Intensive Reading
Author Info
- Keivan Alizadeh-Vahid - Google Scholar
- Iman Mirzadeh: An ML Research Engineer at Apple.
Background
LLM is hard for personal devices to load. The standard approach is to load the entire model into DRAM (Dynamic Random Access Memory) for inference. However, this severely limits the maximum model size that can be run.
Challenges
The primary challenge is that the memory footprint of large language models (LLMs) often exceeds the limited DRAM capacity of personal devices. While storing models on high-capacity flash memory is a potential solution, it introduces two new major challenges:
- I/O Bottleneck: Flash memory has significantly lower bandwidth compared to DRAM, and its performance is particularly poor for the small, random reads that are typical during inference. This makes loading model weights on-demand extremely slow.
- Sparsity Dilemma: Although FFN layers exhibit high activation sparsity, this benefit can only be realized after computation. To produce the sparse output, the entire dense “up-projection” weight matrix must be loaded into memory first, which nullifies much of the potential I/O savings.
Insights
I/O is the bottleneck of the LLM inference.
Ways to reduce I/O latency when running LLM inference:
- Reduce the volume of data transferred from flash
- “Windowing” strategically reduces data transfer by reusing previously activated neurons
- Read data in larger, more contiguous chunks
- “Row-column bundling”, tailored to the sequential data access strengths of flash memory
- The throughput for random reads from flash memory is not constant; it significantly increases when reading larger, contiguous data chunks and when using multiple parallel threads.
- The high latency cost of small, individual reads makes it more efficient to bundle data together into larger chunks—even if it means reading slightly more than necessary and discarding the unneeded parts.
Approaches
LLM-Flash 提出的方法可以分为三类:
- Reducing Data Load
- Optimizing Data Chunk Size
- Efficient Management of Loaded Data
“our focus is not on optimizing the compute, as it is orthogonal to the core concerns of our work.”
Reducing Data Transfer
LLM-Flash 将 embedding layer 和 attention 相关的权重直接保存在内存中,然后利用了 FFN 的 high sparsity 的特点:
