Extensive Reading
Author Info
Background
- Early Exit (Dynamic Halting)
- These techniques attempt to stop the forward pass at an intermediate layer if the model is sufficiently confident in the prediction.
- Problems: In standard LLMs, early layers are “lazy” (not trained to produce final tokens), leading to severe accuracy drops; furthermore, these methods typically require adding and training auxiliary “exit heads,” which increases parameter overhead.
- Layer Pruning and Dropout
- Existing research has explored skipping layers (dropout) during training to make sub-networks robust or pruning layers post-training for speed.
- Problems: Standard uniform layer dropout does not specifically incentivize early layers to be accurate, and post-training pruning often results in performance degradation that requires complex fine-tuning to recover.
Insights
Accelerate Large Language Model (LLM) inference by enabling the model to generate tokens using fewer layers when possible, while maintaining accuracy.
By using the LayerSkip, self speculative decode can be achieved within a single model, allowing the earlier layers to generate draft tokens and the later layers to verify them.
Motivation

Motivation part is interesting, the authors connect every transformer layer to the LM Head, then observe the output token:
- Token predictions in earlier layers appear to be irrelevant as they correspond to the previous token projected on the model’s embedding layer’s weights, which are different from the weights of the LM head; in later layers, token predictions converge to the final prediction.
- The final token prediction is predicted fewer layers before the end.
Approaches
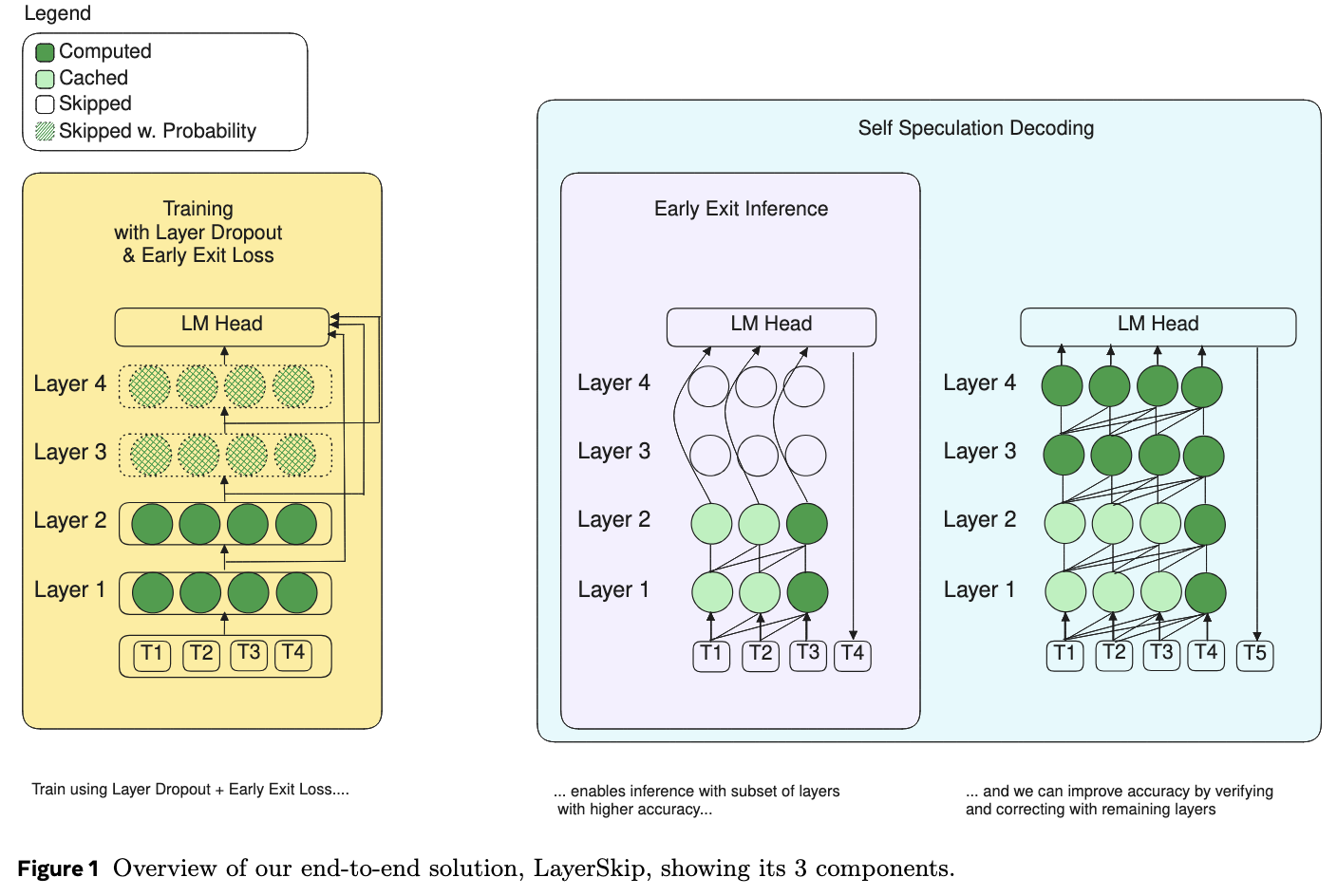
Training
- Layer Dropout with Inverted Rates:
- During training, layers are skipped stochastically. LayerSkip applies a schedule where dropout rates are lower for earlier layers and higher for later layers.
