Background
Current serving system schedules the execution of the engine at the granularity of request. Under this design, when the serving system dispatches a batch of requests to the engine, the engine returns inference results for the entire batch at once after processing all requests within the batch.
Challenge 1: Early-finished and late-joining requests
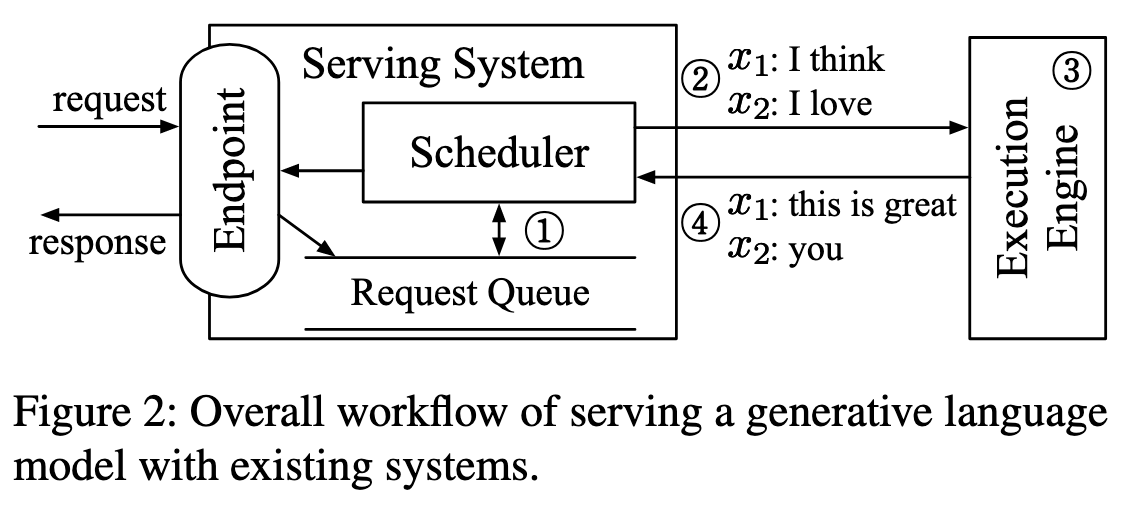
Requests can’t be early finished As different client requests may require different numbers of iterations for processing, requests that have finished earlier than others in the batch cannot return to the client, resulting in an increased latency.
Requests can’t be late-joined Requests arrived after dispatching the batch also should wait for processing the batch, which can significantly increase the requests’ queueing time.
Solution 1: Iteration-level scheduling
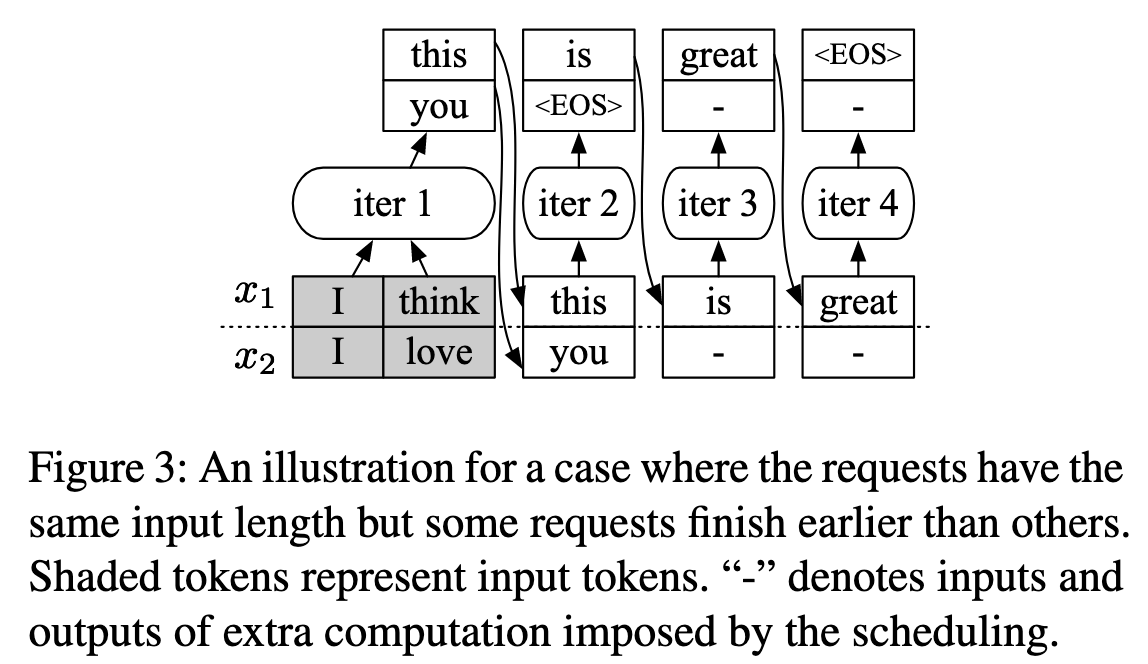
Shaded tokens represent input tokens received from the clients, while unshaded tokens are generated by ORCA.
