Intensive Reading
Author Info
Background
论文首先提出了 LLMaaS: LLM as a system service on mobile devices (LLMaaS): The mobile OS exposes an LLM and its inference infrastructure as a system feature to mobile apps, akin to the location or notification services.
LLMaaS 的提出主要有以下原因:
- LLMaaS needs only one copy of LLM weights in memory.
- 不同应用程序应该去调用由系统维护的同一个大模型,而不是自己单独去加载一个
- A system-level LLM can be better customized for on-device accelerator and enjoy the performance gain over commodity hardware.
- 在系统层面去做大模型的管理和推理更接近底层,能够更好地利用底层的硬件资源
这篇文章要解决的核心问题是 How to efficiently manage the LLM contexts
论文提出了三个观察:
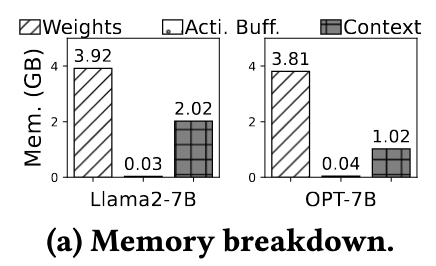
- LLM contexts are memory-intensive.
LLM 的内存占用可以分为三部分:
- Weights
- Activations
- Context
- LLM contexts often need to be persistent.
核心思想:在多轮对话时,只保存对话上下文的文本的话,每次都需要重新计算,不如持久化上下文的 KV Cache,这样能够省去很大一部分重计算
- The conventional app-level memory management is not satisfactory.
LLM contexts 和一般的应用内存有很大的不同:
- LLM contexts are more expensive in terms of time/energy expenditure to obtain.
- LLM contexts are relatively cold.
- LLM contexts are naturally compressible.
Challenges
Insights
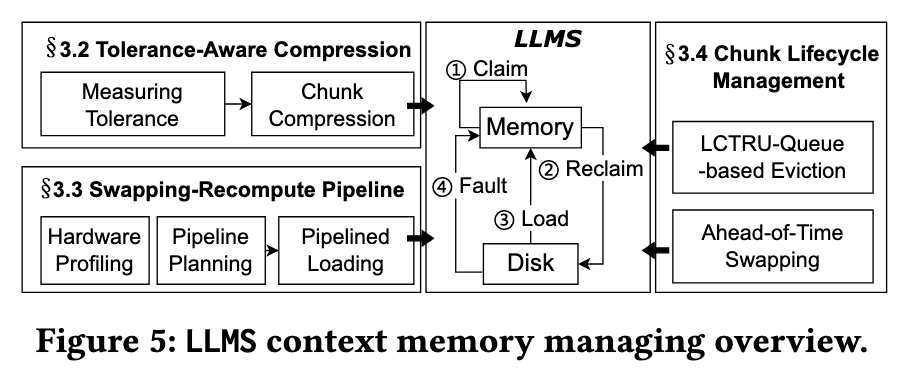
主要的 insight: 将 LLM 上下文内存管理从应用中解耦,采用基于 chunk 的 KV 压缩和交换机制,原因有三个:
- KV cache is easy to be chunked.
- KV cache is unevenly tolerant to compression.
- KV cache can be recomputed.
