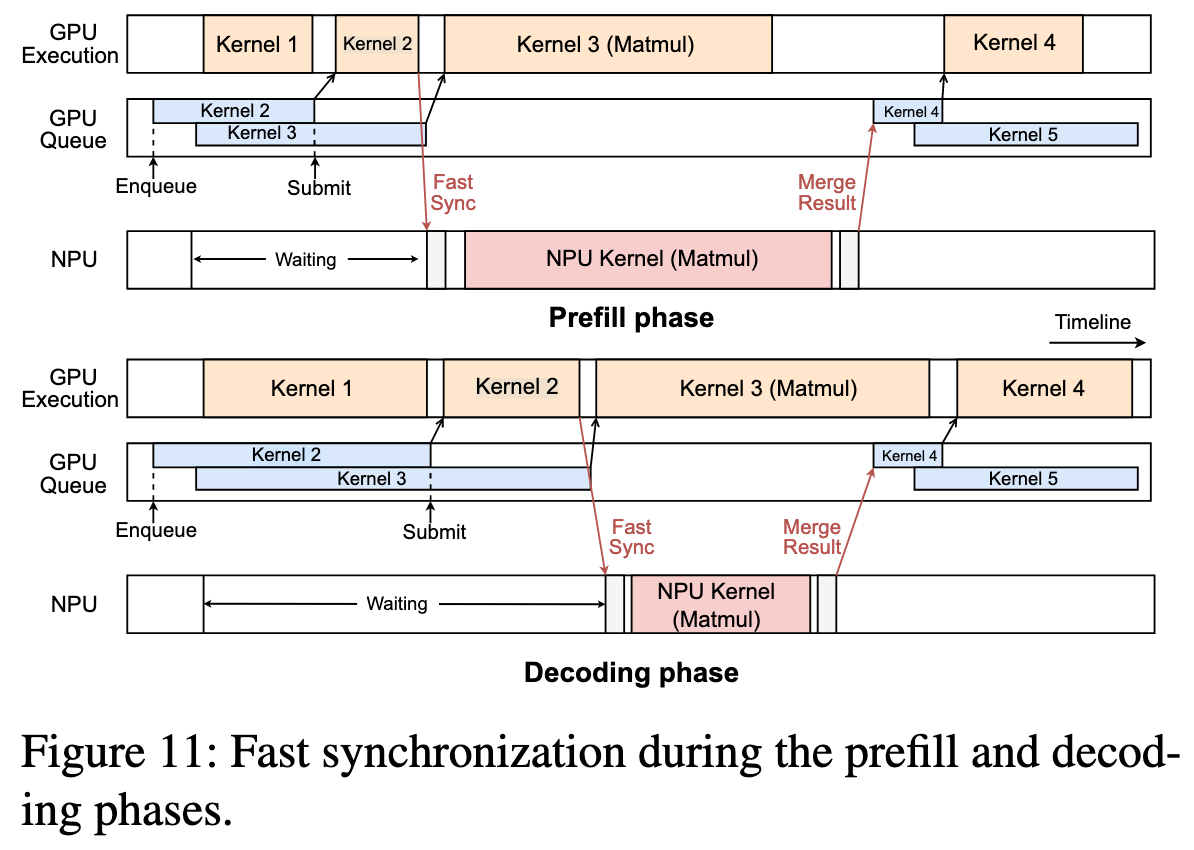
- 在 Prefilling 阶段,是 NPU-dominant
- 协同策略:将 GPU 的计算时间“隐藏”在 NPU 的计算时间之内
- 在 Decoding 阶段,是 GPU-dominant
- 协同策略:将 NPU 的计算时间“隐藏”在 GPU 的计算时间之内
- 系统不再等待 GPU 完成任务。而是在并行的 NPU 任务一结束,就立即将下一个 GPU 任务(Kernel 4)提交到 GPU 的任务队列中
- 利用了GPU的内部硬件队列来完成同步,从而完全避免了CPU层面的“显式等待”
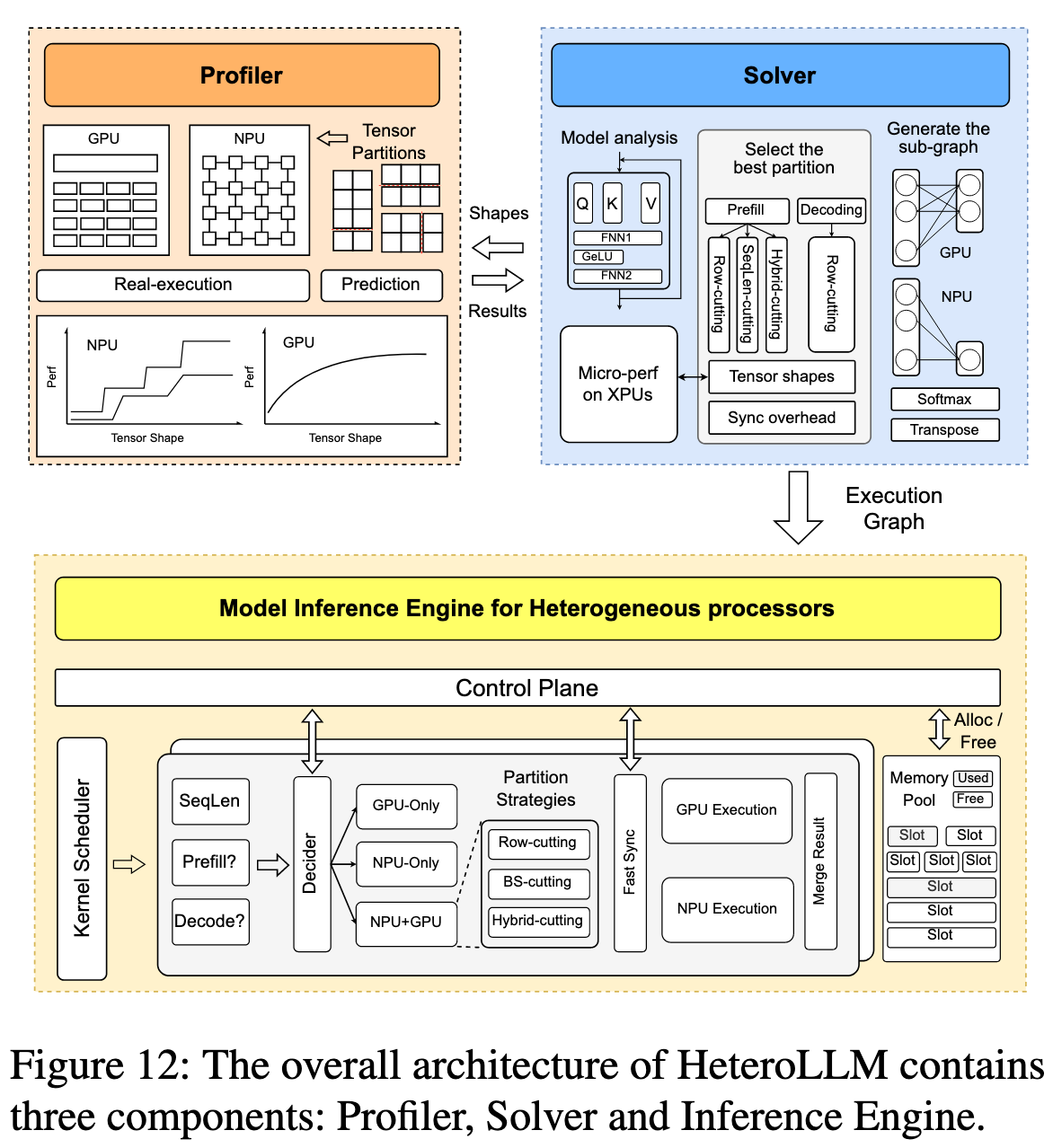
Solver & Profiler
如何为特定的计算任务选择最优的执行方案(只用GPU、只用NPU,还是GPU+NPU协同)以及如何确定最佳的切分比例?这是由求解器和分析器自动完成的。
- Profiler:离线分析和测量在真实硬件上,不同尺寸、形状的张量在 GPU 和 NPU 上的实际性能,建立一个性能模型
- Solver:根据 Profiler 提供的性能数据,自动计算并选择最优的划分策略和比例,目标是让 GPU 和 NPU 的计算时间尽可能重叠,从而使总耗时最短
Evaluation
- 性能提升显著:与现有主流的移动端推理引擎(如 MLC, MNN)相比,HeteroLLM 在 Prefill 阶段实现了高达 9.99 倍的性能提升,在 InternLM-1.8B 模型上实现了超过 1000 tokens/s 的惊人速度 。在 Decoding 阶段,通过充分利用内存带宽,性能提升了 23.4%
- 处理动态输入更高效:对于与 NPU 预设尺寸不符的输入,HeteroLLM 的切分策略比传统的 Padding 最多快 2.12 倍
- 多任务处理友好:在运行 LLM 推理的同时运行大型手机游戏,GPU-only 的方案会导致游戏帧率降为零,而 HeteroLLM 几乎不影响游戏帧率(稳定在60 FPS)
- 高能效:与纯 GPU 方案相比,HeteroLLM 的能效提升了 5.87 倍
Thoughts
When Reading
NPU 的 FP16 性能有这么高?我记得哪篇工作里说 NPU 不擅长 FP16 的计算来着?
llm.npu 这篇工作也需要依靠 model activation sparsity 吗?
怎么都喜欢搞一个 solver 之类的?