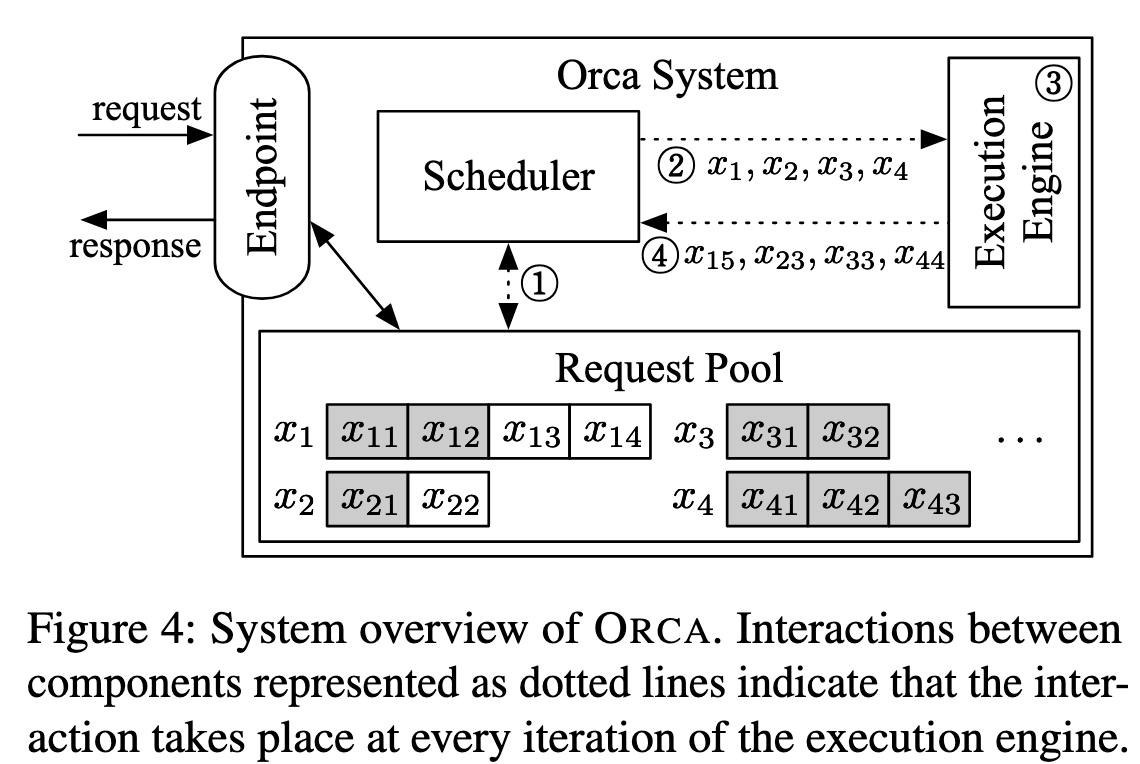
ORCA schedules executions at the granularity of iteration.
At high level, the scheduler repeats the following procedure:
- selects requests to run next
- invokes the engine to execute one iteration for the selected requests
- receives execution results for the scheduled iteration
- For early finished requests
- The scheduler can detect the completion of a request and immediately return its generated tokens to the client
- For newly arrived requests
- The request gets a chance to start processing after execution of the currently scheduled iteration
Challenge 2: Batching an arbitrary set of requests
To achieve high efficiency, the execution engine should be able to process any selected set of requests in the batched manner.
Without batching, one would have to process each selected request one by one, losing out on the massively parallel computation capabilities of GPUs.