对应地,LLMS 提出了三个核心技术:
- Tolerance-Aware Compression: 不同 KV chunk 的信息密度不一样,可以根据信息密度分配不同的压缩比例
- Swapping-Recompute Pipeline: 从磁盘加载 KV chunks 时,由于 CPU 处于 idle 状态,可以利用 KV cache 能够被重新计算的特性,直接重计算部分 KV chunk,降低 I/O 延迟
- Chunk Lifecycle Management: 采用更优雅的驱逐策略,尽可能隐藏上下文切换期间的内存回收时间
Approaches
Overview
LLMS 的 API
| Interface | Descriptions |
|---|---|
| Class LLMService | A system service class that is similar to the Android’s android.app.Service class. |
| Class LLMCtx | A class that defines LLM context. LLMService interacts with apps via LLMCtx. |
| Method newLLMCtx( Optional systemPrompt ) -> LLMCtxStub | A method that returns a stub of a new LLM context. On initializing, optional system prompts can be assigned to LLMCtx. |
| Method bindLLMService( app ) -> LLMService | A method that binds the LLMService to an app. |
| Method callLLM( LLMCtxStub, newPrompt ) -> outputs | A method that calls LLMService via an LLMCtx. It takes an LLMCtxStub and a new prompt as input, and returns the updated LLMCtxStub and decoding results. |
| Method delLLMCtx( LLMCtxStub ) | A method that deletes an LLMCtxStub. |
A context is divided to swappable fragment(KV Cache) and memory-resident fragment(prompt/output text)
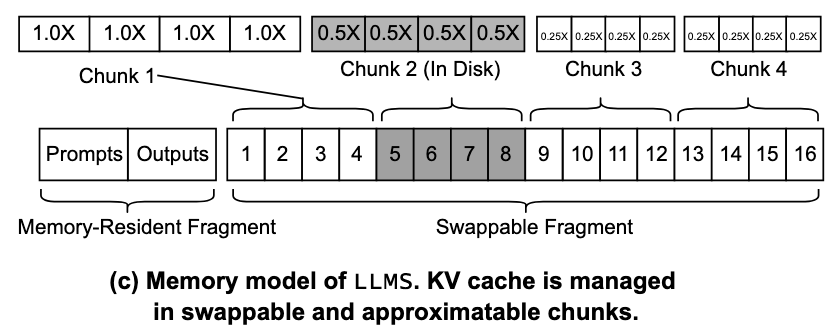
LLMS context memory management 有下面这几个原语:
Claim: Directly allocate free memory to a chunkReclaim: Swap a chunk out to disk and reallocate its memory to a new chunkLoad: Move a missing chunk from disk to memory before LLM inferenceFault: Move a missing chunk from disk to memory at LLM inference
Tolerance-Aware Compression
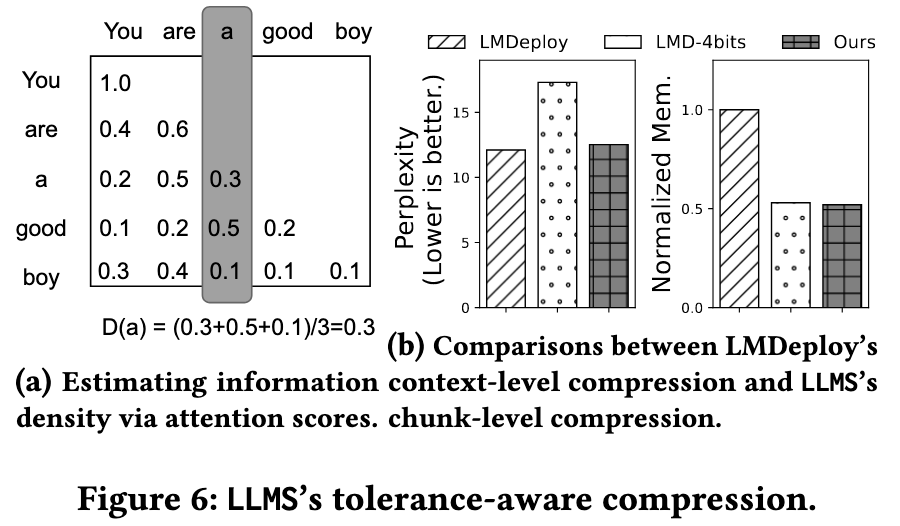
Key idea: Different chunks do not contribute coequally to LLM inference.
If a token is always paid more attention by other tokens, it should be more informative.
