Extensive Reading
Author Info
- About | Edward Hu: Edward Hu is a founding partner in a stealth AI company in Woodside, CA. He was a researcher at OpenAI and received his research training as a Ph.D. student advised by Yoshua Bengio, a recipient of the 2018 A.M. Turing Award. Before graduate school, Edward was a researcher at Microsoft, where he invented LoRA and μTransfer.
- Yelong Shen - Microsoft | AMiner
Background
The dominant paradigm in modern NLP is
transfer learning: a large-scale model is first pre-trained on general domain data and then adapted to specific downstream tasks. Two primary strategies have emerged for this adaptation phase:
Full Fine-Tuning: This is the most straightforward approach, where all parameters of the pre-trained model are updated during training on the new task-specific dataset.
Parameter-Efficient Fine-Tuning (PEFT): As an alternative to updating all weights, various PEFT methods were developed to reduce computational and storage costs. The most prominent strategies include:
- Adapter-based Tuning: This method involves inserting small, trainable neural modules between the layers of the frozen pre-trained model. Only these lightweight adapters are trained for the new task.
- Prompt-based Tuning: This family of methods focuses on optimizing parts of the input layer activations. Instead of modifying the model’s weights, it learns continuous task-specific vectors (or “soft prompts”) that are prepended to the input sequence.
Challenges
Prohibitive Cost of Full Fine-Tuning: Fine-tuning large language models (LLMs) for every downstream task is operationally infeasible. It requires storing and deploying a complete, multi-billion parameter copy of the model for each specific task, leading to massive storage and serving costs.
Critical Drawbacks of Existing Efficient Methods:
- Inference Latency: Methods like Adapters add extra layers to the model architecture. This introduces sequential computations that increase inference latency, which is unacceptable for many real-time applications.
- Reduced Context Length: Prompt-tuning methods (like prefix-tuning) reserve a part of the input sequence for trainable parameters. This necessarily shortens the effective context window available for processing task-specific data.
- Performance vs. Efficiency Trade-off: These existing techniques often fail to match the performance of a fully fine-tuned model, forcing a compromise between computational efficiency and model quality.
Insights
“The pre-trained language models have a low “instrisic dimension” and can still learn efficiently despite a random projection to a smaller subspace.”
一个拥有数十亿甚至上千亿参数的语言模型,其所有参数的可能组合构成了一个极其巨大的、高维度的“参数空间”。然而,在这个浩瀚的空间中,能够让模型表现良好(例如,生成通顺、有意义的文本)的那些有效的参数组合,其实只占据了一个非常小的、结构化的子空间。
可以用一个比喻来理解:
想象一个巨大的三维仓库。这个仓库代表了模型所有参数的所有可能取值,维度极高(数十亿维),在这个空旷的仓库里,漂浮着一张巨大的、但非常薄的纸。这张纸代表了所有能让模型“正常工作”的有效参数组合。
虽然这张纸存在于一个三维空间(外在维度)中,但要描述纸上任意一个点的位置,你只需要两个坐标(例如,在纸上的长和宽)。所以,这张纸的“内在维度”是二维的。
同理,尽管模型的参数总数(外在维度)非常庞大,但能够描述所有有效模型配置所需的“本质”变量数量(内在维度)却相对少得多 。
“The updates to the weights also have a low “intrinsic rank” during adaptation.”