There are three cases for a pair of requests where the next iteration cannot be batched together:
- both requests are in the initiation phase and each has different number of input tokens (e.g., x3 and x4 in Figure 4)
- both are in the increment phase and each is processing a token at different index from each other (x1 and x2)
- each request is in the different phase: initiation or increment (x1 and x3)
可以将上面三种情况分一下类:
| 情况 1 & 2 | 情况 3 | |
|---|---|---|
| 问题描述 | 同一阶段,但序列长度不同 | 不同阶段 (Initiation vs. Increment) |
| 问题本质 | 数据长度不一致 | 计算模式不一致 (L_q 不同) |
| Padding 能否解决? | 可以 (但效率极低) | 不可以 (逻辑上无法统一) |
| 问题定性 | 性能问题 | 结构性/逻辑性问题 |
对于情况 3,其实是计算模式的根本性不一致。我们再次关注注意力计算的核心:attn_scores = query @ key.T。
- 请求A (Initiation Phase):
- 目标: 计算输入的
L_A个词元内部两两之间的关系。 - 计算模式:
query长度L_q是L_A,key长度L_k也是L_A。需要计算一个L_A x L_A的注意力矩阵。
- 目标: 计算输入的
- 请求B (Increment Phase):
- 目标: 计算1个新词元与过去
L_B个历史词元的关系。 - 计算模式:
query长度L_q是 1,key长度L_k是L_B。需要计算一个1 x L_B的注意力向量。
- 目标: 计算1个新词元与过去
这里的核心冲突是 query 的长度 L_q 不同。
- 请求A有
L_A个“提问者”(queries)。 - 请求B只有
1个“提问者”(query)。
你无法通过 Padding 来统一 query 的数量。给请求B补齐 query 是没有意义的,因为它只有一个“思考焦点”。一个批次的矩阵乘法无法做到:对批次中的第一个元素计算一个 L_A x L_A 的结果,同时对第二个元素计算一个 1 x L_B 的结果。
Solution 2: Selective Batching
Instead of processing a batch of requests by “batchifying” all tensor operations composing the model, this technique selectively apply batching only to a handful of operations.
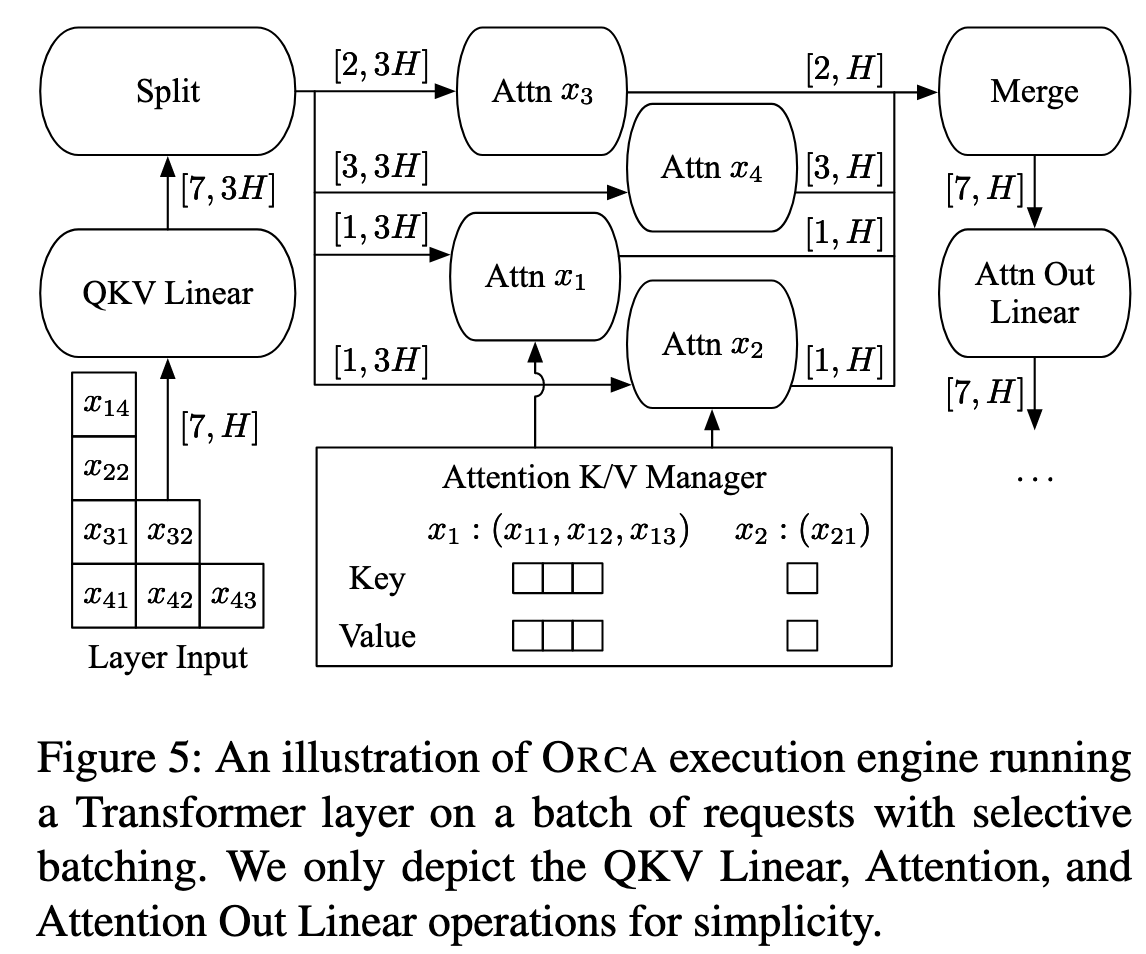
Core insight:
- Operations such as non-Attention matrix multiplication and layer normalization can be made to work with irregularly shaped tensors by flattening the tensors.