信息密度主要和注意力分数相关,某一列的注意力分数越大,说明这个 token 的信息密度越大,对应的压缩策略为:
- 高信息密度 chunk → 低压缩比率(保留更多精度)
- 低信息密度 chunk → 高压缩比率(可以大幅压缩)
attn_score(i, j): 位置 i 的 query 向量 与 位置 j 的 key 向量 的相似度, 衡量的是 token i 在更新自身表示时,要多大程度地关注 token j (第 i 个 token 对第 j 个 token 的注意力权重)- 矩阵第 i 行:第 i 个 token(query i)对序列中所有 token(keys 1..n)的注意力分布,softmax 之后一行之和恒等于 1
- 矩阵第 j 列:所有 queries(所有 token)对第 j 个 token(key j)的关注程度,第 j 列的和一般不是 1,但它的大小可以看作 token j 的「全局重要性」或「被关注度」

核心实现是对低密度 chunk 进行了二次量化(量化本质是数值映射,可以链式进行)
Python 伪代码
def two_stage_quantization(kv_cache_fp16, target_bits):
# 第一阶段:框架内置INT8量化
kv_int8, scale1, zero1 = quantize_to_int8(kv_cache_fp16)
# 第二阶段:LLMS进一步量化
if target_bits == 4:
kv_int4, scale2, zero2 = channel_wise_quantize(kv_int8, bits=4)
return kv_int4, (scale1, zero1, scale2, zero2)
elif target_bits == 2:
kv_int2, scale2, zero2 = channel_wise_quantize(kv_int8, bits=2)
return kv_int2, (scale1, zero1, scale2, zero2)
else:
return kv_int8, (scale1, zero1)
def channel_wise_quantize(tensor, bits):
# tensor形状: [seq_len, num_heads, head_dim]
scales = []
zero_points = []
quantized = torch.zeros_like(tensor, dtype=torch.int8)
for head_idx in range(tensor.shape[1]):
head_data = tensor[:, head_idx, :]
scale = (head_data.max() - head_data.min()) / (2**bits - 1)
zero_point = 2**(bits-1)
quantized[:, head_idx, :] = torch.clamp(
torch.round(head_data / scale + zero_point),
0, 2**bits - 1
)
scales.append(scale)
zero_points.append(zero_point)
return quantized, scales, zero_points
量化的整个生命周期可以说明一下:
- Prefill
- 跑完整上下文的前向,得到注意力矩阵与首批 KV。
- 基础量化(如 8-bit 上下文级量化)对新生成的 KV 先做“保底”压缩。
- Decoding
- 逐步生成新 token;对应 KV 持续按同样的基础量化落盘/入内存。
- 期间不动态重排、不改分档(只做统一的基础量化)。
- 收尾压缩点(call 结束时)
- 用本次前向里已有的注意力矩阵做一次“快照”:对每个 token 的列做均值(被关注度)→ 跨头/层聚合 → 汇总为其所在 chunk 的信息密度 $D_i$
- 排序 + 阈值 + 量化:在给定的全局平均压缩率约束下,把每个 chunk 分到目标位宽档(如 8/8、4/8、2/8),最后再进行二次量化
遇到“被重压缩却突然重要”的旧内容,LLMS要么用重算“升级成精确KV”,要么先按量化参数直接用;而在下一轮,它会基于新的注意力分布把这些块调回更安全的位宽档位。
Swapping-Recompute Pipeline
LLMS introduces recompute to swapping-in to further accelerate it, as processor is idle during disk I/O.
传统加载方式:
Timeline: [I/O chunk1] → [I/O chunk2] → [I/O chunk3] → [I/O chunk4]
CPU: Idle Idle Idle Idle
Swapping-Recompute Pipeline
Timeline: [I/O chunk1 | Recompute chunk2] → [I/O chunk3 | Recompute chunk4]
CPU: Working Working
Chunk Lifecycle Management
- Regarding which chunk to swap out, it employs an LCTRU queue to determine the eviction priority.
- Regarding when to swap out, it adopts an ahead-oftime swapping-out approach to hide the time for reclaiming memory during context switching.
Evaluation
Thoughts
When Reading
Observation#2: LLM contexts often need to be persistent.
这个比较有意思,把持久化 KV cache 是 LLM 作为系统服务的核心需求,这与传统无状态模型完全不同
KV Chunk 是如何组织的:
一个 chunk 包含某个特定 token 在所有层中的 KV 数据
Token序列: [token_1] [token_2] [token_3] [token_4] ...
传统整体存储:
Layer 1: [t1_kv] [t2_kv] [t3_kv] [t4_kv] ...
Layer 2: [t1_kv] [t2_kv] [t3_kv] [t4_kv] ...
...
Layer 32:[t1_kv] [t2_kv] [t3_kv] [t4_kv] ...
LLMS的chunk分割 (假设chunk_size=2):
Chunk 1: {
Layer 1: [t1_kv] [t2_kv]
Layer 2: [t1_kv] [t2_kv]
...
Layer 32:[t1_kv] [t2_kv]
}
Chunk 2: {
Layer 1: [t3_kv] [t4_kv]
Layer 2: [t3_kv] [t4_kv]
...
Layer 32:[t3_kv] [t4_kv]
}