- ReLU 激活后,激活值中许多值变为 0,所以 W_down 不用完整加载到内存中,只需要加载激活值中对应的非零列就行,但这样有两个问题:
- 计算和 IO 不能重叠:只有在 ReLU 之后才能知道哪些列需要被加载,即 W_down 不能提前加载
- W_up 还是得完整地加载到内存中
所以 LLM-Flash 直接从源头解决问题:训练一个 low-rank predictor,来预测激活值中的哪些部分会被 ReLU 变为零,从而加载非零部分对应的 W_up 和 W_down.
- 现有工作
- 使用 第 N-1 层 FFN模块的输出来预测 第 N 层 FFN 模块的稀疏性
- 预测可以在第 N 层 Attention 模块计算的同时进行,理论上可以更好地隐藏 I/O延迟
- LLM-Flash
- 使用 当前第 N 层 Attention 模块的输出,来预测当前第 N 层 FFN 模块的稀疏性
- 预测被推迟到第 N 层 Attention 模块计算完成之后才进行
作者认为,经过 attention 模块处理过后的输出是一个信息更丰富,更具判别力的向量表示,能更准确地预测激活结果,也就对应着更少的 False Negatives, 即更少地漏掉本应被加载的关键权重,保证了模型的最终性能。
LLM-Flash 还采用了滑动窗口技术在 DRAM 中缓存神经元权重数据,核心目标是通过重用最近使用过的权重,来最小化每一次从闪存中加载的数据量。
这个缓存里只存放根据最近输入令牌子集预测所需的权重行,当系统处理一个新的输入 token 时,它只会增量加载那些与它之前的临近 token 所需权重不同的部分。同时,当一些旧的 token 移出这个“滑动窗口”时,它们所占用的缓存权重资源会被释放掉,从而实现了高效的内存利用。
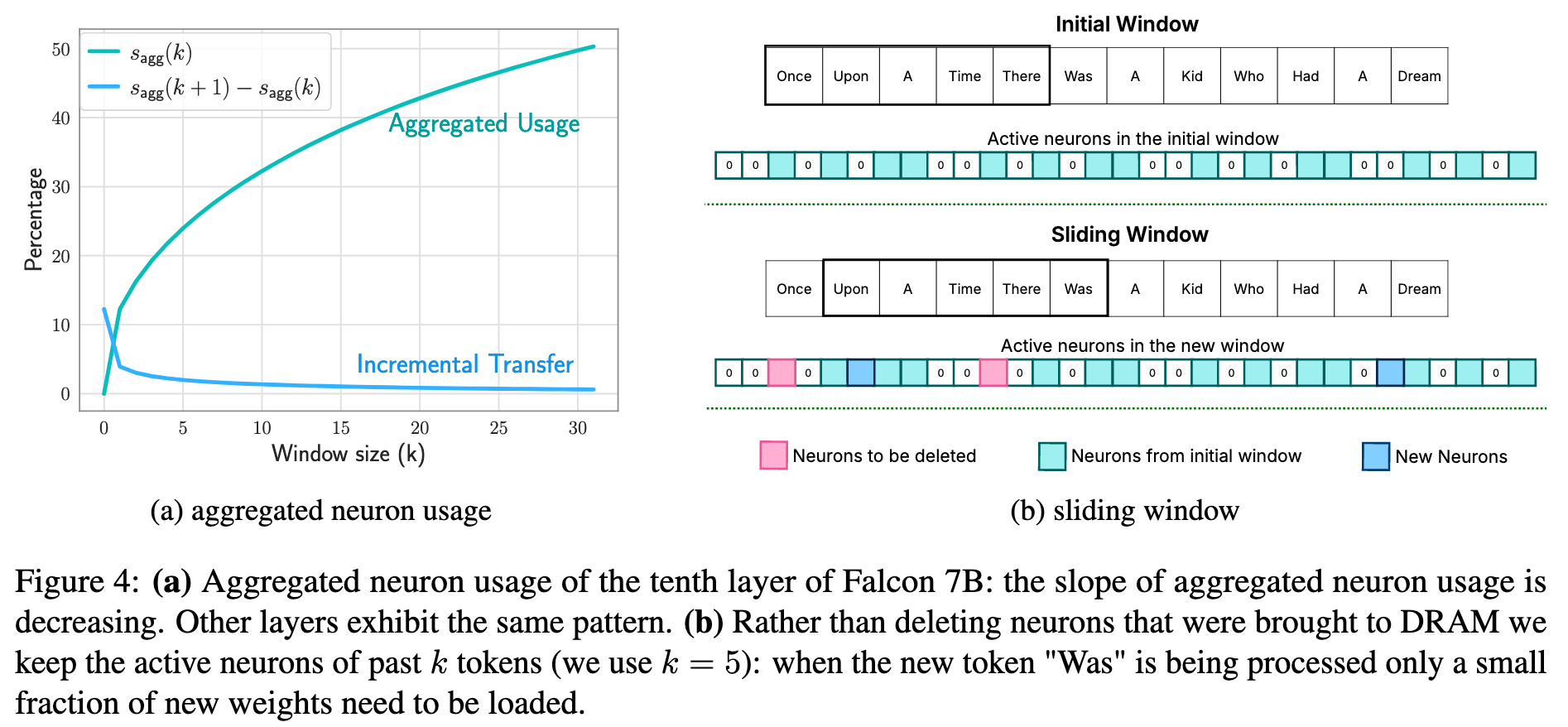
Increasing Transfer Throughput
在 FFN 计算过程中,W_up 的第 $i$ 行和 W_down 的第 $j$ 列是绑定的,要么都需要被加载,要么就都不加载,所以可以在存储时将这两个矩阵放在一起,实现一次读取操作就能读取 W_up 中的一行以及对应的 W_down 中的一列。
详细原理可以看这里。
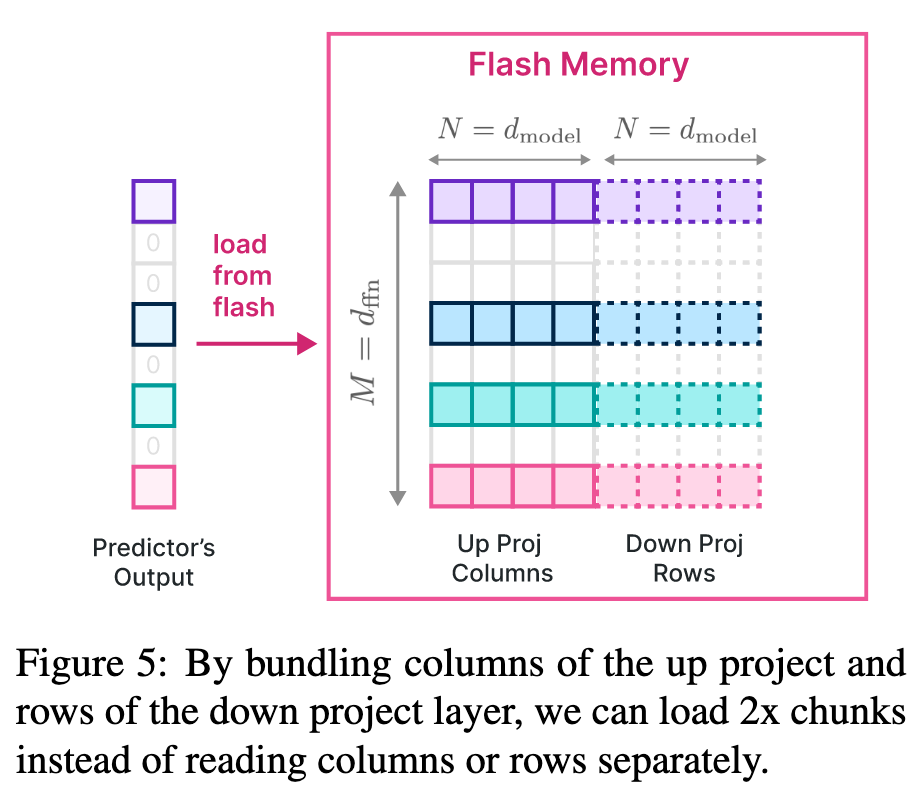
LLM-Flash 也发现了共激活的 power low distribution,但是没利用。