- The Attention operation requires a notion of requests (i.e., requires the batch dimension) to compute attention only between the tokens of the same request, typically done by applying cuBLAS routines for batch matrix multiplication.
Selective batching: it splits the batch and processes each request individually for the Attention operation while applying token-wise (instead of request-wise) batching to other operations without the notion of requests.
To make the requests in the increment phase can use the Attention keys and values for the tokens processed in previous iterations, ORCA maintains the generated keys and values in the Attention K/V manager.
Design
Distributed Architecture
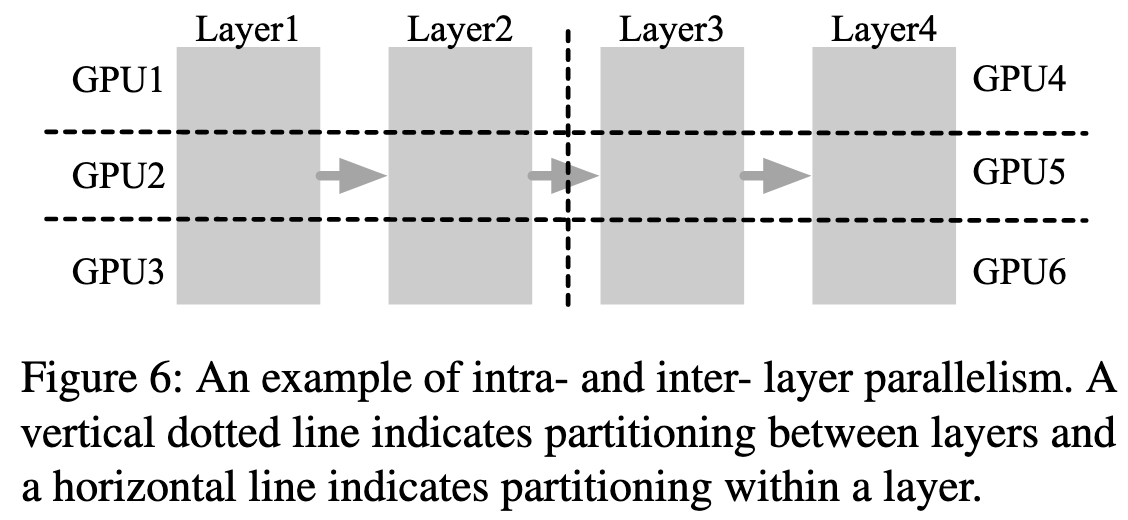
为了支持单 GPU 无法容纳的大模型,ORCA 的执行引擎采用了两种成熟的并行化技术 :
- 层内并行 (Intra-layer parallelism): 将模型单层内的矩阵乘法(如
Linear和Attention操作)及其参数切分到多个GPU上执行 。 - 层间并行 (Inter-layer parallelism): 将模型的不同 Transformer 层垂直切分到不同的GPU组(即 Workers)上,形成流水线 。
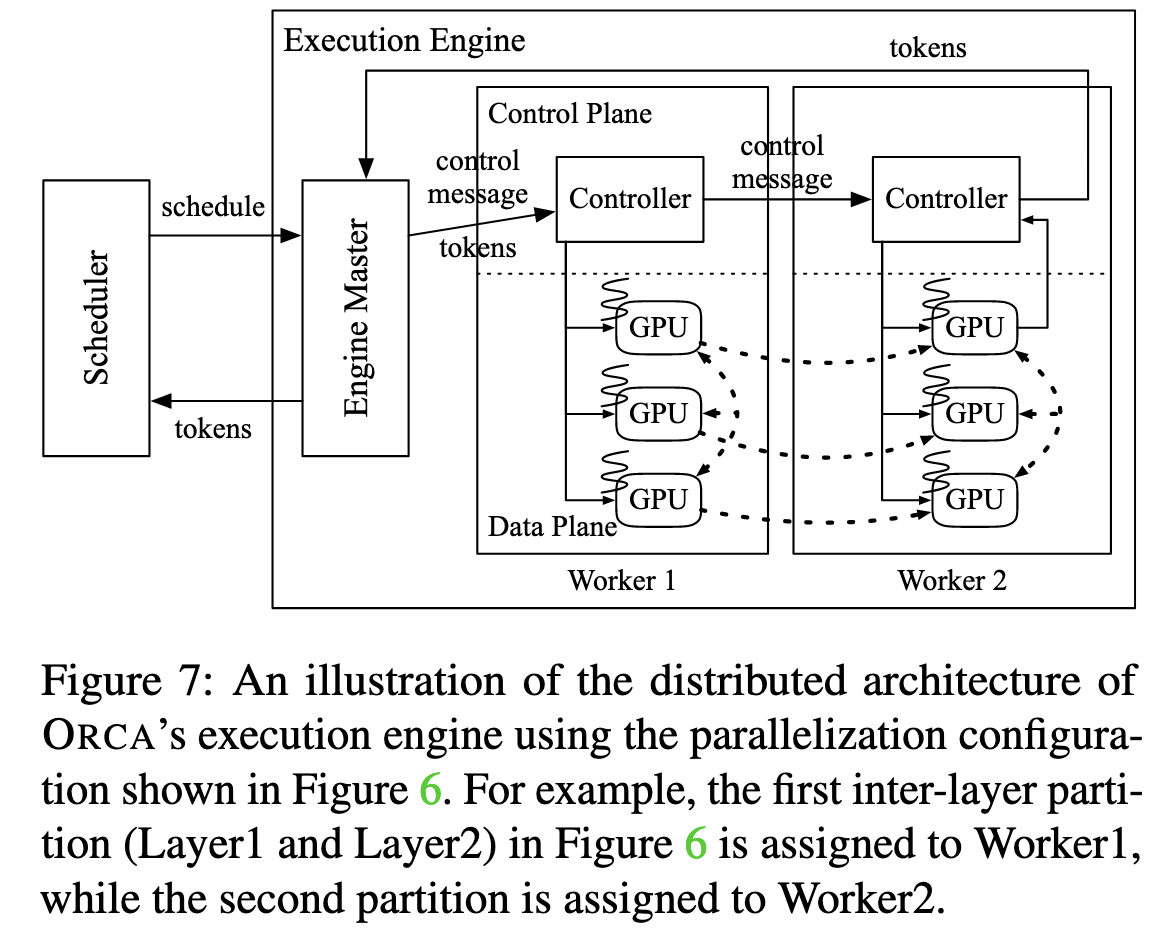
Components:
- Engine Master: Receives commands from a scheduler and forwards batch info to the first pipeline stage (Worker).
- Worker: Each worker manages a model partition (a pipeline stage) across multiple GPUs.
- Controller: An internal component of a Worker that dispatches tasks to its GPUs and forwards control messages.
Execution Flow:
- Initiation: The Engine Master sends batch info (tokens & metadata) to the first worker (Worker 1).
- Pipelined Forwarding: Worker 1’s Controller dispatches tasks to its local GPUs and immediately forwards the control message to the next worker (Worker 2) without waiting for its local computation to complete.
- Synchronization Point: Only the last worker in the pipeline waits for its GPU computations to finish before returning the output tokens to the Engine Master.
Key Optimization: Control-Data Plane Separation
- Problem: Traditional systems (e.g., Faster Transformer) use NCCL for all communication, including small control messages, causing unnecessary CPU-GPU synchronization overhead.
- ORCA’s Solution:
- Control Plane: Small control messages (metadata) are sent via standard CPU-based networking (e.g., gRPC).
- Data Plane: Large intermediate tensors (activations) are transferred between GPUs using NCCL.
- Benefit: This separation minimizes sync overhead and improves distributed efficiency.
Scheduling Algorithm
The scheduler re-evaluates batches every iteration based on these principles:
- Fairness (Iteration-Level FCFS): Prioritizes requests that arrived earlier. If request A arrived before B, A’s executed iteration count will always be ≥ B’s.