- This forces the model to rely less on the final layers and more on the earlier ones to form high-quality representations.
- Early Exit Loss
- LayerSkip introduces a loss function that grades the model’s output after every single layer.
- LayerSkip uses the same LM Head for every layer, forces the early layers to speak the same “language” (produce the same type of data embeddings) as the final layer
- The training loss is a weighted sum of the errors at all layers. The authors give higher weight to later layers, ensuring the final output remains the most accurate, while still penalizing early layers if they are wrong.
Inference
For tasks requiring lower latency or where slight accuracy trade-offs are acceptable, the model can simply stop execution at a pre-defined early layer (Layer $E$) and generate the token using the shared LM head.
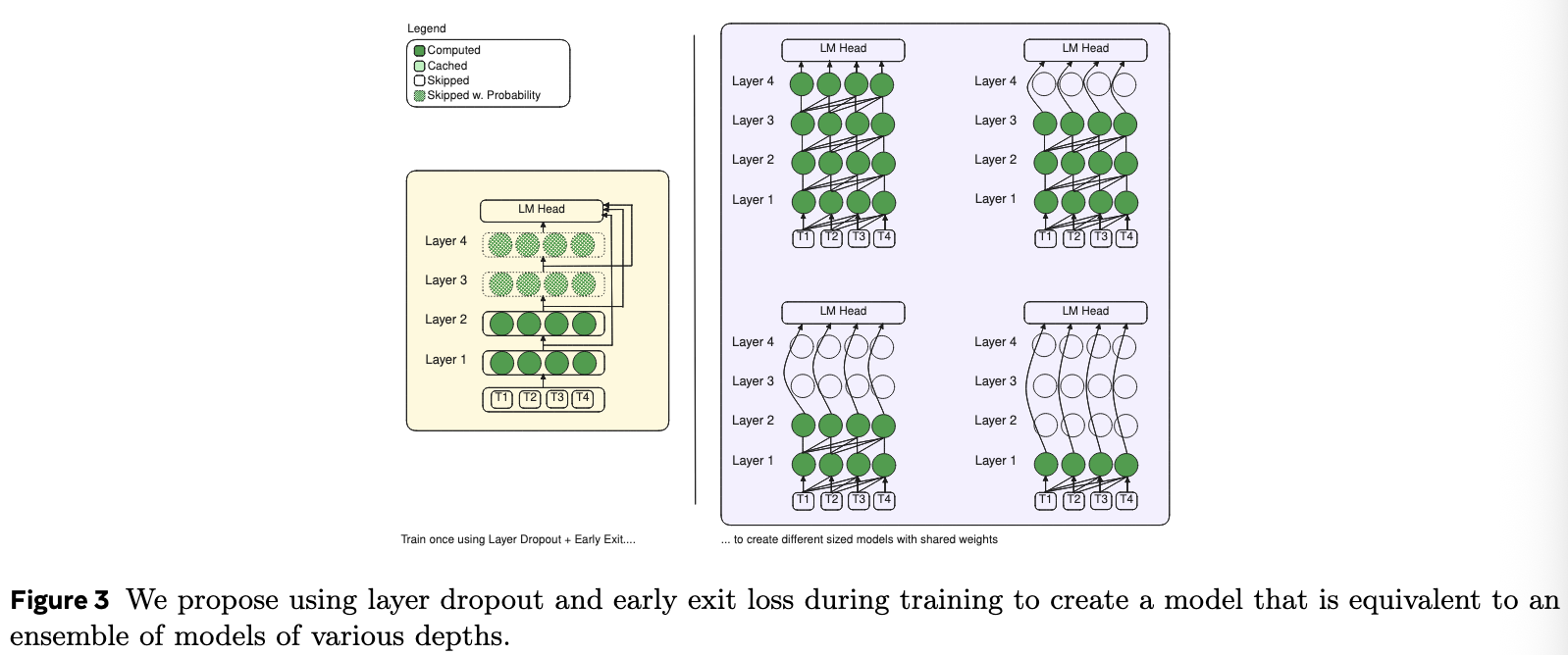
通过在不同位置退出,可以形成一系列大小不同的草稿模型
Self-Speculative Decoding
- Self-Drafting: The model executes the first $E$ layers to rapidly generate a sequence of “draft” tokens.