Optimized Data Management in DRAM
为了避免在DRAM中频繁地重新分配内存和复制数据,论文采用了一种优化的内存管理策略。系统会预先分配一块足够大的内存区域,并使用一个包含指针、矩阵、偏置等元素的数据结构来高效地管理神经元的删除和插入操作。
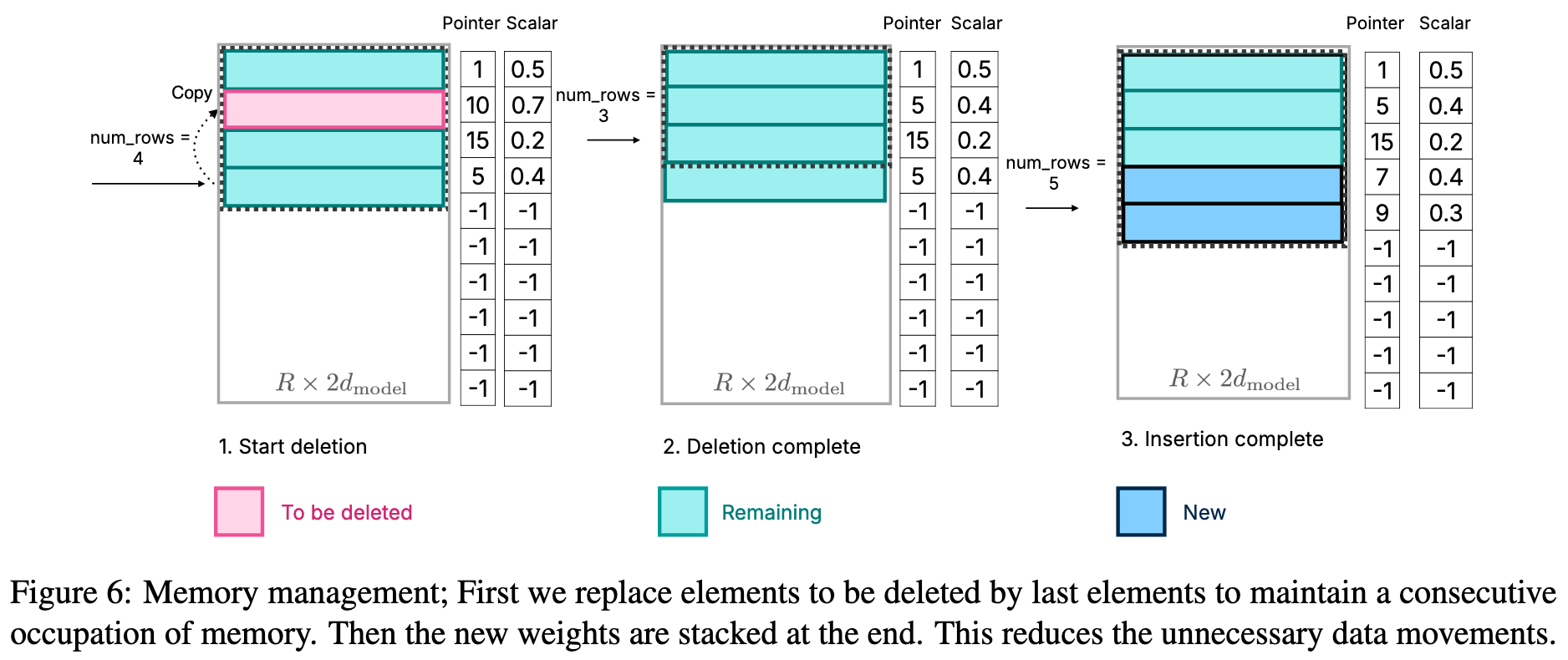
简单分析一下,应该是每个 FFN 都有一个这样对应的 matrix wrapper, 方便和滑动窗口技术做联动,而且只需要保证 W_up 列与 W_down 行的对应关系,乱序加载和乱序计算都不会影响最后的输出结果。
Evaluation

消融实验:
- Hybrid loading approach: 模型一半在内存,一半在闪存,I/O 延迟下降了一半
- Predictor: 大幅减少了从闪存传输到 DRAM 的数据量,从而降低了延迟
- Windowing: 进一步降低从闪存到 DRAM 的数据量(0.9GB -> 0.2GB),降低了时延 (738ms -> 164ms),两者比例完全吻合,说明时延降低完全是由传输的数据量减少带来的
- Bundling: 每次读取的数据块大小翻倍,延迟了下降了一半
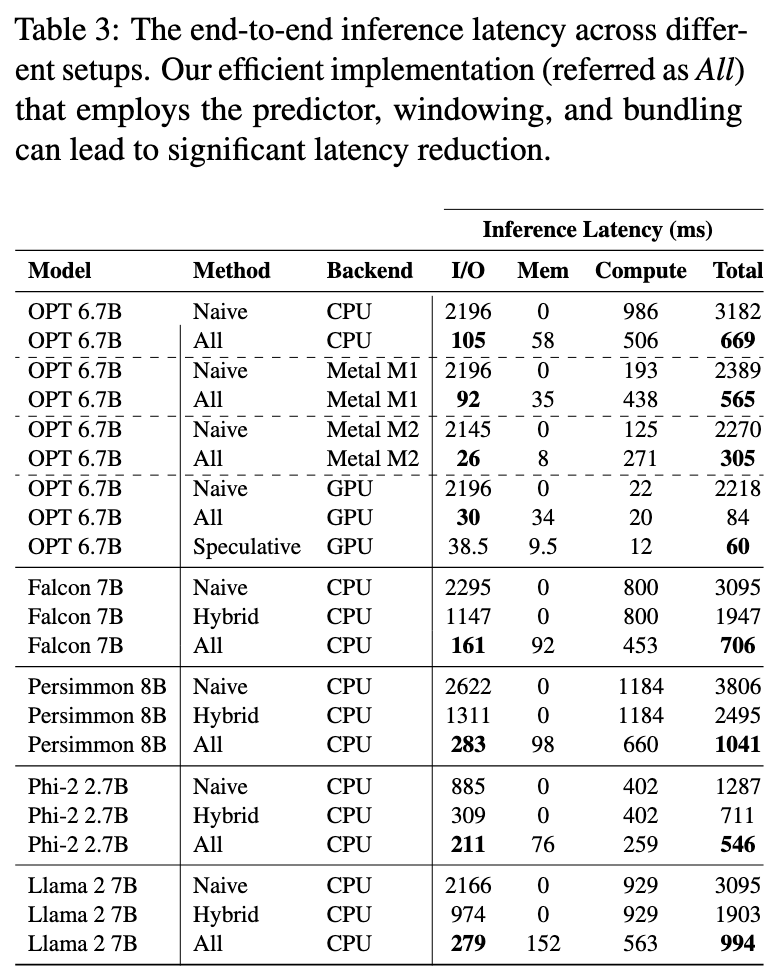
Table3 展示了端到端的延迟:
Thoughts
When Reading
闪存是构成 SSD 的核心且最基本的存储单元,但 SSD 远不止是闪存的简单堆叠。
之前看综述时忽略了 Sparsification 这项技术,现在看来在端侧进行推理,这项技术十分重要,效果太好了,降低计算量和 I/O 传输量,同时对模型生成质量降低幅度极为有限,应该像 Quantization 一样推广普及。
或者各个厂商在训练时,就应该附带 predictors,让各个推理框架直接调用,效果肯定比各家自己通过有限的语料单独训练要好。
embedding layer 和 attention 这部分参数量比较小,可以直接保存在内存中。
这篇文章也发现了神经元激活的 power law distribution,很疑惑为什么没采用 cache 等方式来降低重复读取的开销。
Related Works
- Relu strikes back: Exploiting activation sparsity in large language models
- Deja Vu Contextual Sparsity for Efficient LLMs at Inference Time