- Throughput/Latency Trade-off (max_batch_size): Uses a configurable max_bs to maximize throughput within a given latency budget.
- KV Cache-Aware Memory Management:
- Constraint: Limited GPU memory for the KV cache is a key bottleneck.
- Solution: To prevent deadlocks, the scheduler pre-allocates the full KV cache space a new request might need (based on its max_tokens) before scheduling it. A request is only added if this reservation succeeds.
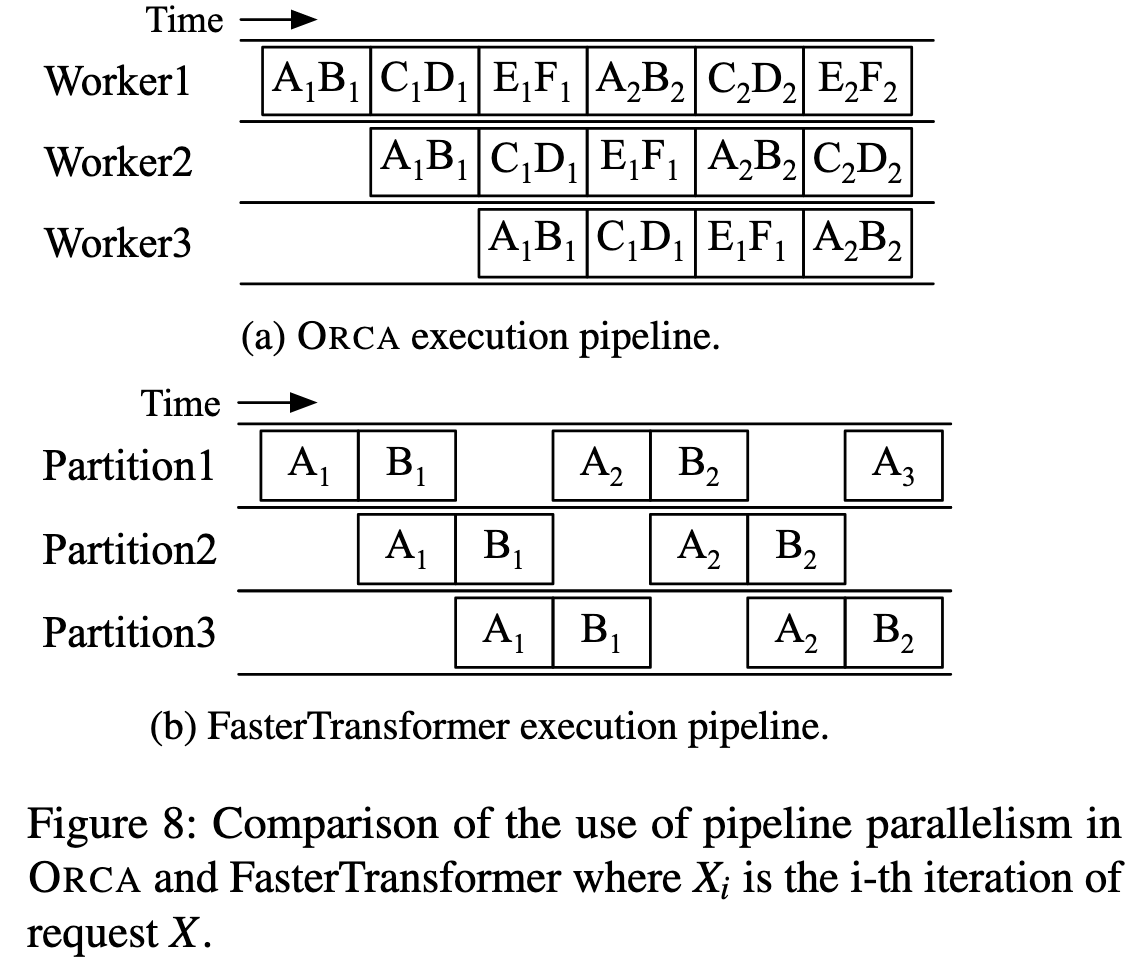
- Pipeline Parallelism (Keeping the Pipeline Full):
- Mechanism: The scheduler keeps injecting batches until the number of in-flight batches equals the number of workers (n_scheduled = n_workers).
- Benefit: This ensures all workers are always busy, eliminating pipeline “bubbles” (idle stages) and maximizing hardware utilization.
- Advantage: More efficient than Faster Transformer’s microbatching, as it avoids the trade-off between batch efficiency and pipeline efficiency.