- Self-Verification: The remaining layers ($E+1$ to $L$) are then executed to verify these draft tokens in a single forward pass.
- Cache Reuse: A critical optimization is the reuse of compute states. Since the draft and verifier are parts of the same model, the Key-Value (KV) cache generated during the drafting phase (layers $1$ to $E$) is preserved and reused during the verification phase.
LayerSkip introduces an exit query cache that saves the query vector of exit layer E − 1 for verification to directly continue from layer E to last layer L.
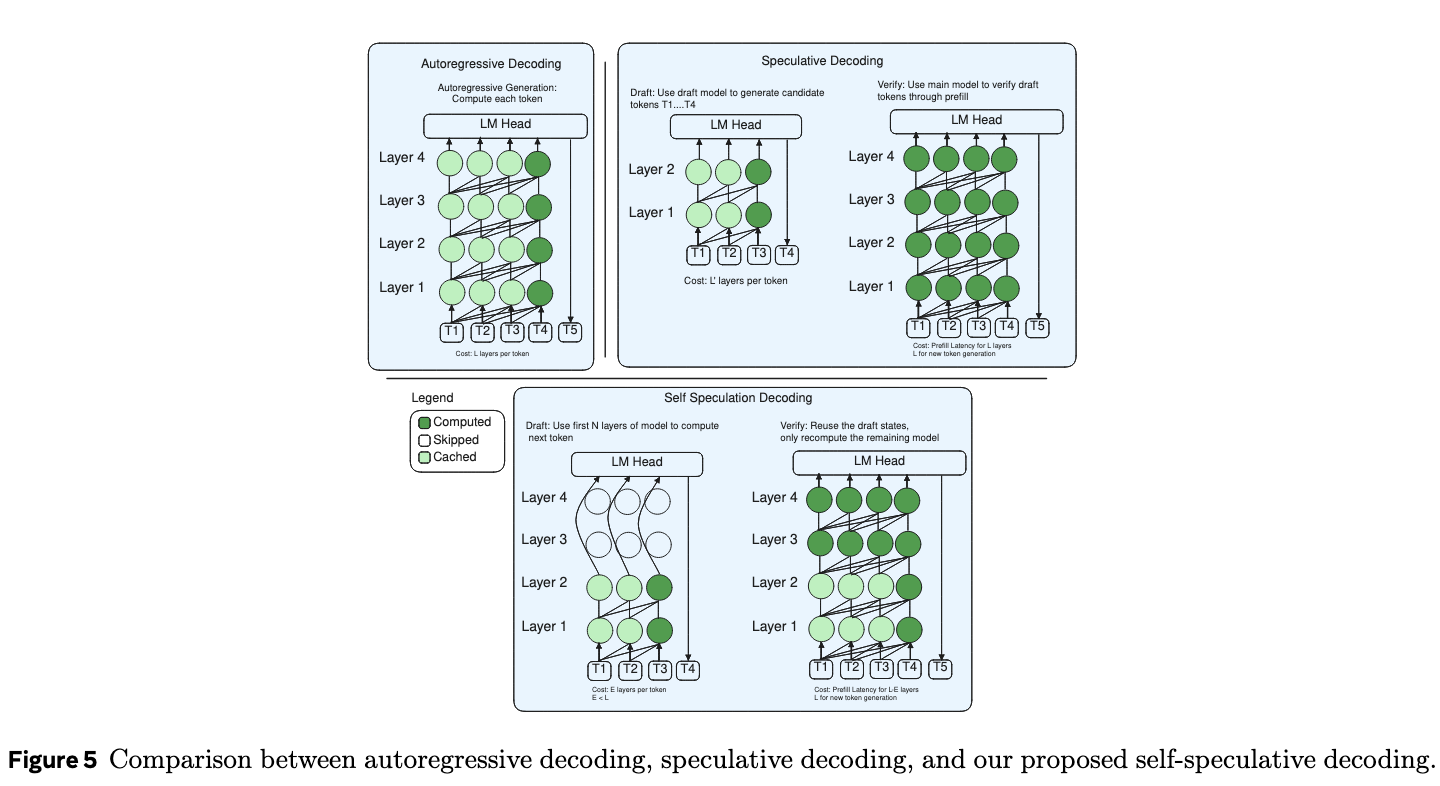
- T1, T2, T3 生成时只用到了 L1, L2, 加快了推理速度
- T4 生成时可以直接复用 T1, T2, T3 推理时已经生成的 KV Cache,只需要计算模型中在草稿阶段未使用的剩余层
- 并且由于 T1, T2, T3 在 L2 之后的 hidden_states 也被缓存了,所以 Verify 阶段可以直接跳过
Evaluation