在模型为适应新任务而进行微调时,其权重的变化量 (ΔW) 也具有‘低内在秩’ (low intrinsic rank) 的特性。
Approaches
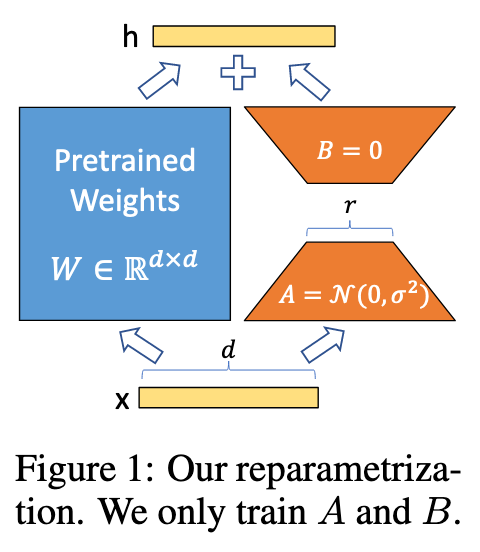 将一个模型的权重矩阵分为两部分:
将一个模型的权重矩阵分为两部分:
- $W_0(d \times k)$
- $\Delta W(d \times k)$
- $\Delta W(d \times k)$ 由 $B(d \times r), A(r \times k)$ 组成
最终的 forward pass 可以表示为
$$h = W_0x + \Delta W x = W_0x + BAx$$训练时冻结 $W_0$,只训练 $A$ 和 $B$,由于 $r « \text{min}(d,k)$, 所以使用 LoRA 进行训练时的参数相比于原模型来说小得多。
- A Generalization of Full Fine-tuning
- 阐述了 LoRA 的通用性和理论上限
- LoRA 不认为满秩的调整是必要的,但如果把秩 $r$ 设置得非常大,LoRA 就拥有了与全量微调几乎同等的“自由度”或“表达能力”,理论上可以复现全量微调能达到的任何效果。
- No Additional Inference Latency
- 可以将训练好的 $BA$ 与 $W_0$ 相加再进行推理,不会带来任何的额外开销。
- 也可以从 $W$ 中减去 $BA$ 来得到原始的 $W_0$
LoRA 这种"可插拨"的特性使其非常适合于将一个预训练模型适配到多个不同的下游任务中:
- 只需要切换不同的 LoRA module,就能适配到不同的下游任务,而且这些 module 的参数量都非常小
- 也可以进行在线的任务切换,在生产环境中动态地切换 LoRA module
虽然论文中只提到了将 LoRA 应用到了 transformer 以及变体中,但这种微调方法其实对其他类型的模型也适用。
Specifically, when apply LoRA to transformers, the paper only adapts the attention weights for downstream tasks and freezes the MLP modules (so they are not trained in downstream tasks).
Evaluation
性能对比实验的结果不用多说,总结起来就是:参数量少,效果好
机制探索实验还比较有意思,回答了下面几个问题:
应该对哪些权重矩阵应用 LoRA?
- 实验在 GPT-3 上进行,固定可训练参数总数(约18M),对比了对不同注意力权重(Wq,Wk,Wv,Wo)应用 LoRA 的效果。
- 结论:同时对 查询矩阵 (Wq) 和值矩阵 (Wv) 应用 LoRA 的效果最好 。这表明,与其用较大的秩
r去更新单一类型的权重,不如用较小的秩去更新多种类型的权重。
LoRA 的最佳秩 r 是多少?
- 实验表明,一个极小的秩
r就足以获得非常有竞争力的结果。在 GPT-3 的多个任务上,r=1或r=2时的性能就已经非常接近最佳性能。 - 强有力地证明了论文的核心假设——模型微调所需的权重更新矩阵 ΔW 确实具有极低的“内在秩”。
通过对比不同 r 值学习到的子空间,发现高秩 (r=64) 和低秩 (r=8) 的 LoRA 模块学习到的最重要的方向(对应最大奇异值的方向)是高度重合的,而其他方向可能是训练中积累的噪声 。
权重更新 ΔW 和原始权重 W 是什么关系?
实验通过投影分析发现,LoRA 学习到的变化量 ΔW 与原始权重 W 并非毫无关系,但也不是简单地加强 W 中已有的最强方向。
结论:ΔW 倾向于放大那些在通用预训练模型 W 中存在但未被强调、却对特定下游任务至关重要的特征方向 。这种放大的倍数可能非常大(例如,当 r=4 时,放大因子约为 21.5)。